Hacker un modèle de deep learning : Vous n’avez même pas besoin d’un PhD ni d’un GPU
Introduction
Les réseaux de neurones profonds, en abrégé, DNNs (Deep Neural Networks) sont les modèles d’apprentissage les plus performants ayant plusieurs cas d’usage, notamment dans de nombreux environnements critiques tels que les voitures autonomes, le diagnostic du cancer, la surveillance et le contrôle d’accès, les assistants personnels intelligents, le credit scoring, la détection de transaction financière frauduleuse et des fichiers binaires malveillants.
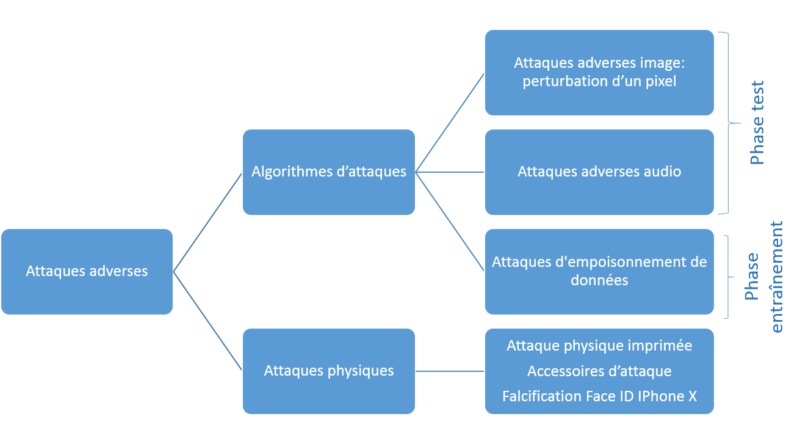
Cependant, des recherches scientifiques montrent que ces modèles sont facilement dupés. Nous distinguons différents types d’attaques qui peuvent tromper les DNNs (pour plus de détails, voir la section Classement des attaques adverses):
Algorithmes d’attaque adverse
Les algorithmes d’attaque adverse représentent le type le plus étudié, et le premier qui a été introduit. Ils sont principalement appliqués au domaine de la vision par ordinateur (computer vision). La section suivante est consacrée à en apprendre davantage sur eux.
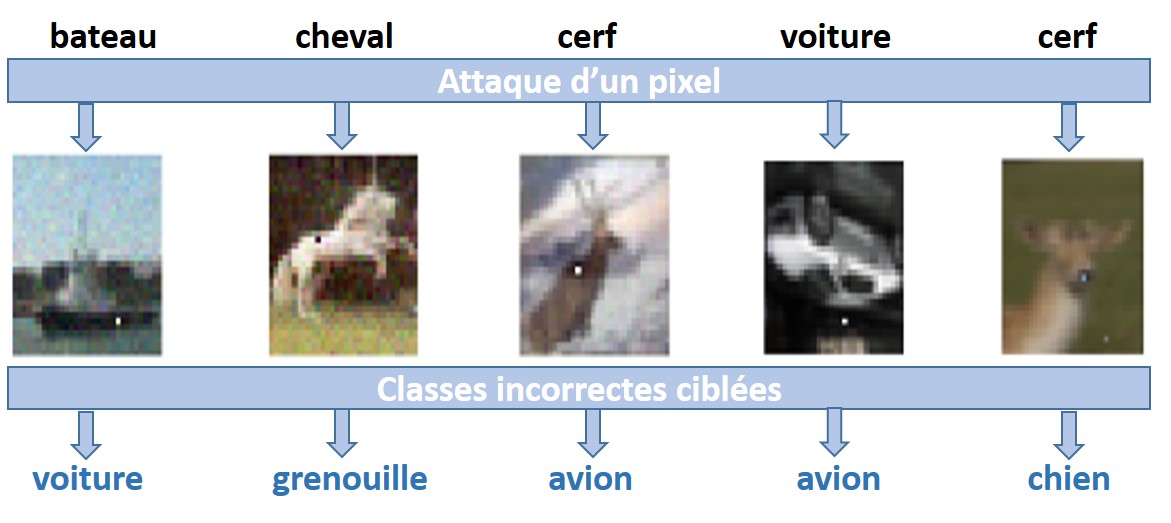
Les DNNs pourraient être trompés par une perturbation d’un pixel!
