

Cet article fait partie de la série “Make data science great again”. Tout au long de cette série, je vous propose des postulats, que j’appelle axiomes, qui vont vous donner le contexte et les orientations pour mettre en place les actions d’un projet Data-Science réussi.
Dans le 2ème article de cette série, on a vu comment mesurer le potentiel des données pour définir les bons objectifs de Data-Science pour le business. Nous allons maintenant voir comment ne pas se perdre en allant vers ces objectifs.
Comment se repérer en Data Science ?
On se perd souvent dans les nouveaux métiers qui émergent dans l’univers de la Data, surtout quand les frontières entre ces métiers ne sont pas encore stables. Comme avec la création d’une nouvelle civilisation qui passe par de multiples séparations et réunifications de régions, la civilisation de la Data vit aussi cette période de réorganisations successives.
Lors d’un atelier organisé à Montpellier en 2018, on a essayé de rendre tangible ces frontières entre les régions historiques (Data-Science, Data-Engineering, Statistique appliquée ou BI), et les nouvelles régions telles que la Data Visualisation ou Data Architecture.
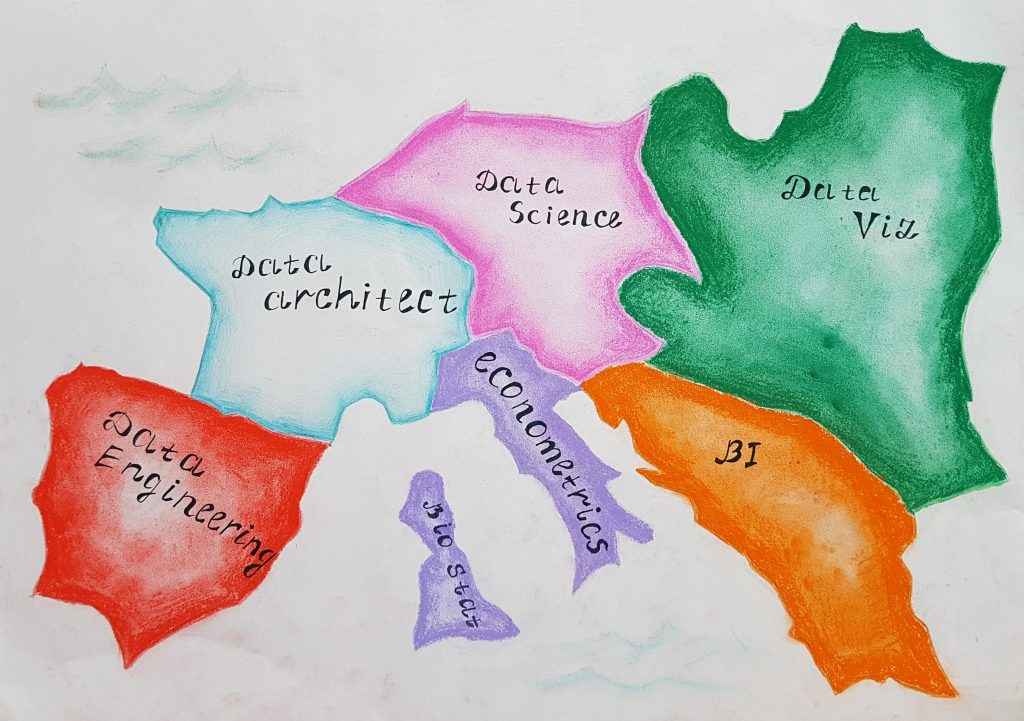
Le débat de cet atelier était vif, ce qui a prouvé encore une fois qu’on a autant d’avis que d’expériences vécues au sein de ces différents domaines. L’atelier nous a permis de cerner les points clés de chaque métier, et d’avoir une meilleure vision globale de la civilisation Data.
De nombreux articles font aussi cet effort d’expliquer les points communs et différences entre Data-Science, Data-Engineering, BI, etc. Voici ma sélection des articles les plus intéressants :
- Data Scientist vs Data-Engineer, un article de DataCamp qui donne une vision claire des différences de ces deux métiers, qui sont souvent confondus.
