

Dans cet article, nous allons voir comment les résultats des précédentes étapes – des objectifs clairs et un positionnement précis – vous permettront d’avoir davantage de facilités pour vous former ou pour rechercher des talents en data science.
Certains parmi vous, seront peut-être étonnés : ainsi on pourrait se former en data science sans faire de longues études en mathématique ou en intelligence artificielle ? Ne faudrait-il pas avoir un grade universitaire en sciences mathématiques : un doctorat ou, au minimum, un master ?
L’habit ne fait pas le moine, et l’axiome #3 va éliminer tous vos doutes sur ce sujet :
Axiome # 3
Il n’y a pas de corrélation
entre les compétences en data science appliquée et le niveau d’études.
La data science est un domaine très large et relativement jeune. Comme tous les domaines « disruptifs » à la mode, elle a créé, sur le marché du recrutement, beaucoup d’espoir et …beaucoup de déception autant du côté des recruteurs que des candidats : les postes en data science ont l’air cool mais on ne connaît pas encore bien le périmètre des fonctions de ce nouveau métier.
Historiquement, étant donné que ce nouveau métier nécessite des connaissances en statistiques et mathématiques, les doctorants qui ont touché ces domaines de près ou de loin pendant leurs années de thèse sont devenus la cible idéale des recruteurs. Aujourd’hui c’est un peu moins mainstream, mais il y a un an ou deux, les offres d’emplois en data science demandaient quasi systématiquement un niveau de doctorat.
Avec le temps, on a pu constater la principale limite de cette approche : les entreprises passent à côté de candidats talentueux venant d’autres domaines, notamment de l’informatique. Les formations data science en ligne ainsi que la démocratisation du machine learning avec de nombreux outils ont simplifié la reconversion de ces profils en data science. Dans un même temps, les profils venant de la recherche ne s’épanouissent pas forcément dans le privé, où les impératifs de rentabilité à court terme ne laissent pas de temps à la recherche fondamentale.
Les recruteurs ont commencé à comprendre qu’un background en statistiques et mathématiques, bien que nécessaire, n’est pas suffisant. Il faut également être capable de développer des solutions scalables, industrialiser leurs livraisons et les maintenir dans le temps. Les développeurs ont ces compétences, mais manquent de compétences en mathématiques et en méthodologie scientifique, à l’inverse des profils universitaires. C’est une belle équation à plusieurs inconnues. Comment la résoudre ? Tout dépendra du candidat et de sa curiosité.
C’est une belle équation à plusieurs inconnues. Comment la résoudre ? Tout dépendra du candidat et de sa curiosité.
J’ai pu rencontrer des développeurs logiciel qui n’ont pas fait de doctorat, mais qui ont été assez curieux pour développer leurs compétences dans les mathématiques et exceller en data science (comme Alexia Audevart ou Pascal Voitot).
Sur mon chemin, j’ai aussi croisé des chercheurs et des statisticiens qui, avant d’arriver en entreprise, ne faisaient pas d’OOP ou n’avaient jamais entendu parler de Clean Code, mais qui ont été assez curieux pour rattraper leur manque de compétence dans le développement logiciel pour eux aussi exceller en data science.
L’action # 3 en découle :
Favoriser les candidats qui sont curieux et qui n’ont pas peur de coder ou de rentrer dans le cœur des algorithmes en décortiquant les formules mathématiques !
Le critère de curiosité est le plus important, mais il ne faut pas oublier que les candidats curieux peuvent être attirés par des sous-domaines de la data science différents et avoir également une vision de la data science qui n’est pas partagée par l’entreprise. Pour éviter, des deux côtés, toute déception en cours de route, il est important de présenter aux data scientists leurs futures missions, tout en restant à l’écoute de leurs attentes et motivations.
Pour assurer une collaboration harmonieuse, les cinq éléments suivants sont importants à prendre en compte lors de la rédaction d’un plan de recrutements/formations, et à aborder lors du premier entretien avec les candidats.
1) Une roadmap data science avec des objectifs clairs.