En haut de la figure, nous trouvons les étiquettes correctes des images d’entrée. L’application d’une attaque de perturbation d’un pixel [Su et al., 2017] amène les DNNs à mal classer les entrées dans les classes ciblées situées en bas de la figure.
Attaques adverses audio
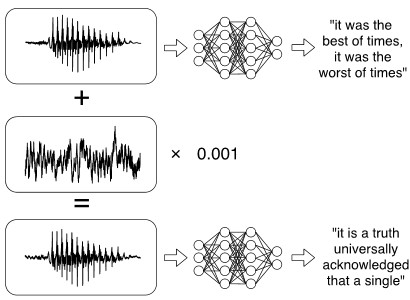
Nous donnons l’exemple suivant de [Carlini & Wagner, 2018] où les auteurs construisent des attaques adverses audio ciblées sur la reconnaissance automatique de la parole et les appliquent à DeepSpeec de Mozilla. Donnons un waveform audio en haut à gauche de l’image ci-dessous, qui se traduit par “it was the best of times, it was the worst of times”. L’application d’une petite perturbation permet d’en produire un waveform audio similaire à plus de 99,9%, mais transcrit comme la phrase cible “it is a truth universally acknowledged that a single” avec un taux de réussite de 100%.
Attaques d’empoisonnement de données
Les algorithmes d’apprentissage de la collecte de données sont exposés au risque d’empoisonnement des données, c’est-à-dire à une attaque par coordonnées dans laquelle une fraction des données d’apprentissage est contrôlée par l’attaquant et manipulée de manière à subvertir le processus d’apprentissage. Comme exemples d’applications, nous trouvons le filtrage anti-spam, la détection de programmes malveillants et la reconnaissance manuscrite de chiffres [Muñoz-González et al., 2017].
Attaques du monde physique
Les algorithmes d’attaque adverse ont une efficacité limitée dans le monde physique en raison de l’évolution de ses conditions (lumière, bruits …). Nous donnons quelques exemples d’attaques physiques réussies:
Attaque physique imprimée
Considérons un système de voiture autonome qui utilise des DNNs pour identifier les panneaux de signalisation routière. Nous donnons l’exemple suivant de [Evtimov et al., 2017] où les auteurs construisent des perturbations sur des panneaux STOP (affiche imprimée perturbée du signe STOP à gauche et des stickers sur le panneau STOP réel à droite) qui ont dupé le DNN pour classer le panneau STOP comme un panneau de limitation de vitesse 45, dans ce cas la voiture ne s’arrêtait pas et peut donc faire un crash.

Accessoires d’attaque
Il s’agit d’une attaque physiquement réalisable et discrète appliquée aux systèmes biométriques faciaux, largement utilisés en surveillance et en contrôle d’accès. Elle est réalisée en imprimant une monture de lunettes permettant à l’attaquant de la porter pour échapper à sa reconnaissance ou pour se faire passer pour une autre personne, comme le montre l’exemple ci-dessous:

Face ID IPhone X trompé par un masque à 200 et permettent de déverrouiller le téléphone de la même manière que les jumeaux.
et permettent de déverrouiller le téléphone de la même manière que les jumeaux.

Conséquences : Pourquoi est-il primordiale d’étudier ce phénomène?
Il est clair que les attaques adverses pourraient entraîner un fonctionnement incorrect des DNNs et inciter les adversaires à les tromper, ce qui pourrait sérieusement compromettre la sécurité des systèmes pris en charge par ces modèles, avec des conséquences parfois dévastatrices. Par exemple, des véhicules autonomes peuvent être broyées, un contenu illicite ou illégal peut contourner les filtres de contenu, ou des systèmes d’authentification biométrique peuvent être manipulés pour permettre un accès inapproprié.
