
Les biais cognitifs ou psychologiques sont des comportements naturels qui mènent l’esprit humain à faire des choix, en général en situation de manque de ressources cognitives tels que le temps, l’intérêt ou l’information. Dans d’autres cas, le biais peut être provoqué par des facteurs émotionnels ou motivationnels, comme c’est souvent le cas dans les interactions sociales. Ces biais conditionnent notre nature humaine et nous conduisent parfois à des situations irrationnelles ou de dissonance collective.
Ici, nous nous intéressons à la manière dont peuvent être structurés ces biais dans nos algorithmes de machine learning et plus particulièrement au sein des moteurs de recommandation. Cela constitue une problématique naissante d’éthique des algorithmes, qui ne semble pouvoir être adressée qu’avec la bienveillance de tous les acteurs, qu’ils soient concepteurs, intégrateurs ou utilisateurs.
En m’appuyant d’une part sur mon cursus de concepteur d’outils numériques et d’autre part sur le laboratoire de recherche en sciences cognitives SND (Sciences, Normes, Décision), affilié à Paris-Sorbonne et au CNRS, je me suis intéressé à cette problématique, dans le cadre d’un doctorat. Une aventure R&D initiée il y a 7 ans, jonchée de travaux de recherche et de développements expérimentaux, et qui se concrétise désormais au sein de l’organisme de recherche privé Data Nostra[1], avec l’élaboration d’un moteur de recommandation innovant intitulé Maestro Engine[2].
Recommandations vs. Prédictions
La manière dont nous concevons nos moteurs de recommandations nous engerait-elle d’emblée dans une logique d’amplification du biais de confirmation ? Ce biais consiste à accorder plus de poids aux informations qui confirment des idées initiales. Pour l’individu, le sens de cette réflexion est d’agir de manière à rendre ses attentes vraies. Ce qui l’entraîne à ignorer ou minimiser des informations véridiques au profit d’autres, moins véridiques, mais qui lui permettent de poursuivre le sillon de sa réflexion initiale.Or, lorsque nous faisons appel à un moteur de recommandation, nous pouvons nous attendre à ce qu’il suggère des réponses numériques qui sont dans la continuité de notre trajectoire initiale. C’est d’ailleurs ce que mesure la métrique reine pour établir la pertinence des moteurs : RMSE (Root Mean Square Error), soit une mesure de la différence entre les recommandations prédites et les choix réellement faits par les utilisateurs.
Nous utilisons donc des mesures de pertinence issues du domaine de l’analyse prédictive pour mesurer des recommandations. Pourquoi cet amalgame ? Pourquoi vouloir recommander un produit pour lequel on sait prédire qu’il sera consommé par l’individu concerné ? Un moteur qui établit ce genre de recommandations peut-il être qualifié de pertinent ? Bien que cette stratégie puisse être lucrative pour certains, il pourrait s’agir là de l’une des raisons pour lesquelles le biais de confirmation semble être si présent au sein de nos espaces numériques. Ainsi par effet miroir, nous pourrions presque utiliser cette métrique comme un indicateur de la propension d’un moteur à confirmer une trajectoire initiale.
Mais pour tenter d’aller plus loin, nous avons mené une expérience empirique, présentée et publiée à l’occasion de la conférence IJCCI en 2017[3], au cours de laquelle ont été simulées différentes techniques connues, sur des cas d’usages réels. On peut ainsi avoir une idée un peu plus précise de l’incapacité des moteurs à explorer au-delà du champ de vision initial de l’utilisateur, voire de leur propension à réduire cette portée. Pour cela nous avons introduit une mesure expérimentale, tout simplement intitulée la confirmation.
Globalement, cette expérience a montré l'incapacité des principales méthodes de recommandation à s’extraire du cluster où a été positionné l’utilisateur initialement, en restant dans la même catégorie ou dans une catégorie voisine dans plus de 92% des cas pour les méthodes de filtrage collaboratif et dans plus de 97% des cas pour les méthodes de prédiction de liens.