Nous avons vu que sans avoir des objectifs bien définis, le data scientist peut toujours être productif dans votre société, mais ce qu’il produira risque de ne pas être cohérent avec votre stratégie business. Au mieux son travail sera utilisé pour renforcer un dossier CIR, ou bien il sera totalement mis au placard. Il est important que le data scientist ait connaissance de ces objectifs pour vérifier son alignement afin qu’il puisse adapter son travail.
Des objectifs clairs, s’inscrivants dans une stratégie data-science transparente, assurent l’épanouissement des data scientists dans l’entreprise. Si votre projet à moyen terme ne demande que des compétences en simples statistique descriptives ou en Data-Engineering et que le candidat ne cherche à faire que du machine learning (sans être intéressé par ces deux domaines), il vaut mieux s’en rendre compte le plus tôt possible !
En connaissant les objectifs en vue, votre positionnement dans un des domaines de la data science sera plus compréhensible pour le candidat.
Toutefois, un data scientist expérimenté pourra également, avec son regard d’expert, vous apporter des idées nouvelles et des corrections concernant votre positionnement, ce qui vous permettra d’adapter votre stratégie de recrutement !
2) Ne pas confondre la data science en entreprise avec des compétitions sur Kaggle !
Kaggle est une plateforme où les data scientists participent à des compétitions proposées par différentes sociétés et associations, et dont l’objectif est de développer le modèle le plus performant pour répondre à une problématique donnée.
C’est un excellent exercice, où l’expérimentation fait naître certaines fois des nouvelles techniques de l’état de l’art. Mais les règles du jeu de Kaggle ne prennent pas en compte les besoins et les contraintes du business : l’industrialisation et la scalabilité des solutions, le principe « release early, release often » qui permet de confronter la solution aux retours des utilisateurs.
Le data scientist expérimenté dans ce type de compétition, obsédé par la minimisation de l’erreur de prédiction de ses modèles, sans prendre en compte les spécificités du business et des retours des clients, pourra être contre-productif pour une entreprise.
En revanche, si un tel profil est conscient des contraintes data-science en entreprise, il peut profiter des compétences acquises sur Kaggle pour proposer les idées vraiment innovantes et techniquement pertinentes.
3) Créer de la valeur ajoutée perceptible par les utilisateurs.
Le but premier d’un data-scientist en entreprise n’est pas de faire de la recherche fondamentale, de publier des articles scientifiques ou de faire avancer l’état de l’art, mais bien d’accroître la valeur ajoutée d’un produit ou d’un service.
Si les solutions simples, telles que la régression linéaire ou la classification naïve bayésienne, facilement industrialisables et scalables, permettent d’atteindre ce but, elles seront adoptées.
“So much applied AI is just a really well tuned logistic regression.”
![Relatedly, I did enjoy this tidbit in The Master Algorithm: "At one point, [Naive Bayes] was the most used learner [at Google].](https://www.actuia.com/wp-content/uploads/2019/03/NaiveBayes-598x699.png) Nombre de jeunes doctorants espèrent continuer à faire de la recherche en entreprise de la même manière qu’ils l’ont fait en laboratoire ou à l’université. Mais les contraintes du business ne le permettent pas, ce qui déçoit une partie des data scientists, qui préfèrent retourner dans le domaine académique. Néanmoins, les défis technologiques, posés par ces mêmes contraintes du business, offrent l’opportunité de faire la recherche appliquée.
Nombre de jeunes doctorants espèrent continuer à faire de la recherche en entreprise de la même manière qu’ils l’ont fait en laboratoire ou à l’université. Mais les contraintes du business ne le permettent pas, ce qui déçoit une partie des data scientists, qui préfèrent retourner dans le domaine académique. Néanmoins, les défis technologiques, posés par ces mêmes contraintes du business, offrent l’opportunité de faire la recherche appliquée.
4) Maîtriser les mathématiques est obligatoire
La démocratisation de la data science ne dispense pas de l’obligation de maîtriser les sciences mathématiques et de comprendre le fonctionnement des algorithmes. Les nombreux frameworks de machine learning avec des algorithmes prêts à l’emploi, offrent plus de facilité pour exploiter les données et créer des produits enrichis grâce à l’IA. Mais les utiliser à l’aveugle, sans comprendre leurs rouages, montrera rapidement ses limites.
