
Dans ce tutoriel, nous allons nous initier à Python, Pandas et Matplotlib en manipulant des données CSV. Nous partons du principe qu’Anaconda est installé et que vous savez comment créer un Notebook. Dans le cas contraire, nous vous invitons à lire toute d’abord la première partie.
Créons un nouveau notebook afin de suivre la deuxième partie de ce tutoriel.
Pandas est un module python. Un module permet d’étendre le langage en ajoutant des fonctionnalités qui ne sont pas présentes dans le langage par défaut. Pandas permet de manipuler en toute simplicité des données, y compris celles au format csv.
Commençons donc par importer pandas :
[cc lang=”python”]import pandas[/cc]
![]()
Nous pouvons maintenant invoquer des fonctions propres à notre module (Nous ferons volontairement le choix d’employer le terme fonction indistincement, qu’il s’agisse d’un fonction ou d’une méthode, tout au long de ce tutoriel afin que celui-ci soit le plus clair possible pour un plus grand nombre. Nous prions les puristes de ne pas nous en tenir rigueur) en inscrivant pandas. suivi du nom de la fonction. Nous allons commencer par voir comment ouvrir un fichier.
Ouverture d’un fichier CSV
Le jeu de données (dataset) que nous allons manipuler est un fichier CSV concernant des films.
Un fichier csv est un simple fichier texte structuré grâce à des délimitateurs de colonne, permettant de stocker des informations tabulaires. Le format est très populaire car simple et universel (il peut notamment être ouvert depuis Excel, mais également la plupart des langages de programmation).
Téléchargeons le donc (en cliquant sur le lien avec le bouton droit puis “enregistrer sous..”) et décompressons le dans le dossier de notre nouveau notebook.

Grâce à Pandas, une ligne suffit à importer le fichier de façon à pouvoir le manipuler :
[cc lang=”python”]pandas.read_csv(“movies.csv.csv”)[/cc]

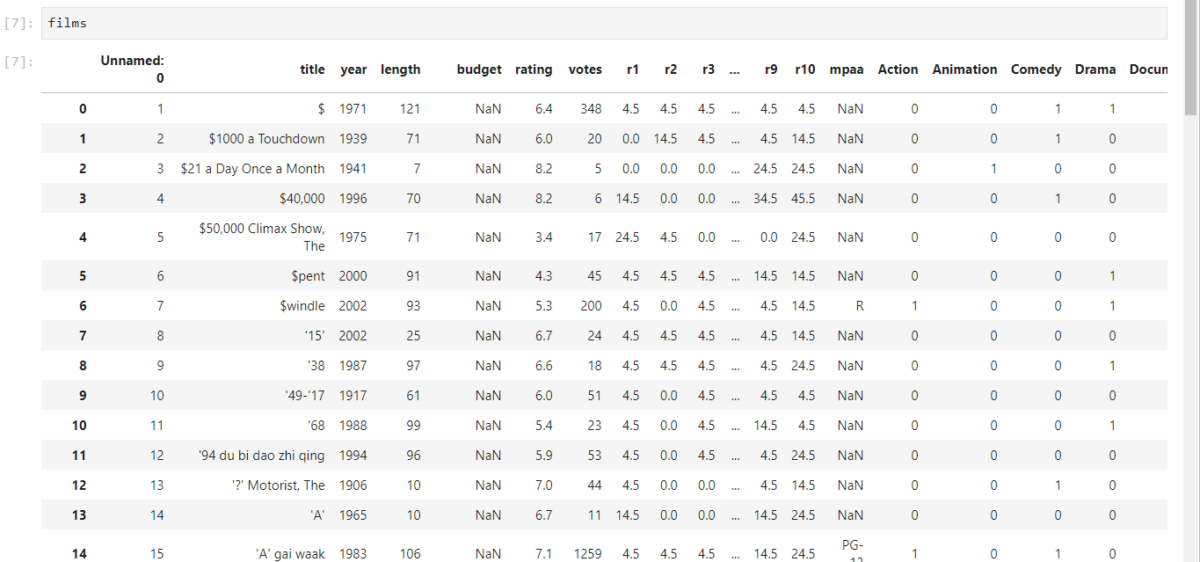
Comme nous pouvons le voir, le fichier csv contient les colonnes suivantes :
Unnamed :Colonne sans nom (correspondant à un numéro identifiant le film, nous ne l’utiliserons pas).
title : il s’agit du titre du film
year : année de réalisation du film
length : durée du film, en minutes
budget : budget du film (NaN si non connu)
rating : note du film
votes : nombre de votes
r1 : % de note reçues égales à 1/10
r2 : % de note reçues égales à 2/10
r3 : % de note reçues égales à 3/10
r4 : % de note reçues égales à 4/10
r5 : % de note reçues égales à 5/10
r6 : % de note reçues égales à 6/10
r7 : % de note reçues égales à 7/10
r8 : % de note reçues égales à 8/10
r9 : % de note reçues égales à 9/10
r10 : % de note reçues égales à 10/10
mpaa : classification du film (tous publics, PG-13 ..)
Genres : une colonne par genre, contenant la valeur 0 si ce film n’est pas classé dans le genre correspondant, 1 s’il est classé dans le genre. Un film peut être classé dans différents genres.
Que pouvons-nous envisager de tirer d’un tel fichier en machine learning ? Imaginons que vous souhaitiez vous lancer dans l’industrie du cinéma et que vous cherchiez à trouver la formule idéale pour produire le prochain blockbuster. Nous pourrons mettre au point un modèle tentant de prédire le succès d’un film en fonction du budget qui lui est consacré, ou mieux, en fonction du budget et de son genre, puisqu’il y a fort à parier qu’un documentaire n’ait pas forcément besoin du même budget qu’un film d’action pour obtenir les faveurs du public. L’année n’est-elle pas également importante ? Les budgets sont à remettre en perspective avec l’année de réalisation, et puis, les goûts du public évoluent certainement ? Risque-t-on d’ennuyer le public avec un film trop long, ou au contraire de le laisser sur sa fin avec un film trop court ? Nous verrons que ce fichier pourra être riche d’enseignements ! Bien sûr, il serait possible d’aller encore plus loin en enrichissant le fichier avec des éléments d’intrigue du scénario du film. Vous mettrez alors toutes les chances de votre côté pour susciter l’intérêt du public.
La commande [cc lang=”python”]pandas.read_csv(“movies.csv.csv”)[/cc] que nous avons saisie a traité le fichier csv afin de le convertir en DataFrame, un tableau à 2 dimensions, et l’a affiché.
C’est utile, mais plutôt que d’afficher le résultat du traitement, il est préférable de le stocker dans une variable, afin de pouvoir le réutiliser et le manipuler. Nous allons donc modifier la ligne de code précédemment saisie et inscrire :
[cc lang=”python”]films=pandas.read_csv(“movies.csv.csv”)[/cc]