Il s’agit là également d’une accentuation du biais de représentativité. En diminuant le spectre initial et en présentant un sous-ensemble tronqué et orienté, l’individu n’aurait accès qu’à une facette non représentative et consensuelle de l’ensemble initial.
Algorithmes “locaux” ou “low cost”
A vouloir cibler les besoins de l’individu, sans prendre de risque, le moteur se limiterait donc à un périmètre restreint.De plus, les algorithmes dit “locaux” (c’est à dire qu’ils explorent le proche voisinage) sont relativement simples et donc assurément plus intéressants en termes de temps de calcul. Ainsi, plus la masse de données sera élevée, plus les ingénieurs pourraient être tentés d’employer ces méthodes “low cost”. Pour résumer, les méthodes les moins complexes sont également celles qui possèdent le moins de mécanismes pour explorer à grande échelle.
Il s’agit là d’un défi majeur. Par exemple, à l’issue du concours organisé en 2009 par Netflix pour améliorer la pertinence de leur moteur de recommandation, la solution gagnante n’a jamais pu être intégrée à cause de sa complexité. L’équipe d’AT&T Labs qui a élaboré cette solution, avait pourtant fait un formidable effort pour identifier et réduire un certain nombre de biais, notamment le biais de notoriété et le biais d’ancrage. Ils avaient observé que les premiers utilisateurs à noter ancrent la notation. Ceux qui arrivent ensuite notent en fonction des scores déjà fixés. Par exemple si j’ai moyennement aimé un film et que la note est déjà de 3 sur 5, j’aurais tendance à mettre 2. Si la note est de 4 sur 5, j’aurais plutôt tendance à mettre 3. Il en va de même avec certains films populaires qui bénéficient d'emblée d’un ancrage spécifique, de par leur notoriété.
Une autre équipe de chercheurs, menée par les travaux de Gediminas Adomavicius, travaillant également sur le biais d’ancrage, a proposé une solution aux antipodes : au lieu de complexifier les mécanismes d’identification et de traitement des biais, ils proposent tout simplement d’en finir avec ce système de notation[4]. Il se sont aperçus qu’au lieu de traiter des notations de type cinq étoiles, un passage au format binaire (j’aime vs. je n’aime pas) permettait de s’affranchir du biais d’ancrage et d’obtenir des recommandations plus astucieuses. Quelques temps après, Netflix abandonnait son système de notation à 5 étoiles.
Diminuer les phénomènes polarisants
Une partie de la solution serait donc d'atténuer les procédés trop polarisants, pour les remplacer par d’autres mécanismes. C’est notamment ce que nous avons tenté de faire au sein du moteur Maestro Engine, issu de ces recherches.Dans ce moteur, les interconnexions créées entre les objets sont traitées de façon équitables. Peu importe si deux chemins ont été empruntés 1000 fois ou 1 fois, lorsque le moteur sera face à un choix, le chemin singulier aura autant de chance que l’autre.
Ceci apporte un nouveau mécanisme d’exploration, car ces chemins singuliers, sont souvent des chemins qui permettent d’élargir le champ de vision et parfois même d’accéder à de nouveaux clusters. C’est aussi en faisant cela que nous sommes capables d’améliorer la mesure de confirmation, tout en gardant des mesures de pertinence élevées.
Je ne parle pas là de RMSE, mais plutôt d’une manière plus judicieuse d’évaluer la pertinence : l’A/B testing. Nous avons eu l’occasion de faire ce test chez Abilways, l’un des leaders de la formation professionnelle en France, chez qui Maestro Engine est implanté. Les résultats ont montré que le moteur sait être plus pertinent que les ciblages métiers traditionnels. De plus, on ne retrouve que 0.3% des recommandations produites par Maestro Engine, au sein des ciblages traditionnels. Ce qui, en plus de sa pertinence, démontre la complémentarité du moteur avec l’expertise métier, ainsi que sa capacité à explorer au-delà de l’horizon.
| Méthode de recommandation | Ouverture de mails
(% des emails reçus) |
Clic sur le lien vers la formation recommandée
(% des emails ouverts) |
Leads générés
(% des clics) |
| A - Ciblage métier traditionnel | 20% | 26% | 1% |
| B - Maestro Engine | 18% | 36% | 14% |
L’A/B test montre que seuls 0.3% des recommandations étaient communes entre les 2 méthodes
Ces bons résultats pour le domaine de la formation s’expliquent aussi du fait que l’algorithme utilise une métrique temporelle, qui lui permet d’estimer le rythme d’apprentissage.
