
Dans la première partie de ce tutoriel d’initiation à l’intelligence artificielle nous avons installé Anaconda et codé nos premières lignes de Python. Dans la deuxième partie, nous avons appris à commencer à manipuler les données avec Pandas. Nous allons aller maintenant un peu plus loin dans l’analyse de données et apprendre à tracer de jolis graphiques !
Créez un nouveau carnet de notes Jupyterlab et chargez à l’aide de pandas le fichier CSV movies.csv.csv que nous avons téléchargé précédemment et qui contient une liste de films accompagnés de leurs notes. Stockez la DataFrame dans une variable appelée films tout comme nous l’avions fait dans la deuxième partie. N’hésitez pas à vous référer au précédent notebook si vous avez oublié comment procéder.
Allons un tout petit peu plus loin dans l’analyse des données, notamment avec la fonction groupby :
La fonction groupby:
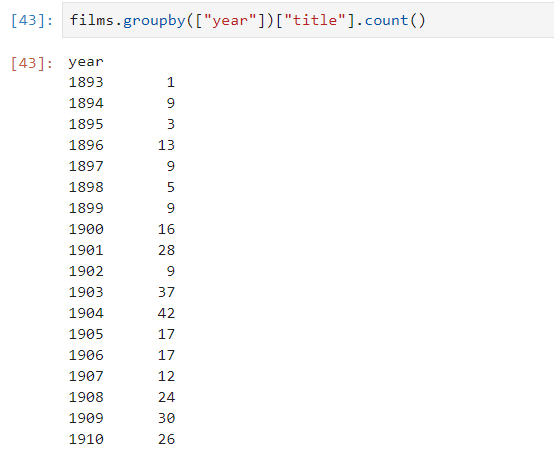
Cette fonction permet de regrouper les données en fonction d’une ou plusieurs colonnes. Cet outil est très puissant. Par exemple, en le chaînant avec la fonction count() permettant de compter le nombre de lignes, il permet de trouver instantanément le nombre de films recensés par année :
[cc lang=”python”]films.groupby([“year”])[“title”].count()[/cc]
Nous pouvons également obtenir la durée moyenne des films par année :
[cc lang=”python”]films.groupby([“year”])[“length”].mean()[/cc]
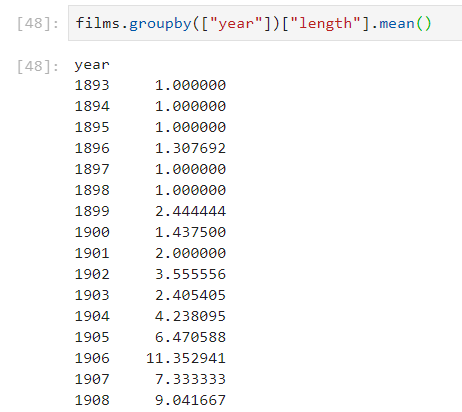
Ce type d’information peut être très intéressant, mais le résultat est très difficilement interprétable, il est heureusement très facile de réaliser des graphiques, grâce au module matplotlib.
Tracer des graphiques avec Matplotlib :
Il faut tout d’abord importer le module :
[cc lang=”python”]import matplotlib.pyplot as plt[/cc]
Nous pouvons maintenant tracer des graphiques en toute simplicité grâce à la fonction plot() qui s’appuiera sur le module matplotlib pour tracer les graphiques :
[cc lang=”python”]films.groupby([“year”])[“length”].mean().plot()[/cc]
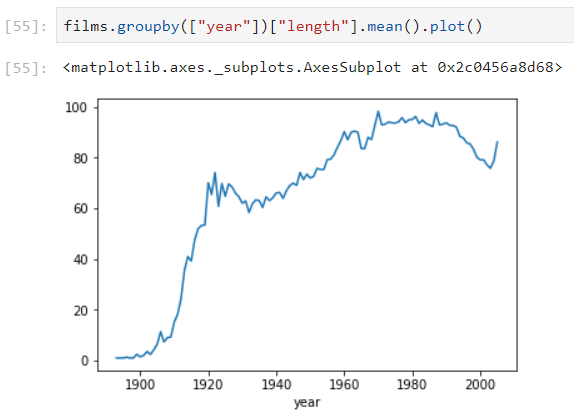
En visualisant cette courbe, il est beaucoup plus facile de constater l’évolution de la durée moyenne des films au fil des années n’est-ce pas ? Nous pouvons voir que si la durée des films n’évolue pas de façon linéaire, elle a globalement augmenté au fil des années, bien qu’elle ait notablement diminué entre la fin des années 90 et le début des années 2000.
Encore une fois, amusez-vous à manipuler les données et tracer différentes courbes.
La fonction corr() de pandas
La fonction corr() permet d’obtenir un coefficient de corrélation. Ce coefficient mesure la liaison entre différentes caractéristiques. Cela nous permet de confirmer ce que nous avons pu repérer visuellement :
[cc lang=”python”]films[[“year”,”length”]].corr()[/cc]
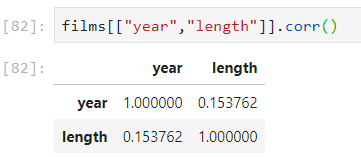
Nous affichons ici la corrélation entre l’année et la durée. Une corrélation maximale est égale à 1 et une corrélation minimale est égale à -1 (cela signifie que l’une des caractéristiques évolue inversement à l’autre caractéristique).
