

In every country in the world, to express our feelings, emotions or sometimes even an idea, we use certain facial expressions. However, these typical mimics of non-verbal conversation are open to question: are they the same in different contexts in different parts of the world? Google, in collaboration with the University of California at Berkeley, has attempted to perform a large-scale analysis of facial expressions used in everyday life. In order to achieve this, the researchers exploited the capabilities of deep neural networks (DNN).
The researchers’ challenge: analyzing facial expressions using artificial intelligence
In the field of non-verbal communication, facial expressions are important. Scientists have been asking for several years whether the association of these mimics with a particular context is something universal. Will a Japanese person instinctively smile when seeing his friends, as we do in France? Will seeing a food that should usually be of another color arouse disgust in a Brazilian, as it would in most French people?
To answer this question, researchers are forced to exploit millions of hours of video and millions of images from several parts of the world in order to draw coherent conclusions. Based on this problem and this experimentation, several researchers have decided to use machine learning to carry out their research.
Several researchers from Google and the University of California at Berkeley conducted a study to analyze nearly 6 million videos in nearly 144 countries. To accomplish this task that was far too time-consuming to do manually, the researchers leveraged multiple types of neural networks. Their findings were published by Alan S. Cowen and Dacher Keltner of UC Berkeley and Florian Schroff, Brendan Jou, Hartwig Adam and Gautam Prasad of Google Research.
Creating a database using several types of neural networks
The first step for the research team was to build the dataset needed to conduct the experiments planned for the study. Experienced evaluators conducted a manual search of a huge public video database to identify suitable videos for the further research process. Several phrase categories were pre-selected to facilitate this task. In order to retain only those videos that matched the region of the world in which they were supposed to be shot, the researchers took the time to check whether the environment of the video matched that indicated by the user who had submitted the content.
Then, all the faces in these videos were identified using a convolutional deep neural network (CNN) that tracks their movements using a method based on classical optical flow. This system is similar to the Google Cloud Face Detection API. The set of facial expressions of these people were tagged into 28 distinct categories using a Google Crowdsource-like platform. The image below shows you the design of the platform as well as the set of tags, just click on the right category to classify the facial expression of the person:
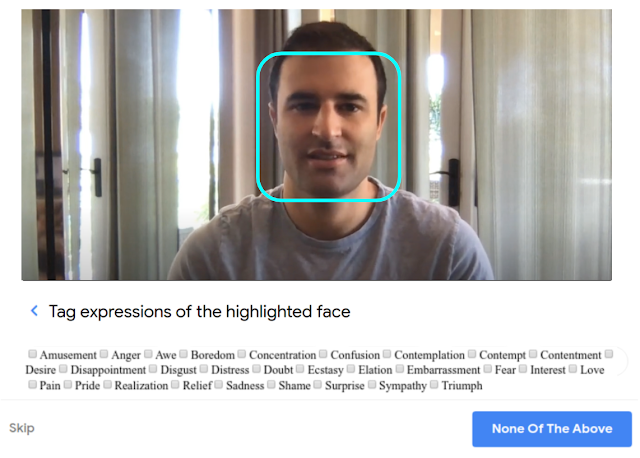
A pre-trained Inception network was used to extract the most egregious features for each of the facial expression categories. This data was fed into an LSTM neural network whose function is to model how a facial expression might change over time.
To ensure the quality of the set of models and that they could make correct predictions based on regions of the world, their fairness was evaluated on a previously designed database using facial expression labels similar to those used by the researchers.
Illustration of the whole process, starting from the CNN to the LSTM:
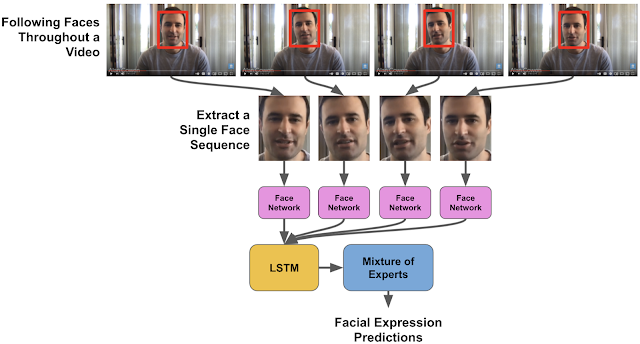
To recognize the context in which the person performs a facial expression, DNNs were exploited. They were used to model the textual characteristics of a video such as its title or description with the proposed visual content (video-subject model). One of these DNNs was based on textual data only (text-topic model). All the models offer thousands of labels corresponding to the different contexts.
The two experiments conducted by the researchers
Two experiments were conducted by the researchers in order to draw conclusions about facial expressions around the world:
- In the first experiment, 3 million public videos from smartphones were exploited. All the facial expressions were correlated using the process previously explained. The researchers found that 16 types of facial expressions were associated with contexts that were the same, regardless of the region of the world. People laughed if they listened to a joke, felt awe if they watched a fireworks display or were happy if they watched a positive sporting event.
- For the second experiment, 3 million videos were also used. The database was different from the one used in the first experiment. However, the contexts were annotated with the model using an LSTM that only takes into account the textual characteristics of the video, and not its audiovisual content. The results showed that the conclusions drawn from the first experiment were not so different from those of the second experiment.
Below is a table designed by the researchers. A large box corresponds to the intersection between a context and a facial expression. Each box is divided into 12 small rectangles of equal size corresponding to a region of the world. For example, in the upper left-hand corner, we find Latin America and in the lower right-hand corner, East Asia. Each pixel is tinted with a color that varies between blue and red. If the box is blue, the facial expression is almost not present in the context studied, if it is red, the mimic is very regularly used by people in the videos:
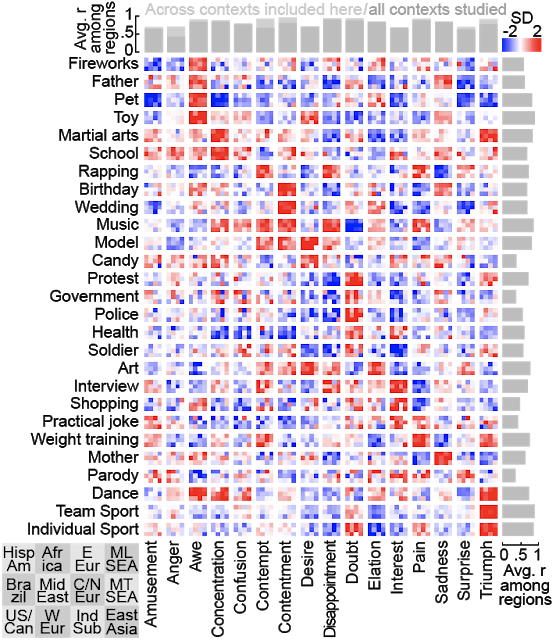
In both cases, the facial expressions seem to be similar, regardless of the culture of the 12 regions of the world studied in this research. With this study, the researchers wanted to show that it is entirely possible to use machine learning to better understand and identify our behaviors and communication methods, regardless of the culture or region to which people belong.
Translated from Intelligence artificielle : la reconnaissance d’expressions faciales peut-elle être universelle ?