Par conséquent, les utilisateurs tels que les constructeurs automobiles, les banques et les compagnies d’assurances, les services de radiologie, les utilisateurs de FACE et VOICE ID (etc.) doivent avoir la certitude que les DNNs fonctionnent correctement et sont robustes contre les attaques éventuelles. Pour cela, de nombreux articles scientifiques ont été (et sont toujours) consacrés à créer de nouvelles attaques et mettre au point des mécanismes de défense pour réduire leur efficacité ainsi que définir de métriques d’utilité permettant de mesurer la vulnérabilité des DNNs.
Les algorithmes d’attaque adverse
Quoi, quand et comment?
Ce phénomène, appelé instabilité adverse (adversarial instability), a été introduit et étudié en 2013 dans le domaine de la classification des images [Szegedy et al., 2013]. Les auteurs ont constaté que l’application d’une perturbation imperceptible à l’homme aux entrées durant la phase de test permettait de créer des exemples adverses (adversarial examples) pouvant duper le modèle de classification et aboutir à des sorties incorrectes arbitraires (ou spécifiques telles qu’illustrées plus loin).

Pourquoi est-ce possible?
Ces manipulations sont effectivement possibles à cause de la généralisation imparfaite apprise par les DNNs à partir des ensembles d’entraînements finis[Bengio, 2009] et de la linéarité sous-jacente de la plupart des composants utilisés pour construire des DNNs [Kurakin et al., 2016].
Comment commencer à protéger votre DNN?
Plateformes d’attaque / défense
Plusieurs Plateformes d’attaque / défense ont été proposées pour fournir des implémentations de référence des attaques et des défenses avec les frameworks du Deep Learning les plus populaires, destinés à être utilisés par les développeurs pour construire des modèles robustes.
Dans le tableau ci-dessous, nous répertorions cinq Plateformes open source. Pour chacune, nous donnons le nombre d’attaques et de défenses mises en œuvre, les frameworks DL supportés et des liens utiles vers les codes et les documentations. Les listes d’attaques et de défenses dans chaque plateforme sont données ci-dessous dans Tab. 2 et Tab. 3
| Projets | Liens | Attaques | Défenses | Détecteurs | Frameworks DL | |
| DeepSec Platforme | Ling et al., 2019 GitHub DeepSec demo Platforme (bientôt disponible) | 16 | 13 | 3 | / | |
| ART (Python toolbox de IBM) | GitHub | 9 | 9 | 3 | TensorFlow, Keras, PyTorch, MXNet | |
| AdvBox (Python toolbox) | GitHub | 7 | 0 | 0 | PaddlePaddle | |
| Foolbox (Python toolbox) | Rauber et al., 2017 ReadTheDocs GitHub | 20 | 0 | 0 | PyTorch, Keras, TensorFlow, Theano, Lasagne and MXNet | |
| Cleverhans (Python librairie) | Papernot et al., 2016 Documentation GitHub | 12 | 1 | 0 | Tensorflow, Keras Sequential | |
Tab. 1 Plateformes d’attaque / défense open source DeepSec, ART, AdvBox, Foolbox et Cleverhans.
Les attaques
Dans le tableau ci-dessous, nous répertorions les différentes attaques mises en œuvre dans chacune des plateformes.
