

Experiments have shown that language models trained on email datasets can encode sensitive information in the training data and thus can reveal a specific user’s data. To alleviate this issue, most data scientists use federated learning. Google AI researchers decided to apply Differential Privacy to ImageNet classification to demonstrate the effectiveness of such an approach.
ML-based applications are becoming more and more numerous. The sheer volume of data required to train the algorithms has raised many concerns about privacy. Federated learning offers better guarantees of privacy.
Federated learning and differential privacy
In 2017, Google developed a concept for distributed Deep Learning on devices: federated learning, a solution that allows for on-board processing directly on Android devices of the data to be analyzed. A Deep Learning model does not need data to function, but only uses it to adjust the weights of the links between artificial neurons during the learning phase. In this way, federated learning allows cell phones to learn collaboratively while decoupling the machine learning capability from the need to store data in the cloud.
Differential Privacy (DP) prevents models from storing specific data from individuals and only allows them to learn statistical behavior. With DP, protection of sensitive data is guaranteed when training a federated learning model, since deducing training data from its base or restoring the original datasets becomes almost impossible. In the DP framework, the privacy guarantees of a system are usually characterized by a positive parameter ε, called privacy loss, with a smaller ε corresponding to better privacy. One can train a model with DP guarantees using DP-SGD (stochastic gradient descent with differential privacy), a specialized training algorithm that provides DP guarantees for the trained model. However, this training is not widely used because it generally has two major drawbacks: slow as well as inefficient implementations and a negative impact on utility (such as model accuracy). As a result, most DP research papers present DP algorithms on very small datasets and do not even attempt to evaluate larger datasets, such as Image Net. Google researchers have published the first results of their research using DP which is titled: “Toward Training at ImageNet Scale with Differential Privacy.”
Testing Differential Privacy on ImageNet
The researchers chose the ImageNet classification as a demonstration of the practicality and effectiveness of DP because research on differential privacy in this area is very sparse with few advances and other researchers will have the opportunity to collectively improve the utility of actual DP training. Classification on ImageNet is a challenge for DP because it requires large networks with many parameters. This results in a significant amount of noise added to the computation, as the added noise is proportional to the size of the model.
Scaling up differential privacy with JAX
To save time, the researchers used JAX, an XLA-based high-performance computing library that can perform efficient automatic vectorization and on-the-fly compilation of mathematical computations, recommended for speeding up DP-SGD in the context of smaller data sets such as CIFAR-10.
Their implementation of DP-SGD on JAX was compared to the large ImageNet dataset. Although relatively simple, it resulted in notable performance gains simply due to the use of the XLA compiler compared to other DP-SGD implementations, such as Tensorflow Privacy. XLA is generally even faster than the customized and optimized PyTorch Opacus.
Each step of the DP-SGD implementation requires about two round-trip passes through the network. While non-private training requires only one pass, Google’s approach is the most efficient for training with the gradients required for DP- SGD.
The researchers found DP-SGD on JAX to be fast enough to run large experiments simply by slightly reducing the number of training runs used to find optimal hyperparameters compared to non-private training. A clear improvement over Tensorflow Privacy, which is 5-10 times slower on CIFAR10 and MNIST. The graph below shows the training execution times for two models on ImageNet with DP-SGD versus non-private SGD, each on JAX.
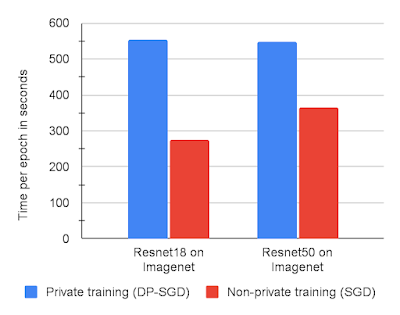
Source: https://ai.googleblog.com/2022/02/applying-differential-privacy-to-large.html
Transferring learning from public data
Pre-training on public data followed by adjusting DP on private data has been shown to improve accuracy on other benchmarks, but the problem is figuring out which public data to use for a given task to optimize transfer learning. Google researchers simulated a private/public data separation using ImageNet as the “private” data and using Places365, another image classification dataset, as a proxy for the “public” data. For this purpose, they pre-trained their models on Places365 before refining them with DP-SGD on ImageNet.
Places365 only features images of landscapes and buildings, not animals like ImageNet, making it a good candidate to demonstrate the model’s ability to transfer to a different but related domain. Transfer learning of Places365 yielded an accuracy of 47.5% on ImageNet with reasonable privacy (ε = 10). This is low compared to the 70% accuracy of a similar non-private model, but compared to naive DP training on ImageNet, which gives very low accuracy (2 – 5%) or no privacy (ε = 10 ), this is a good result.
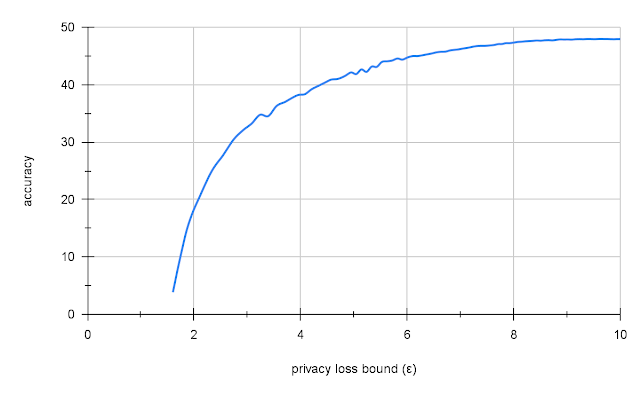 Source : https://ai.googleblog.com/2022/02/applying-differential-privacy-to-large.html
Source : https://ai.googleblog.com/2022/02/applying-differential-privacy-to-large.html
Google researchers hope that these initial results and the source code will provide an impetus for other researchers to work on improving DP and recommend that they start with a baseline that incorporates full batch training and transfer learning.
Article source: “Toward Training at ImageNet Scale with Differential Privacy”
Translated from Etude de Google : Appliquer la confidentialité différentielle à la classification d’images à grande échelle








