
Le modèle séquentiel est une pile linéaire de couches.
Vous pouvez créer un modèle séquentiel en passant au constructeur une liste d’instances de couches :
[cc lang=”python”]from keras.models import Sequential
from keras.layers import Dense, Activation
model = Sequential([
Dense(32, input_shape=(784,)),
Activation(‘relu’),
Dense(10),
Activation(‘softmax’),
])[/cc]
Vous pouvez également les ajouter à un modèle existant avec la méthode .add() :
[cc lang=”python”]
model = Sequential()
model.add(Dense(32, input_dim=784))
model.add(Activation(‘relu’))[/cc]
Spécification de la forme de l’entrée
Le modèle doit savoir quelle forme d’entrée il doit attendre. C’est la raison pour laquelle la première couche d’un modèle séquentiel doit recevoir les caractéristiques de la forme d’entrée (les autres couches peuvent quant à elles déterminer la forme de leurs entrées par inférence). Il y a plusieurs façons de procéder:
- Passer l’argument input_shape à la première couche. ll doit être transmis sous forme de tuple (comprenant des entiers ou la valeur None, où None accepte tout entier positif). La dimension du lot n’est pas incluse dans input_shape
- Certaines couches 2D, telles que les Dense , supportent la spécification de la forme de l’entrée par l’argument input_dim, et certaines couches 3D temporelles supportent les arguments input_diim et input_length )
- Si vous devez spécifier une taille de lot fixe pour vos entrées ( c’est utile pour les réseaux récurrents à état), vous pouvez passer l’argument batch_size . Si vous passez les valeurs batch_size=32 et input_shape=(6,8) en argument d’une couche, le système s’attendra alors à ce que chaque lot d’entrée ait la forme de lot (32, 6, 8) .
Les portions de code suivante sont strictement équivalentes :
[cc lang=”python”]
model = Sequential()
model.add(Dense(32, input_dim=784))
[/cc]
[cc lang=”python”]
model = Sequential()
model.add(Dense(32, input_dim=784))
[/cc]
Compilation
Avant d’entraîner votre modèle, vous devez configurer le processus d’apprentissage en appelant la méthode compile qui accepte trois arguments :
- optimizer : Il peut s’agir d’un optimiseur défini par son appellation, par exemple rmsprop ou adagrad , ou d’une instance de la classe Optimizer.
- loss : Il s’agit de la fonction de coût que le modèle va utiliser pour minimiser les erreurs. Elle peut être définie par son appellation (exemple : categorical_crossentropy ou mse) ou bien cela peut être une fonction.
- metrics : une liste de métriques. Dans le cas d’un problème de classification, vous utiliserez metrics=[‘accuracy’] mais cet argument peut spécifier une autre métrique en utilisant l’appellation de la métrique à utiliser ou une fonction de métrique sur mesure.
[cc lang=”python”]
# Pour un problème de classification multi-classe
model.compile(optimizer=’rmsprop’,
loss=’categorical_crossentropy’,
metrics=[‘accuracy’])
# Pour un problème de classification binaire
model.compile(optimizer=’rmsprop’,
loss=’binary_crossentropy’,
metrics=[‘accuracy’])
# Pour un problème de régression d’erreur quadratique moyenne
model.compile(optimizer=’rmsprop’,
loss=’mse’)
# Pour des métriques sur-mesure
import keras.backend as K
def mean_pred(y_true, y_pred):
return K.mean(y_pred)
model.compile(optimizer=’rmsprop’,
loss=’binary_crossentropy’,
metrics=[‘accuracy’, mean_pred][/cc]
Entraînement
Les modèles Keras sont entraînés sur des tableaux Numpy d’entrées et de labels. Pour entraîner un modèle, vous utiliserez généralement la fonction fit.
[cc lang=”python”]
# Pour un modèle avec un seule entrée et deux classes (classification binaire) :
model = Sequential()
model.add(Dense(32, activation=’relu’, input_dim=100))
model.add(Dense(1, activation=’sigmoid’))
model.compile(optimizer=’rmsprop’,
loss=’binary_crossentropy’,
metrics=[‘accuracy’])
# Génération de données aléatoires
import numpy as np
data = np.random.random((1000, 100))
labels = np.random.randint(2, size=(1000, 1))
# Entrainement du modèle sur le jeu de données aléatoires par lot de 32 échantillons
model.fit(data, labels, epochs=10, batch_size=32)[/cc]
[cc lang=”python”]
# Pour un modèle avec une entrée et 10 classes (classification en catégories):
model = Sequential()
model.add(Dense(32, activation=’relu’, input_dim=100))
model.add(Dense(10, activation=’softmax’))
model.compile(optimizer=’rmsprop’,
loss=’categorical_crossentropy’,
metrics=[‘accuracy’])
# Génération de données aléatoires
import numpy as np
data = np.random.random((1000, 100))
labels = np.random.randint(10, size=(1000, 1))
# Conversion des labels des catégories en encodage one-hot
one_hot_labels = keras.utils.to_categorical(labels, num_classes=10)
# Entraînement du modèle, avec itération sur les données par lot de 32 échantillons
model.fit(data, one_hot_labels, epochs=10, batch_size=32)
[/cc]
Exemples
Vous trouverez des exemples dans le dossier “examples” du dépôt Github.