- Data Science vs BI, un article “Data Science? Business Intelligence? What’s the difference?” qui met en évidence les différents objectifs de ces deux métiers, qui ont de nombreux outils et méthodes en commun.
- Data-Viz vs Data-Science, un article qui expose l’importance de Data Viz et les opportunités créées par l’émergence de ce domaine.
Le présent article va se focaliser uniquement sur la Data-Science, et nous allons le voir avec Axiome #2, la Data-Science est une civilisation à part entière.
Axiome # 2
La Data-Science est un domaine pluridisciplinaire extrêmement vaste, avec un grand nombre de sous-domaines et méthodologies différentes, qui sont adaptés aux données et problématiques différentes et qui supposent des savoir-faire et des compétences différentes.
La définition sur Wikipedia ne nous aide pas trop à comprendre ce qu’est la data science concrètement.
« En termes généraux, la science des données est l’extraction de connaissance d’ensembles de données. Elle emploie des techniques et des théories tirées de plusieurs autres domaines plus larges des mathématiques, la statistique principalement, la théorie de l’information et la technologie de l’information, notamment le traitement de signal, des modèles probabilistes…. »
La liste des domaines dont la data-science emploie les techniques est très longue, et c’est compliqué d’imaginer comment un tel nombre de techniques différentes peuvent cohabiter au sein d’un domaine.
Cela devient tout de suite plus clair si on représente la Data-Science comme une fédération d’Etats. Par exemple, dans la fédération des Etats-Unis, il y a les lois au niveau fédéral, et il y a les lois propres à chaque Etat. Chaque Etat fédéral, par sa constitution, précise l’organisation de ses pouvoirs législatif, exécutif et judiciaire à son échelle. Dans le pays Data-Science, le droit fédéral des Mathématiques, des Statistiques, de l’Algèbre Linéaire prime sur les droits des Etats représentés par les méthodologies et algorithmes spécifiques à chaque domaine. Mais ce sont les droits des Etats qui dictent la routine quotidienne des data-scientists : on apprivoise des données de manière différente en fonction de là où on se situe (analyse de séries temporelles, traitement de langage naturel ou la reconnaissance vocale).
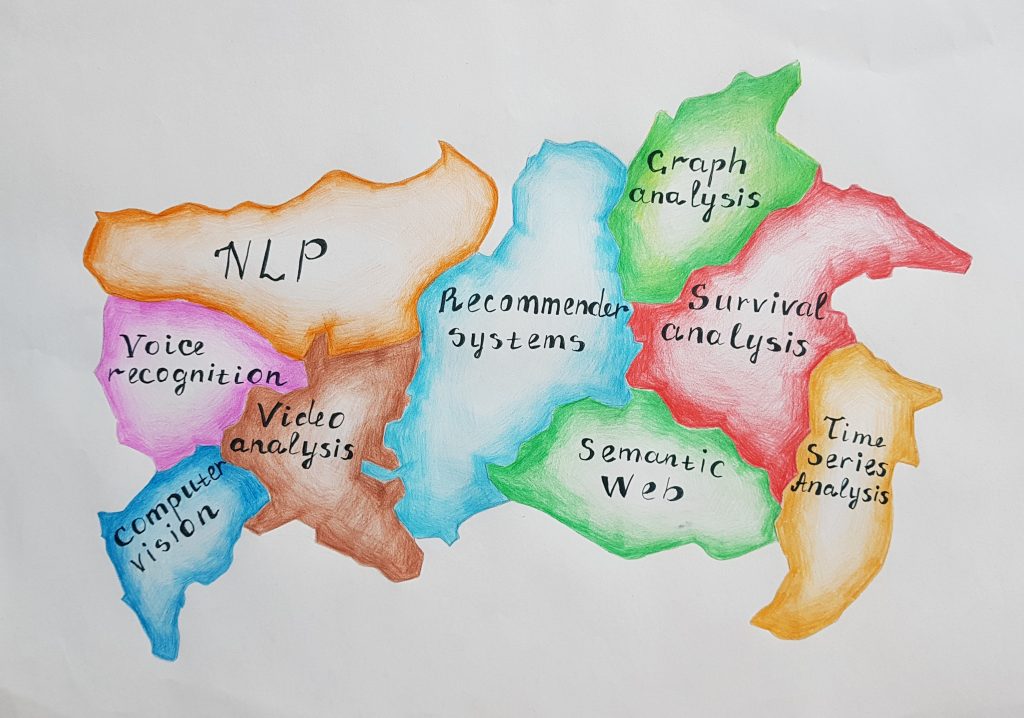
Une raison récurrente d’échec des projets Data-Science est qu’on ne sait pas dans quel État de la Data-Science se positionne le projet : plusieurs algorithmes et techniques sont essayés un peu au hasard, sans qu’aucune méthode ne soit finalement efficace. Souvent les algorithmes et techniques sont inspirés d’un domaine où ils étaient efficaces, pour être utilisés dans un autre domaine, sans forcément réfléchir aux raisons de l’efficacité de ces algorithmes dans le domaine d’origine. Cette réflexion, qui implique nécessairement