| Projets | Attaques |
| DeepSec | (BIM) Basic Iterative Method [Kurakin et al., 2016]
(CW) Carlini and Wagner’s attack [Carlini and Wagner, 2016] (DF) DeepFool [Moosavi-Dezfooli et al., 2015] (EAD) Elastic-net Attacks to DNNs [Chen et al., 2017] (FGSM) Fast Gradient Sign Method [Goodfellow et al., 2014] (JSM) Jacobian-based Saliency Map [Papernot et al., 2016] (ILLC) Iteraticve LLC attack [Kurakin et al., 2016] (L-BFGS) Box-constrainded L-BFGS attack [Szegedy et al., 2013] (LLC) Least Likely Classattack [Kurakin et al., 2016] (OM) OptMargin [He et al., 2018] (PGD) Projected L_inf Gradient Descendent [Madry et al., 2017] (R+FGS) Random Perturbation with FGSM [Tramèr et al., 2017] (R+LLC) Random Perturbation with LLC [Tramèr et al., 2017] (T-MI-FGSM) Targeted Momentum Iterative FGSM [Yinpeng & al., 2017] (U_MI_FGSM) Untargeted MI-FGSM [Yinpeng & al., 2017] (UAP) Universal Adversarial Perturbation [Moosavi-Dezfooli et al., 2016] |
| Adversarial Robustness Toolbox of IBM (ART) | (BIM) (CW) (DF) (FGSM) (JSM) (PGD) (UAP)
(NF) NewtonFool [Jang et al., 2017] (VAM) Virtual Adversarial Method [Miyato et al., 2015] |
| AdvBox | (BIM) (DF) (FGSM) (JSM) (L-BFGS)(MI-FGSM)
( ILCM) ITERATIVE LEAST-LIKELY CLASS METHOD |
| Foolbox | (FGSM) (DF) (L-BFGS) (JSM)
Boundary Attack [Brendel et al., 2018] Local Search Attack [Narodytska & Kasiviswanathan, 2016] Single Pixel Attack [Narodytska & Kasiviswanathan, 2016] Dans Rauber et al., 2017, GitHub: Additive Gaussian Noise Attack Additive Uniform Noise Attack Approximate L-BFGS Attack Contrast Reduction Attack Gaussian Blur Attack Gradient Attack Iterative Gradient Attack Pointwise Attack Precomputed Images Attack Salt and Pepper Noise Attack SLSQP Attack: Sequential Least Squares Programming |
| Cleverhans | (BIM) (CW) (DF) (EAD) (FGSM) (JSM) (L-BFGS) (MI_FGSM) (PGD)
Feature Adversaries [Sabour et al., 2015] SPSA Simultaneous perturbation stochastic approximation [Uesato et al., 2018] |
Tab. 2 Listes des attaques implémentées sur les plateformes DeepSec, ART, AdvBox, Foolbox et Cleverhans.
Les systèmes de défense
Dans le tableau ci-dessous, nous répertorions les différents systèmes de défense / détecteurs mis en œuvre sur chacune des plateformes DeepSec, ART et Cleverhans.
| Défenses | Détecteurs | |
| DeepSec | (NAT) Naïve Adversarial Training [Kurakin et al., 2016]
(EAT) Ensemble Adversarial Training [Tramèr et al., 2017] (PAT) PGD-based Adversarial Training [Madry et al., 2017] (DD) Deffensive Distiliation [Papernot et al., 2015] (IGR) Input Gradient Regularizaton [Ross & Doshi-Velez, 2017] (EIT) Ensemble input Transformation [Guo et al., 2017] (RT) Random Transformation based defense [Xie et al., 2017] (PD) Pixcel Defence [Song et al., 2017] (TE) Thermometer Encoding defense [Buckman et al., 2017] (RC) Region-based Classification [Cao et al., 2017] |
(LID) Local Intrinsic Dimentionality based detector [Ma et al., 2018]
(FS) Feature Squeezing detector [Xu et al., 2017] (MagNet ) MagNet detector [Meng & Chen, 2017] |
| ART | (FS) Feature Squeezing [Xu et al., 2017]
(SS) Spatial Smoothing [Xu et al., 2017] (LS) Label Smoothing [Warde-Farley and Goodfellow, 2016] (AT) Adversarial Training [Szegedy et al., 2013] (VAT) Virtual Adversarial Training [Miyato et al., 2015] (GDA) Gaussian Data Augmentation [Zantedeschi et al., 2017] (TE) Thermometer Encoding [Buckman et al., 2017] (TVM) Total Variance Minimization [Guo et al., 2017] (JPEG_C) JPEG compression [Dziugaite et al., 2016] |
(FS) Feature Squeezing [Xu et al., 2017]
Basic Detector based on inputs Detector trained on the activations of a specific layer Detector based on activations analysis [Chen et al., 2017] |
| Cleverhans
|
(AT) Adversarial Training [Szegedy et al., 2013, Goodfellow et al., 2014] |
Tab. 3 Listes de défenses / détecteurs implémenté(e)s sur les plateformes DeepSec, ART et Cleverhans.