La matrice affichée présente les deux caractéristiques que nous avons sélectionnées. Nous pouvons voir que la cellule à l’intersection entre la ligne “year” et la colonne “year” est égale à 1, tout comme la cellule à l’intersection entre la ligne “length” et la colonne “length”. C’est tout à fait normal, puisque ces lignes et colonnes représentent les mêmes informations, la corrélation d’une caractéristique avec elle même est toujours égale à 1. Ce qui est intéressant, c’est la corrélation entre la caractéristique “year” et la caractéristique “length”. Celle-ci est positive et non négligeable. C’est ce que nous avions pressenti en constant sur la courbe que la durée a globalement progressé au fil des années.
Tracer plusieurs courbes
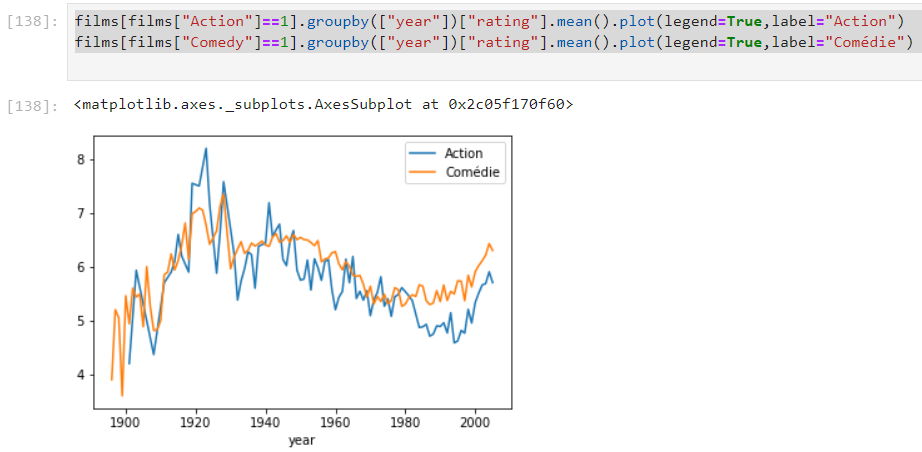
Il est possible de tracer plusieurs courbes dans un même graphique, nous pouvons par exemple comparer la note moyenne des films d’action et comiques :
[cc lang=”python”]
films[films[“Action”]==1].groupby([“year”])[“rating”].mean().plot(legend=True,label=”Action”)
films[films[“Comedy”]==1].groupby([“year”])[“rating”].mean().plot(legend=True,label=”Comédie”)
[/cc]
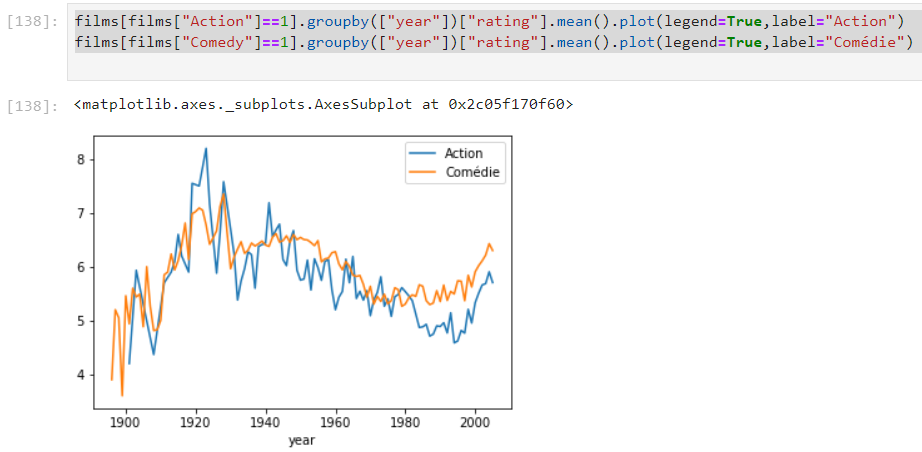
La fonction plot() accepte différents options de configuration, que l’on passe en argument de la fonction (entre les parenthèses). Nous avons passé les arguments legend et label afin d’ordonner l’affichage des légendes et préciser les labels à afficher. La fonction plot(), tout comme la plupart des autres fonctions vues au cours de ce tutoriel accepte d’autres arguments. Nous vous invitons à consulter la documentation officielle de Pandas pour en savoir plus.
Nous constatons que les courbes évoluent de façon relativement similaire, même si la note moyenne des films d’action est plus saccadée et globalement inférieure.
A ce stade, une seule règle d’or : Expérimentez !
Vous l’aurez peut être remarqué, JupyterLab propose une autocomplétion, à titre d’exemple, si vous saisissez films. puis appuyez sur la touche tab, vous verrez les différentes fonctions que vous pouvez utiliser. La plupart d’entre-elles portent des noms suffisamment évocateurs pour comprendre leur utilité, mais n’hésitez pas à consulter la documentation.
L’analyse que nous venons de faire est relativement simple et naïve, mais le but de cette initiation est de vous familiariser de façon ludique avec l’intelligence artificielle en partant de zéro.
Vous vous demanderez sans doute où est l’intelligence artificielle dans tout ça ? Un projet d’intelligence artificielle débute dès la sélection des données. Une fois les données collectées, il faut ensuite les comprendre pour pouvoir les exploiter. C’est la raison pour laquelle une phase d’analyse des données est toujours indispensable. C’est d’ailleurs bien souvent à cette étape que se joue la réussite du projet.
Nous aborderons très bientôt ce que vous considérerez probablement comme de l’intelligence artificielle à proprement parler.
N’hésitez pas à nous suivre via Twitter, Facebook ou notre Newsletter afin d’être notifié lors de la publication de la seconde partie de ce tutoriel.
Vous appréciez notre initiative ? Merci de partager cette page sur Facebook et Twitter.