la compréhension de la nature des données, mais aussi le fonctionnement intrinsèque des algorithmes, peut soit fermer la porte à un algorithme non adapté, soit donner des pistes pour un pré-traitement spécifique des données pour éventuellement s’adapter à l’algorithme choisi et profiter pleinement de ses avantages. En absence de cette réflexion, avec l’approche hasardeuse inspirée par le culte du Cargo, les projets sont condamnés à l’échec.
L’action qu’on doit donc effectuer pour ne pas se retrouver dans cette situation d’échec est tout d’abord de déterminer le domaine de Data-Science spécifique à nos données et notre métier, de se positionner sur la carte de la Data-Science.
Action # 2 : Se positionner.
Ainsi, si nos données sont constituées principalement de texte, on travaillera de préférence avec des algorithmes de traitement de langage naturel. Il existe bien entendu des exceptions à cette règle. Par exemple, l’algorithme du réseau neuronal convolutif, historiquement utilisé dans le traitement d’image, s’est récemment avéré être également efficace dans le domaine du traitement de texte. Mais il aura fallu des années de recherche pour que cette extension à un nouveau domaine soit possible…
Se positionner en Data-Science ne veut surtout pas dire qu’il faut se cloisonner à un domaine spécifique, mais plutôt qu’il faut prendre conscience et maîtriser les particularités de ses propres données. Ce positionnement ne doit pas empêcher de s’inspirer des algorithmes d’autres domaines : bien au contraire, il doit aider à faire des découvertes scientifiques. Par exemple, la réussite de plusieurs algorithmes de deep learning (RNN, LSTM) dans les domaines de l’audio et du texte, notamment pour la transcription audio ou la traduction, a inspiré les chercheurs et ingénieurs qui ont avec un grand succès utilisé ces algorithmes pour des prévisions de séries temporelles. Mais ni l’inspiration, ni le succès, n’étaient dus au hasard. Malgré la nature différente des données audio, du langage naturel et des séries temporelles, elles ont un point commun : leur caractère séquentiel est important pour les tâches de prédiction. Les algorithmes RNN et LSTM qui arrivent à bien prendre en compte la caractéristique de séquentialité dans un domaine, sont aussi efficaces dans un autre domaine pour la même raison.
Maîtriser ses propres données, faire avancer son projet rapidement grâce à des routines adaptées, et améliorer l’état de l’art en s’inspirant d’autres domaines,… Voici la liste non-exhaustive des avantages de l’action #2. Se positionner en Data-Science peut également offrir plus de facilités pour trouver des ressources, monter en compétences dans le domaine et recruter plus facilement les talents en Data Science.
Comment recruter et se former en data-science sera le sujet du prochain article de cette série.