Caractérisation des attaques adverses
Les algorithmes d’attaque adverse sont caractérisés par l’architecture ciblée, la stratégie d’attaque, le taux de perturbation, le taux de succès de l’attaque et les coûts de calcul.
Classification des attaques adverses
En général, les attaques existantes peuvent être classées selon plusieurs dimensions [Yuan et al., 2017, Ling et al., 2019]. Dans le tableau suivant, nous donnons une classification des attaques selon Kurakin et al., 2018.
| Classification par | Classes | Explication |
| But d’attaques | Attaques non ciblées | Visent à amener le classificateur à prédire n’importe quelle étiquette incorrecte |
| Attaques ciblées | Visent à amener le classificateur à prédire une étiquette cible incorrecte spécifique | |
| Fréquence d’attaques | Attaques non itératives | La génération d’attaque ne prend qu’une seule étape |
| Attaques itératives | La génération d’attaque prend plusieurs mises à jour itératives | |
| Connaissance de l’adversaire sur le modèle | Boîte blanche | L’adversaire a une connaissance complète du modèle, y compris le type, l’architecture, les valeurs et les poids de tous les paramètres |
| Boîte noire avec sondage | L’adversaire ne connaît pas grand-chose sur le modèle mais peut sonder ou interroger le modèle. Il existe de nombreux scénarios possibles: connaître l’architecture mais pas les paramètres, ne connaissant même pas l’architecture mais étant capable d’observer les probabilités de sortie pour chaque classe ou seulement d’observer le choix de la classe la plus probable | |
| Boîte noire sans sondage | L’adversaire a peu ou pas de connaissances sur le modèle et n’est pas autorisé à le sonder ou l’interroger lors de la construction d’exemples adverses. Dans ce cas, l’attaquant doit construire des exemples adverses qui trompent la plupart des modèles d’apprentissage automatique | |
| La manière dont l’adversaire peut introduire des données dans le modèle | Algorithmes d’attaques (phase de test) | Les exemples adverses sont introduits durant la phase test |
| Algorithmes d’attaques (phase d’entraînement) | L’adversaire a un accès direct aux données réelles introduites dans le modèle | |
| Attaques physiques | L’adversaire est capable de placer des objets dans l’environnement physique vu par la caméra ou de produire des sons entendus par le microphone |
Tab. 4 Classification des attaques adverses
Évaluation de la robustesse des DNNs
En général, l’évaluation de la robustesse des DNNs pourrait être réalisée en introduisant des métriques pour mesurer la robustesse, ou en construisant des attaques, et en introduisant des procédures défensives.
La première approche est beaucoup plus difficile à mettre en œuvre dans la pratique et toutes les tentatives ont nécessité des approximations [Bastani et al., 2016], [Huang et al., 2017]. Quant à la deuxième approche, les procédures défensives devraient être effectuées avec un impact faible sur l’architecture, maintenir la précision et la vitesse du modèle, être robuste à la transférabilité.
Les méthodes de défense existantes et leurs principaux inconvénients
Nous présentons dans le tableau ci-dessous les méthodes de défense existantes et leurs principaux inconvénients selon Kurakin et al., 2018, qui affirment qu’aucune méthode de défense contre des attaques adverses n’est encore complètement satisfaisante.
