

Current AI systems were created to focus on a specific task, generalist AI, which would be able to reason like a human being, perform various unrelated tasks, is currently the quest of many scientists. DeepMind published a paper on the arXiv site about Gato, a generalist agent, trained on 604 tasks including playing Atari games, accurately captioning images, chatting naturally with a human and stacking colored blocks with a robot arm.
DeepMind announced last December that it had developed a new language model called GOPHER based on a transformer, a deep learning model used by text generators like OpenAI’s GPT-3. His researchers applied a similar approach to large-scale language modeling to build the Gato multimodal agent that can perform 604 tasks with a single model. They also drew on recent work on multi-incarnation.
The Gato general-purpose agent
Using a single neural sequence model for all tasks not only reduces the number of inductive biases appropriate for each domain but also increases the amount and diversity of training data, as the sequence model can ingest all data in a flat sequence.
The DeepMind team demonstrated that training an agent that is generally capable of performing a large number of tasks is possible, and that with a little extra data, it could succeed at new ones. To train Gato, the team used supervised offline deep learning to simplify their approach.
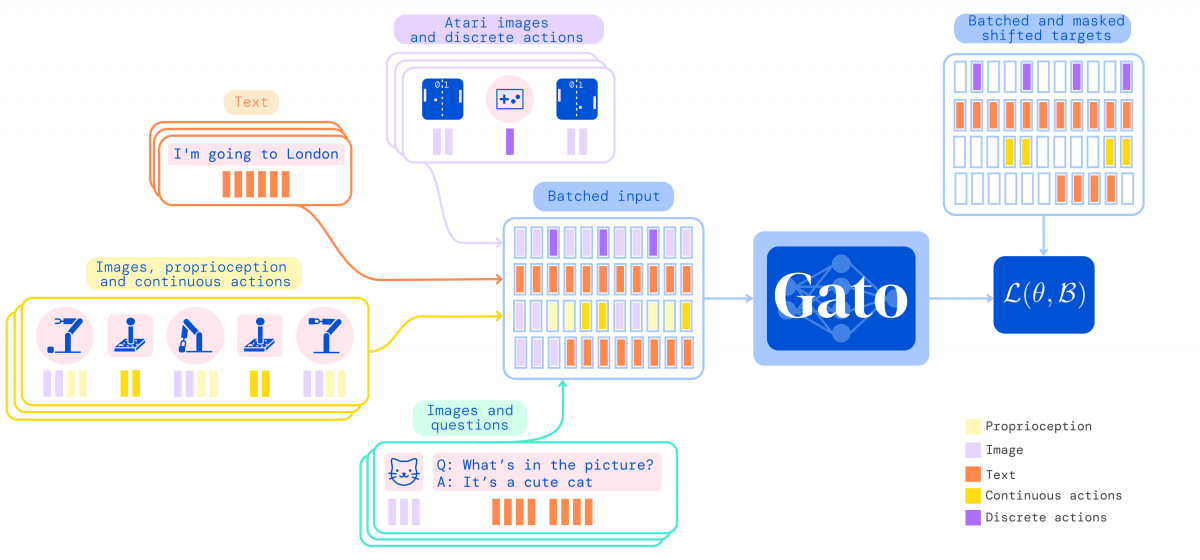
Gato, which includes 1.2 billion parameters, was trained on a wide variety of data such as images, text, proprioception, joint torques, button presses, or even the agents’ experience in simulated or real-world environments, which were then serialized into a flat sequence of tokens. Upon deployment, the sampled tokens are assembled into dialogue responses, captions, button presses, or other context-dependent actions.
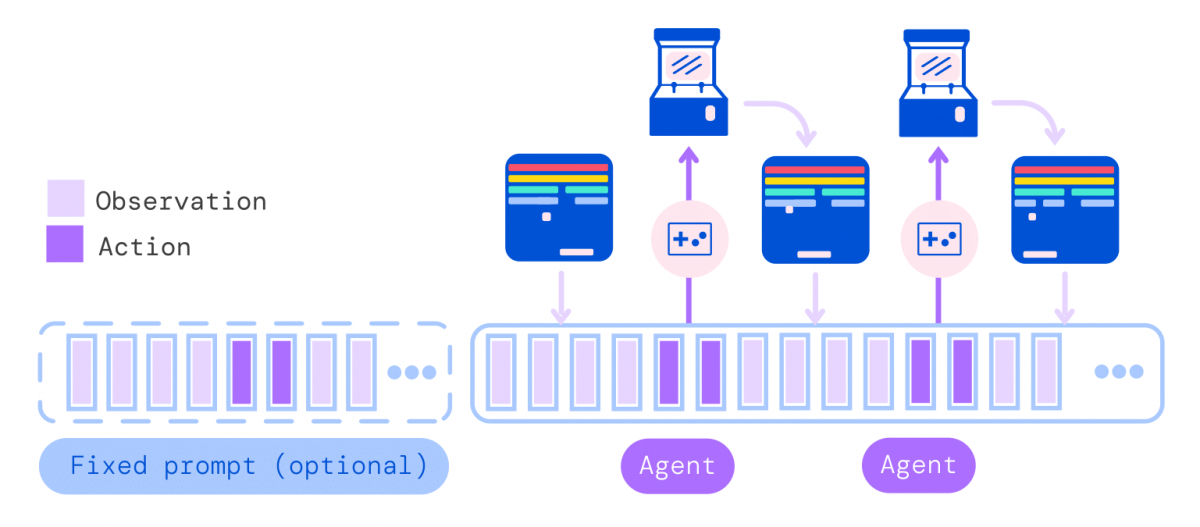
More concretely, during deployment, a prompt, such as a demonstration, is tokenized and forms the initial sequence. The environment then produces the first observation, which is also tokenized and added to the sequence. Gato samples the action vector autoregressively, one token at a time.
Once all the tokens comprising the action vector have been sampled (determined by the environment’s action specification), the action is decoded and sent to the environment, which, moving forward, produces a new observation, this process repeats. The model always sees all previous observations and actions in its 1,024 token context window.
While Gato needs to be improved with additional scaling, especially for dialogues, it would be better than human experts in 450 of the 604 tasks it has been trained for, according to DeepMind.
Article source: ArVix,
DEEPMIND: Scott Reed, Konrad Żołna, Emilio Parisotto, Sergio Gómez Colmenarejo, Alexander Novikov, Gabriel Barth-Maron, Mai Giménez, Yury Sulsky, Jackie Kay, Jost Tobias Springenberg, Tom Eccles,Jake Bruce, Ali Razavi, Ashley Edwards, Nicolas Heess, Yutian Chen, Raia Hadsell, Oriol Vinyals,Mahyar Bordbar and Nando de Freitas.
Translated from Focus sur Gato, agent généraliste de DeepMind capable d’effectuer plus de 600 tâches