Notamment, pour des jeux de données réels :
- CIFAR10 : Réseau de neurones convolutif avec augmentation des données en temps réel.
- IMDB : classification des sentiments en appliquant un modèle LSTM sur des séquences de mots.
- Reuters : classification des sujets en utilisant un perceptron multicouche (MLP)
- MNIST : classification de chiffres écris à la main avec perceptron multicouche et réseau de neurones convolutif.
- Génération de texte au niveau des caractères avec un LSTM
et plus encore…
Perceptron Multicouche (MLP) pour classification multi-classe softmax
[cc lang=”python”]
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
from keras.optimizers import SGD
# Génération de données aléatoires
import numpy as np
x_train = np.random.random((1000, 20))
y_train = keras.utils.to_categorical(np.random.randint(10, size=(1000, 1)), num_classes=10)
x_test = np.random.random((100, 20))
y_test = keras.utils.to_categorical(np.random.randint(10, size=(100, 1)), num_classes=10)
model = Sequential()
# Dense(64) est une couche avec 64 unités cachées
# vous devez spécifier le format attendu des données en entrée
# ici, des vecteurs de dimension 20
model.add(Dense(64, activation=’relu’, input_dim=20))
model.add(Dropout(0.5))
model.add(Dense(64, activation=’relu’))
model.add(Dropout(0.5))
model.add(Dense(10, activation=’softmax’))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss=’categorical_crossentropy’,
optimizer=sgd,
metrics=[‘accuracy’])
model.fit(x_train, y_train,
epochs=20,
batch_size=128)
score = model.evaluate(x_test, y_test, batch_size=128)[/cc]
Perceptron multicouche pour classification binaire :
[cc lang=”python”]
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Dropout
# Génération de données aléatoires
x_train = np.random.random((1000, 20))
y_train = np.random.randint(2, size=(1000, 1))
x_test = np.random.random((100, 20))
y_test = np.random.randint(2, size=(100, 1))
model = Sequential()
model.add(Dense(64, input_dim=20, activation=’relu’))
model.add(Dropout(0.5))
model.add(Dense(64, activation=’relu’))
model.add(Dropout(0.5))
model.add(Dense(1, activation=’sigmoid’))
model.compile(loss=’binary_crossentropy’,
optimizer=’rmsprop’,
metrics=[‘accuracy’])
model.fit(x_train, y_train,
epochs=20,
batch_size=128)
score = model.evaluate(x_test, y_test, batch_size=128)[/cc]
ConvNet (réseau convolutif) type VGG :
[cc lang=”python”]
import numpy as np
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.optimizers import SGD
# Génération des données aléatoires
x_train = np.random.random((100, 100, 100, 3))
y_train = keras.utils.to_categorical(np.random.randint(10, size=(100, 1)), num_classes=10)
x_test = np.random.random((20, 100, 100, 3))
y_test = keras.utils.to_categorical(np.random.randint(10, size=(20, 1)), num_classes=10)
model = Sequential()
# entrée: images de 100×100 avec 3 canaux (rgb) -> tenseurs (100, 100, 3) .
# nous appliquons 32 filtres convolutifs de 3×3 chacun.
model.add(Conv2D(32, (3, 3), activation=’relu’, input_shape=(100, 100, 3)))
model.add(Conv2D(32, (3, 3), activation=’relu’))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), activation=’relu’))
model.add(Conv2D(64, (3, 3), activation=’relu’))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256, activation=’relu’))
model.add(Dropout(0.5))
model.add(Dense(10, activation=’softmax’))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss=’categorical_crossentropy’, optimizer=sgd)
model.fit(x_train, y_train, batch_size=32, epochs=10)
score = model.evaluate(x_test, y_test, batch_size=32)[/cc]
Classification de séquence avec LSTM :
[cc lang=”python”]
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.layers import Embedding
from keras.layers import LSTM
model = Sequential()
model.add(Embedding(max_features, output_dim=256))
model.add(LSTM(128))
model.add(Dropout(0.5))
model.add(Dense(1, activation=’sigmoid’))
model.compile(loss=’binary_crossentropy’,
optimizer=’rmsprop’,
metrics=[‘accuracy’])
model.fit(x_train, y_train, batch_size=16, epochs=10)
score = model.evaluate(x_test, y_test, batch_size=16)[/cc]
Classification de séquences avec convolutions sur 1 dimension :
[cc lang=”python”]
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.layers import Embedding
from keras.layers import Conv1D, GlobalAveragePooling1D, MaxPooling1D
model = Sequential()
model.add(Conv1D(64, 3, activation=’relu’, input_shape=(seq_length, 100)))
model.add(Conv1D(64, 3, activation=’relu’))
model.add(MaxPooling1D(3))
model.add(Conv1D(128, 3, activation=’relu’))
model.add(Conv1D(128, 3, activation=’relu’))
model.add(GlobalAveragePooling1D())
model.add(Dropout(0.5))
model.add(Dense(1, activation=’sigmoid’))
model.compile(loss=’binary_crossentropy’,
optimizer=’rmsprop’,
metrics=[‘accuracy’])
model.fit(x_train, y_train, batch_size=16, epochs=10)
score = model.evaluate(x_test, y_test, batch_size=16)[/cc]
Empilement de LSTM pour classification de séquence :
Empilement de 3 couches LSTM les unes sur les autres, permettant au modèle d’apprendre des représentatins temporelles de plus haut niveau.