Comme nous le voyons, il est toujours possible d’afficher notre DataFrame, en saisissant simplement sur la ligne suivante le nom de la variable que nous venons de créer :
Manipulations courantes avec pandas
Quelques exemples de commandes utiles :
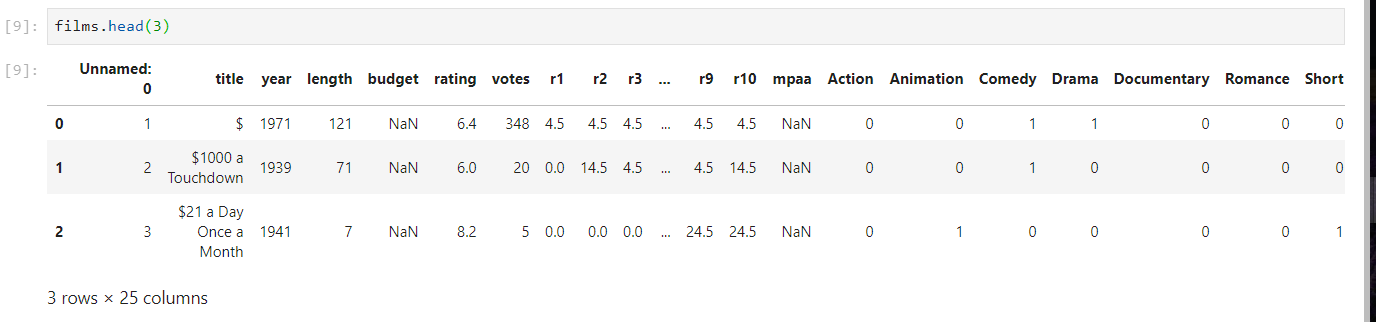
Affichage des 3 premières lignes du tableau :
[cc lang=”python”]films.head(3)[/cc]
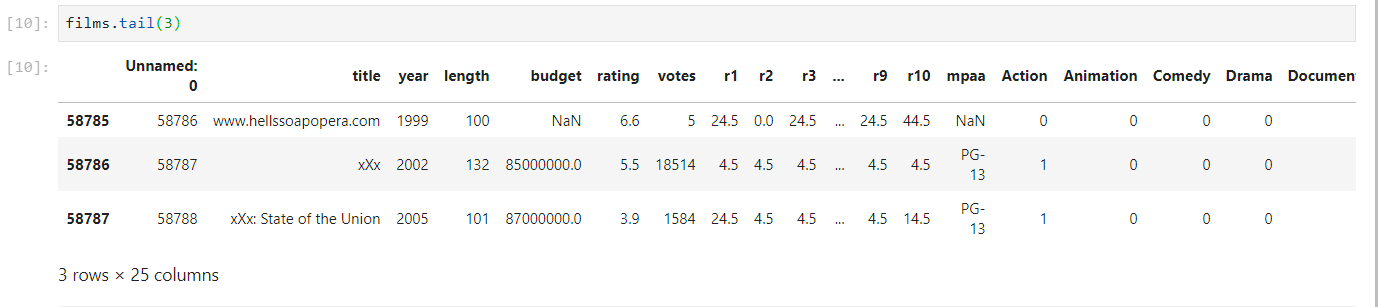
Affichage des 3 dernières lignes du tableau :
[cc lang=”python”]films.tail(3)[/cc]
Conserver une portion précise (lignes)
[cc lang=”python”]films[1:4][/cc]

