

Nous nous pencherons dans cette nouvelle série de tutoriels en 3 parties sur les séries temporelles et leur analyse.
L’analyse des séries temporelles est utile car de nombreux exemples de données réelles comportent une dimension chronologique.
La composante “temps” apporte une information fructueuse; elle permet de parler d’évolution, de prédiction et de stratégie. Cependant cela amène aussi une complexification, un point d’une série temporelle n’a pas beaucoup de sens en isolation aussi la série doit-elle être conçue et traitée comme un tout.
La trajectoire d’une voiture autonome et la production énergétique d’un panneau solaire sont deux exemples de séries temporelles.
Dans cette série d’articles, nous allons passer en revue les 5 étapes nécessaires au déploiement de solutions reposant sur l’analyse temporelle, qui sont :
1- La préparation des données
La préparation des données a pour but de charger les données, de les formater pour les rendre analysables et de filtrer les valeurs incohérentes.
Pour les séries temporelles on fera particulièrement attention aux questions de plages horaires, de régularité temporelle. et de remplissage des données manquantes. En effet si dans une analyse de données classiques les valeurs incohérentes sont simplement supprimées, ici il convient de les remplacer pour préserver un temps régulier entre les points de la série. Rendre la série strictement périodique (intervalle de temps constant entre chaque point consécutif) simplifie grandement le travail et est nécessaire pour la quasi-totalité des applications. Je conseille donc de régulariser la série temporelle dès la phase de préparation des données.
2- L’exploration des données
Ici le but est de répondre aux questions suivantes:
– la série est-elle stationnaire ? La stationnarité veut dire que les statistiques de la série temporelle n’évoluent pas.
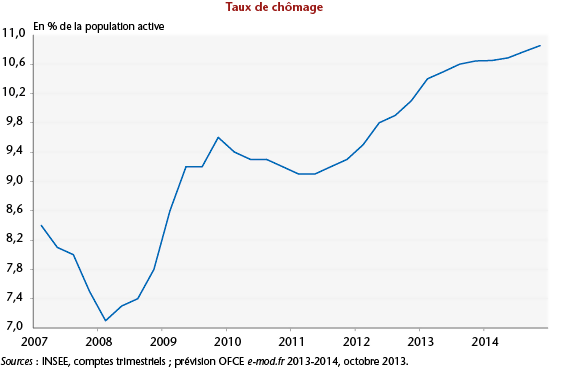
Sur le graphe ci-dessus, on observe une tendance croissante, la courbe du chômage n’est donc pas stationnaire… La plupart des séries temporelles ne sont pas stationnaires. Il faut identifier la cause, car transformer sa série temporelle en une série temporelle stationnaire est souvent la clef pour obtenir des bonnes performances, et c’est souvent ce qu’oublient les débutants.
– La série a-t-elle des périodicités? Périodicité journalière, hebdomadaire, annuelle…
– La série dépend-elle d’autres séries temporelles? Attention aux pièges! Corrélation ne veut pas dire causalité. Par exemple la série temporelle “nombre de burgers vendus à Kuala Lumpur par heure’ est fortement corrélée à la série “production énergie solaire à Paris”. Ces deux séries n’ont évidemment aucun lien causal mais elles ont toutes les deux une variation périodique dans la journée, qui se traduit par une corrélation non-nulle.
3- Analyse des données
Des applications communes sont: le nettoyage des ‘mauvaises valeurs’, la prédiction, la détection d’événements anormaux (par exemple détection de fautes dans un équipement).
4- Évaluation des résultats
Cette étape consiste en le choix d’une ou plusieurs mesures de performance et d’un intervalle de prédiction. En effet on peut s’intéresser à la performance de son algorithme à un horizon de 10 minutes, 1 heure, 1 an…
Ces différents horizons se traduisent souvent par la création de différents algorithmes.
En pratique on aura une analyse des résultats par horizon, le problème d’évaluation de la solution est donc fastidieux si on le fait manuellement. On peut l’automatiser en créant une mini web application (en R/shiny par exemple).
5- Mise en production
Pour mettre une solution de machine learning en production il faut décider comment on gère l’absorption des nouvelles données. En effet, les algorithmes de prédiction ou de détection doivent souvent être calculés périodiquement. Par exemple on peut renouveler une prédiction “production énergétique photovoltaïque” toutes les 10 minutes afin de prendre en compte les dernières mesures.
Je conseille une approche du type ‘mini-batch’ où chaque évaluation de l’algorithme est indépendante. L’autre approche, appelée ‘streaming’ voit l’algorithme évoluer et mettre à jour son état au cours du temps. Cette deuxième méthode est plus difficile à mettre en place et tester, mais est plus rapide en matière de temps d’exécution.
Dans la pratique on s’oriente par défaut vers une approche ‘mini-batch’ sauf si la situation demande des performances critiques comme des applications en temps réel auquel cas on pourra considérer une approche ‘streaming’. (voir https://streaml.io/resources/tutorials/concepts/understanding-batch-microbatch-streaming)
Note :
Dans la phase d’analyse on fera particulièrement attention à la stationnarité de la série. Les phases de nettoyage de données, évaluation et mise en production, qui représentent 90% du travail en réalité, comprennent beaucoup de tâches répétitives qu’il faudra automatiser pour gagner du temps.
Conclusion
Nous avons passé en revue les 5 étapes nécessaires à l’analyse des séries temporelles, dans le prochain article de cette série, nous nous pencherons plus en détail sur les deux premières phases, avec exemples et portions de code à l’appui.
Accéder à la seconde partie : préparation et exploration des données
Accéder à la troisième partie : modélisation et évaluation de séries temporelles