Les deux premières LSTM retournent leurs séquences complètes de sortie mais la derni-re ne retourne que la dernière étape de la séquence de sortie, éliminant ainsi la dimensin temporelle ( ce qui revient à convertir la séquence d’entrée en un vecteur)
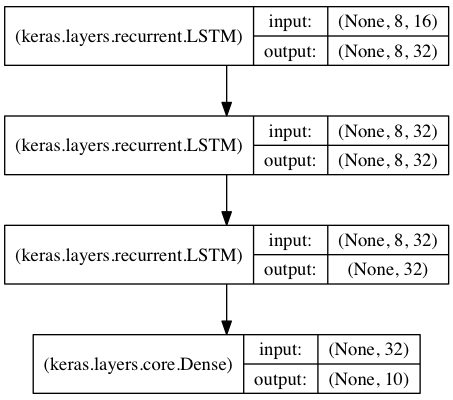
[cc lang=”python”]
from keras.models import Sequential
from keras.layers import LSTM, Dense
import numpy as np
data_dim = 16
timesteps = 8
num_classes = 10
# format de l’entrée attendue: (batch_size, timesteps, data_dim)
model = Sequential()
model.add(LSTM(32, return_sequences=True,
input_shape=(timesteps, data_dim)))
# retourne une séquence de vecteurs de dimension 32
model.add(LSTM(32, return_sequences=True))
# retourne une séquence de vecteurs de dimension 32
model.add(LSTM(32))
# retourne un vecteur unique de dimension 32
model.add(Dense(10, activation=’softmax’))
model.compile(loss=’categorical_crossentropy’,
optimizer=’rmsprop’,
metrics=[‘accuracy’])
# Génération de données d’entraînement aléatoires
x_train = np.random.random((1000, timesteps, data_dim))
y_train = np.random.random((1000, num_classes))
# Génération de données de validation aléatoires
x_val = np.random.random((100, timesteps, data_dim))
y_val = np.random.random((100, num_classes))
model.fit(x_train, y_train,
batch_size=64, epochs=5,
validation_data=(x_val, y_val))[/cc]
Même modèle LSTM, mais à état (stateful)
Dans le cas d’un modèle récurrent à état, les états internes obtenus après le traitement des échantillons des lots sont réutilisés pour le lot suivant. Cela permet de traiter des séquences plus longues tout en conservant une complexité de calcul gérable.
Plus d’informations sur les réseaux de neurones récurrents à états sur la FAQ en anglais.
[cc lang=”python”]from keras.models import Sequential
from keras.layers import LSTM, Dense
import numpy as np
data_dim = 16
timesteps = 8
num_classes = 10
batch_size = 32
# Format du lot attendu en entrée : (batch_size, timesteps, data_dim)
# Notez que nous fournissons la dimension tootale de batch_input_shape
# puisque le réseau est à état.
# L’échantillon i du lot k est celui qui suit l’échantillon i du lot k-1.
model = Sequential()
model.add(LSTM(32, return_sequences=True, stateful=True,
batch_input_shape=(batch_size, timesteps, data_dim)))
model.add(LSTM(32, return_sequences=True, stateful=True))
model.add(LSTM(32, stateful=True))
model.add(Dense(10, activation=’softmax’))
model.compile(loss=’categorical_crossentropy’,
optimizer=’rmsprop’,
metrics=[‘accuracy’])
# Génération des données aléatoires d’entraînement
x_train = np.random.random((batch_size * 10, timesteps, data_dim))
y_train = np.random.random((batch_size * 10, num_classes))
# Génération des données aléatoires de validation
x_val = np.random.random((batch_size * 3, timesteps, data_dim))
y_val = np.random.random((batch_size * 3, num_classes))
model.fit(x_train, y_train,
batch_size=batch_size, epochs=5, shuffle=False,
validation_data=(x_val, y_val))[/cc]
Vous consultez la traduction française de la documentation officielle de Keras réalisée par ActuIA avec l’accord de François Chollet. La version originale de cette page peut être consultée à l’adresse : https://keras.io/getting-started/sequential-model-guide/