Dans cet exemple, nous conservons les index 1 à 3. Attention. Les index sont les nombres affichés en gras à gauche du tableau. Ils débutent par 0. D’autre part, la notation de la sélection peut être déroutante : le premier chiffre correspond à la première ligne que nous souhaitons conserver, tandis que le deuxièm chiffre correspond à la première ligne que nous ne souhaitons pas conserver. En indiquant films[1:4] nous affichons donc les lignes dont les index vont de 1 à 3.
Ne conserver que certaines colonnes
[cc lang=”python”]films[[“year”,”rating”]][/cc]

Dans cet exemple nous ne conservons que les colonnes year et rating.
Trier les données
[cc lang=”python”]films.sort_values(by=”year”,ascending=True)[/cc]

La fonction sort_values permet de trier notre DataFrame selon la colonne de notre choix et dans le sens de notre choix (par défaut le tri se fait dans le sens ascendant). Dans le cas présent, nous trions nos films par année de réalisation ascendante, il aurait suffit de remplacer ascending=True par ascending=False pour les trier par date de réalisation descendante, et nous aurions pu choisir un autre critère de tri, par exemple le nombre de votes, en remplaçant by=”year” par by=”votes”.
Filtrer les données
[cc lang=”python”]films[films[“rating”]>8][/cc]

Dans cet exemple, nous ne conservons que les films dont la note est supérieure à 8. Nous aurions bien sûr pu utilise d’autres colonnes ou d’autres opérateurs de comparaison. Voici les opérateurs les plus populaires :
< : inférieur
<= : inférieur ou égal
== : égal
>= : supérieur ou égal
> : supérieur
Dans notre exemple, nous filtrons une donnée numérique, si vous souhaitez filtrer une donnée alphabétique ou alphanumérique il est nécessaire de l’entourer de guillemets.
Minimum, maximum et moyenne
Il est possible d’obtenir le minimum, le maximum ou la moyenne en utilisant respectivement les fonctions min(), max() ou mean() :
[cc lang=”python”]films.min()
films.max()
films.mean()[/cc]
Les informations de toutes les colonnes seront calculées. Nous allons voir ci-dessous comment obtenir les informations d’un colonne précise :
Chaîner les commandes
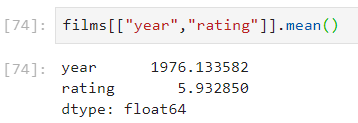
Ces commandes peuvent être chaînées. par exemple, pour obtenir l’année moyenne des films de notre jeu de données ainsi que leur note moyenne, nous ne conservons que certaines colonnes, puis nous leur appliquons la fonction mean() :
[cc lang=”python”]films[[“year”,”rating”]].mean()[/cc]
Le chaînage peut être plus complexe, dans l’exemple suivant nous affichons les titres et notes des 3 meilleurs films de l’année 1981.
[cc lang=”python”]films[films[“year”]==1981].sort_values(by=”rating”,ascending=False)[[“title”,”rating”]].head(3)[/cc]

Enregistrer notre DataFrame dans un fichier csv
Pour terminer cette leçon, nous allons enregistrer notre DataFrame dans un fichier csv :
[cc lang=”python”]films.to_csv(“movies2.csv”)[/cc]
Il est bien sûr possible de chaîner l’enregistrement à la suite des fonctions vues précédemment :

Dans cet exemple nous trions les films de notre DataFrame par note décroissante avant de les enregistrer dans un nouveau fichier CSV que nous nommons movies2.csv
Ce n’est pas tout, Pandas est un outil puissant et nous vous invitons à consulter sa documentation pour apprendre à l’utiliser plus en profondeur, mais nous nous limiterons à ces fonctions pour la deuxième partie de ce tutoriel. Ce n’est pas grave si vous avez du mal à toutes les mémoriser, l’important est que vous vous souveniez qu’elles existent et que vous retrouviez comment les utiliser lorsque cela sera nécessaire. Lancez vous de petits challenges, essayez par exemple de trouver quel a été le deuxième film le mieux noté de l’an 2000 ou alors quelle est la durée moyenne des films d’action qui ont reçu une note supérieure ou égale à 7.
Au cours de cette deuxième partie du tutoriel, vous avez appris à commencer à manipuler des données sous Python. Nous verrons dans la troisième partie du tutoriel comment les afficher sous forme de représentations graphiques et les analyser. N’hésitez pas à nous suivre via Twitter, Facebook ou notre Newsletter afin d’être notifié lors de la publication de la seconde partie de ce tutoriel.Nous allons ajouter un peu de couleurs dans la prochaine partie de ce tutoriel.
Accéder à la troisième partie.
N’hésitez pas à nous suivre via Twitter, Facebook ou notre Newsletter afin d’être notifié lors de la publication de la seconde partie de ce tutoriel.
Vous appréciez notre initiative ? Merci de partager cette page sur Facebook et Twitter.