| Méthodes de défense | Principaux inconvénients |
| Techniques de prétraitement / stratégies de débruitage:
– Compression JPEG [Das et al., 2017] – Filtrage médian et réduction de la précision des données d’entrée [Xu et al., 2017] |
Échec dans la boîte blanche [He et al., 2017] |
| Masquage du gradient / Rendre le gradient inutile:
– Modèle non différenciable, gradients nuls dans la plupart des points. – Les gradients s’éloignent de la limite de décision |
Très vulnérable au transfert de boîte noire [Papernot et al., 2016] |
| Détecter des exemples adverses [Metzen et al., 2017] | Échec contre les attaquants au courant du détecteur ou de fortes attaques [Carlini and Wagner, 2016] |
| Réseaux RBF [Goodfellow et all., 2014] | Réduire la précision sur entrées pures |
| Réseaux RBF profonds | Pas encore entrainé avec succès |
| Réseaux Capsule [Hinton et al., 2018] | Pas encore évalué sur les jeux de données courants
Utilisé dans la littérature adverse |
| La défense la plus populaire: l’entraînement adverse actuel [Szegedy et al., 2014, Goodfellow et all., 2014, Huang et al., 2015, Kurakin et al., 2016, Buckman et al., 2018]:
Injecter des exemples adverses durant le processus d’entraînement et construire le modèle, soit sur des exemples adverses, soit sur un mélange d’exemples pures et adverses.
|
Sur-adapter à l’attaque spécifique utilisée au moment de l’entraînementà solution dans [Madry et al., 2017]
Apprendre par inadvertance à masquer le gradient plutôt que de déplacer réellement la limite de décisionà solution dans [Tramer et al.,2017] Sur-adapter à une région de contrainte spécifique utilisée pour générer les exemples adverses à solution dans [Gilmer et al., 2018] |
Tab. 5 Les méthodes de défense existantes et leurs principaux inconvénients
Conclusion et appel à la collaboration
La vulnérabilité des modèles de Deep Learning a été introduite et étudiée pour la première fois en 2013. Parallèlement à la croissance exponentielle des modèles DL qui surpassent de nos jours l’être humain dans de nombreux domaines, ce phénomène de vulnérabilité devient de plus en plus critique et donne lieu à des débats juridiques et éthiques sur les domaines critiques tels que les voitures autonomes ou le diagnostic du cancer par exemples.
Il existe une vaste littérature produite par des scientifiques et des développeurs qui essaient de limiter toutes les attaques adverses possibles et de développer des mécanismes défensifs pour réduire leur efficacité. De nombreuses plateformes open source sont disponibles pour cette raison. Cependant, cela ne suffit pas et nécessite plus d’efforts pour assurer la robustesse de notre monde de l’IA. Axionable s’engage donc à innover en matière de techniques d’attaque et de défense. Si vous avez une idée ou souhaitez collaborer, veuillez nous contacter sur datascience@axionable.com.
Annexe
| Projets | Liens | Attaques | Défenses | Détecteurs | Frameworks DL | |
| DeepSec Platforme | Ling et al., 2019 GitHub DeepSec demo Platforme (bientôt disponible) | 16 | 13 | 3 | / | |
| ART (Python toolbox de IBM) | GitHub | 9 | 9 | 3 | TensorFlow, Keras, PyTorch, MXNet | |
| AdvBox (Python toolbox) | GitHub | 7 | 0 | 0 | PaddlePaddle | |
| Foolbox (Python toolbox) | Rauber et al., 2017 ReadTheDocs GitHub | 20 | 0 | 0 | PyTorch, Keras, TensorFlow, Theano, Lasagne and MXNet | |
| Cleverhans (Python librairie) | Papernot et al., 2016 Documentation GitHub | 12 | 1 | 0 | Tensorflow, Keras Sequential | |
Tab. 1 Plateformes d’attaque / défense open source DeepSec, ART, AdvBox, Foolbox et Cleverhans.