L’influence de la popularité
Dans le cadre de cette précédente expérience, nous avons également mesuré l’influence de la popularité sur les méthodes de recommandation classiques.Voici ce qui a été observé : lorsque l’on utilise des méthodes de filtrage collaboratif, la proportion d’objets populaires recommandés est significativement faible. La popularité initiale des objets recommandés semble à peine avoir un effet sur le fonctionnement de ces méthodes (inférieur à 20%). Cependant, lorsque l’on utilise des méthodes de prédiction de liens, la proportion d’objets populaires recommandés est significativement grande (supérieur à 80%).
Encore une fois, les méthodes de prédiction font figure de mauvais élève. Or la popularité joue un rôle important dans certains biais, comme par exemple le biais de notoriété ou la cascade d’information.
Une cascade d’information est un biais socio-cognitif intervenant au niveau de notre intelligence collective. Elle se produit lorsque nous transmettons une information sans la vérifier, mais en la supposant véritable, pour la simple raison que beaucoup semblent y croire et que tant de monde ne peut pas se tromper.
Prenons un catalogue quelconque, par exemple l’ensemble des vidéos présentes sur une plateforme de streaming. Lorsque l’on observe la répartition des visionnages, il semblerait que l’on obtienne quasi systématiquement une répartition non uniforme, prenant souvent la forme d’une loi de Pareto, également appelée loi 20-80, où 20% des vidéos attireraient 80% des utilisateurs. Evidemment cette loi ne fixe pas cette limite à 20% : l’idée derrière ce terme étant de dire qu’il existe une minorité d’objets populaires attirant une majorité d’utilisateurs.
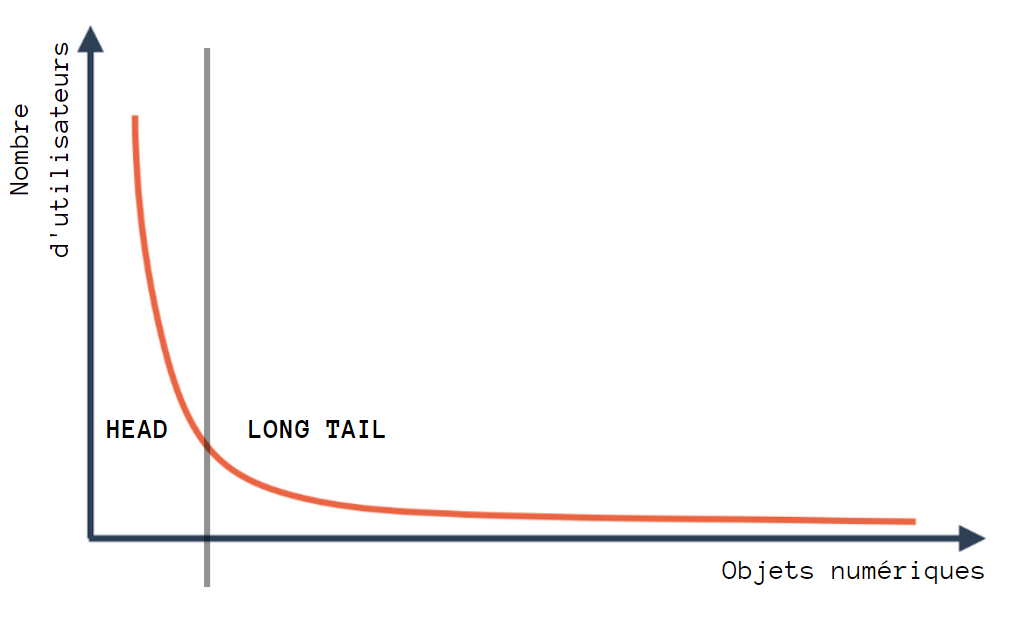
Courbe de type “loi de Pareto”
Il y a quelques années, avant l'avènement des réseaux sociaux notamment, certains observateurs, dont Chris Anderson avec le concept Head and Long Tail, prévoyaient qu’avec l'émergence du Web 2.0 et la mise à disposition de savoirs numériques pléthoriques, ces inégalités auraient tendance à se réduire. Mais aujourd’hui le constat est bien différent, et beaucoup de spécialistes de ces questions semblent s’accorder sur une tendance inverse : cette explosion combinatoire, associée à l’hyperconnectivité des individus amplifierait cette loi 20-80. Selon Lawrence Lessig, professeur de Droit à Harvard et fondateur de l’organisation Creative Commons, cela résulte de la manière dont est structurée l’offre numérique, ainsi que les mécanismes de navigation au sein de cette offre.