Pour des cas d’usage simples on pourra se contenter de trois lignes de code (comme dans la plupart des démos de ces frameworks) et fermer les yeux sur les mathématiques cachées derrière ces APIs. Mais dans la réalité, avec des cas d’usage souvent bien plus compliqués que ceux des démos, sur des projets dont les résultats auront un impact sur les utilisateurs, on doit obligatoirement avoir recours aux mathématiques. Cela ne signifie pas qu’il faudra systématiquement ré-implémenter les algorithmes de zéro, mais il faudrait pouvoir sélectionner un algorithme, optimiser ses paramètres, adapter le pré-traitement de données et définir des métriques fiables.
5) Langages pour l’expérimentation ou langages pour la production.
Certains langages de programmation sont parfaits pour l’expérimentation, d’autres seront parfaits pour la production. Pour expérimenter rien n’empêche d’utiliser un langage conçu pour la production, comme Java, Python ou Scala. En revanche, mettre en production un code écrit dans un langage pensé pour l’expérimentation, tel que R ou Matlab, sera au minimum complexe, et dans la plupart des cas impossible (en fonction de la volumétrie de données et des exigences de performances).
Par conséquent, dessiner le périmètre des fonctions du data scientist permettra de mieux identifier les compétences techniques recherchées.
C’est pourquoi, si l’on attend que le data scientist livre des modèles de machine learning en production et les conçoive de telle sorte qu’ils puissent passer à l’échelle, alors ses compétences en langages de programmation universitaires ne seront plus suffisantes.
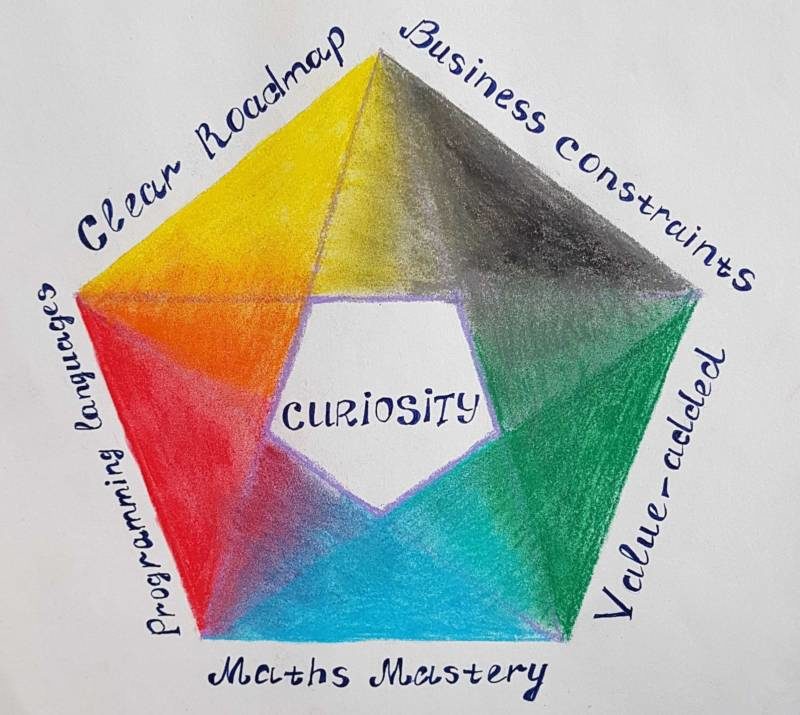 Ces cinq éléments nous font comprendre que pour une formation ou un recrutement en data science, on doit nécessairement élaborer une stratégie data science claire, définissant les objectifs et le positionnement des projets data-science, puis tracer le périmètre des missions du data scientist et dès le début être transparent sur la vision data science de l’entreprise.
Ces cinq éléments nous font comprendre que pour une formation ou un recrutement en data science, on doit nécessairement élaborer une stratégie data science claire, définissant les objectifs et le positionnement des projets data-science, puis tracer le périmètre des missions du data scientist et dès le début être transparent sur la vision data science de l’entreprise.
Au centre de ces 5 éléments, la curiosité est le facteur clé qui permettra aux data scientists passionnées de se distinguer et d’élever les projets data science vers l’excellence.