| Projets | Attaques |
| DeepSec | (BIM) Basic Iterative Method [Kurakin et al., 2016]
(CW) Carlini and Wagner’s attack [Carlini and Wagner, 2016] (DF) DeepFool [Moosavi-Dezfooli et al., 2015] (EAD) Elastic-net Attacks to DNNs [Chen et al., 2017] (FGSM) Fast Gradient Sign Method [Goodfellow et al., 2014] (JSM) Jacobian-based Saliency Map [Papernot et al., 2016] (ILLC) Iteraticve LLC attack [Kurakin et al., 2016] (L-BFGS) Box-constrainded L-BFGS attack [Szegedy et al., 2013] (LLC) Least Likely Classattack [Kurakin et al., 2016] (OM) OptMargin [He et al., 2018] (PGD) Projected L_inf Gradient Descendent [Madry et al., 2017] (R+FGS) Random Perturbation with FGSM [Tramèr et al., 2017] (R+LLC) Random Perturbation with LLC [Tramèr et al., 2017] (T-MI-FGSM) Targeted Momentum Iterative FGSM [Yinpeng & al., 2017] (U_MI_FGSM) Untargeted MI-FGSM [Yinpeng & al., 2017] (UAP) Universal Adversarial Perturbation [Moosavi-Dezfooli et al., 2016] |
| Adversarial Robustness Toolbox of IBM (ART) | (BIM) (CW) (DF) (FGSM) (JSM) (PGD) (UAP)
(NF) NewtonFool [Jang et al., 2017] (VAM) Virtual Adversarial Method [Miyato et al., 2015] |
| AdvBox | (BIM) (DF) (FGSM) (JSM) (L-BFGS)(MI-FGSM)
( ILCM) ITERATIVE LEAST-LIKELY CLASS METHOD |
| Foolbox | (FGSM) (DF) (L-BFGS) (JSM)
Boundary Attack [Brendel et al., 2018] Local Search Attack [Narodytska & Kasiviswanathan, 2016] Single Pixel Attack [Narodytska & Kasiviswanathan, 2016] Dans Rauber et al., 2017, GitHub: Additive Gaussian Noise Attack Additive Uniform Noise Attack Approximate L-BFGS Attack Contrast Reduction Attack Gaussian Blur Attack Gradient Attack Iterative Gradient Attack Pointwise Attack Precomputed Images Attack Salt and Pepper Noise Attack SLSQP Attack: Sequential Least Squares Programming |
| Cleverhans | (BIM) (CW) (DF) (EAD) (FGSM) (JSM) (L-BFGS) (MI_FGSM) (PGD)
Feature Adversaries [Sabour et al., 2015] SPSA Simultaneous perturbation stochastic approximation [Uesato et al., 2018] |
Tab. 2 Listes des attaques implémentées sur les plateformes DeepSec, ART, AdvBox, Foolbox et Cleverhans.
| Défenses | Détecteurs | |
| DeepSec | (NAT) Naïve Adversarial Training [Kurakin et al., 2016]
(EAT) Ensemble Adversarial Training [Tramèr et al., 2017] (PAT) PGD-based Adversarial Training [Madry et al., 2017] (DD) Deffensive Distiliation [Papernot et al., 2015] (IGR) Input Gradient Regularizaton [Ross & Doshi-Velez, 2017] (EIT) Ensemble input Transformation [Guo et al., 2017] (RT) Random Transformation based defense [Xie et al., 2017] (PD) Pixcel Defence [Song et al., 2017] (TE) Thermometer Encoding defense [Buckman et al., 2017] (RC) Region-based Classification [Cao et al., 2017] |
(LID) Local Intrinsic Dimentionality based detector [Ma et al., 2018]
(FS) Feature Squeezing detector [Xu et al., 2017] (MagNet ) MagNet detector [Meng & Chen, 2017] |
| ART | (FS) Feature Squeezing [Xu et al., 2017]
(SS) Spatial Smoothing [Xu et al., 2017] (LS) Label Smoothing [Warde-Farley and Goodfellow, 2016] (AT) Adversarial Training [Szegedy et al., 2013] (VAT) Virtual Adversarial Training [Miyato et al., 2015] (GDA) Gaussian Data Augmentation [Zantedeschi et al., 2017] (TE) Thermometer Encoding [Buckman et al., 2017] (TVM) Total Variance Minimization [Guo et al., 2017] (JPEG_C) JPEG compression [Dziugaite et al., 2016] |
(FS) Feature Squeezing [Xu et al., 2017]
Basic Detector based on inputs Detector trained on the activations of a specific layer Detector based on activations analysis [Chen et al., 2017] |
| Cleverhans
|
(AT) Adversarial Training [Szegedy et al., 2013, Goodfellow et al., 2014] |
Tab. 3 Listes de défenses / détecteurs implémenté(e)s sur les plateformes DeepSec, ART et Cleverhans.