De plus, ces techniques d’apprentissage machine ont ceci de particulier : elles imitent nos comportements pour établir des recommandations. Le naturel nourrissant l’artificiel, puis réciproquement, le modèle évoluerait telle une boucle rétroactive, produisant un glissement continu de nos comportements, pouvant nous amener vers des formes de conformisme et d’ignorance pluraliste pour le cas de la cascade d’information, et vers des formes d'extrémisme pour le biais de confirmation et de représentativité.
Garder un esprit méthodique en toutes circonstances
Malgré ces enjeux, le débiaisage est une problématique complexe. Comme nous l’avons vu, il y a un aspect technique : débiaiser en alourdissant le calcul ou débiaiser en diminuant les phénomènes polarisants. On pourrait se dire qu’avec les progrès techniques, nous pourrions espérer faire tourner des algorithmes plus complexes à l’avenir. Mais il y a un second aspect plus philosophique : faut-il débiaiser et jusqu’à quel point ? Après tout, ces biais font partie de notre nature. De plus, dès lors que nous allons mettre en place des méthodes de réduction de ces biais, cela pourra être considéré comme une manipulation. Imaginez qu’à l’occasion d’une élection, les réseaux sociaux se mettent à créer des conditions spécifiques pour tel ou tel parti. Cela serait vu, à juste titre, comme une manipulation politique.D’une manière générale, il faudrait éviter d’évaluer nos moteurs avec des méthodes prédictives. D’autres métriques existent, mais leur utilisation reste encore marginale : diversité, ouverture, nouveauté ou encore sérendipité. Pour les mêmes raisons, la diminution des phénomènes polarisants semble être l’option à privilégier.
Fruit de la R&D, le moteur de recommandation Maestro Engine, remplace ces phénomènes par des mécanismes d’exploration (vs. exploitation des méthodes prédictives) que sont la singularité des parcours et l’analyse du rythme. Ces nouveaux mécanismes doivent rester simples, pour permettre d’une part de les faire passer à l’échelle du Big Data et d’autre part, afin de les rendre clairement intelligibles pour les intégrateurs et les utilisateurs. En effet, la transparence est un enjeu fondamental, pour éviter de tomber dans le piège de la black box, décrit récemment par Franck Pasquale, professeur de Droit et chercheur à l’Information Society Project (Yale).
Enfin, bien heureusement, l’esprit humain n’est pas systématiquement influencé par les recommandations qui lui sont faites. Il peut réagir lorsqu’il se sent pris dans ce type de dérives. Parfois même, nous pouvons aller vers ces situations en connaissance de cause, pour diverses raisons : sociales ou motivationnelles notamment. Mais cet esprit méthodique, que nous devons conserver en toute circonstance, est plus que jamais mis à l’épreuve face à ces espaces numériques vastes, hyperconnectés et automatisés.
[1] https://www.datanostra.ai/
[2] https://www.datanostra.ai/maestro/