
Les chatbots sont très à la mode. Derrière eux se cache une grande variété de procédés visant à proposer une interface homme machine en langage naturel : de la simple expression régulière se contentant de détecter des motifs précis dans une phrase à la recherche de la compréhension du sens, en passant par des langages standardisés tels que l'AIML.
Nous avons demandé à Inbenta, société spécialisée en chatbots et en traitement du langage naturel, de nous en dire plus sur sa technologie. En se positionnant sur ce marché en pleine expansion, l'entreprise s'intéresse particulièrement au machine learning. Inbenta cherche en effet à rendre le langage naturel compréhensible par les machines grâce à l'intelligence artificielle.
Pour cela, Inbenta développe une technologie d’analyse sémantique (du sens) qui interprète des conversations formulées en langage naturel par les utilisateurs. Basée sur l'application de la théorie linguistique Sens-Texte, celle-ci permet d'interpréter une question en langage humain et d'y apporter des réponses à partir d'une base de connaissances. Quelle que soit la manière dont l'utilisateur formule sa question, le taux de bonne réponse approche les 90%.
Ce moteur de Traitement Automatique du Langage s'appuie en priorité sur une approche déterministe qui permet de contrôler le comportement de l'IA, par opposition à l'approche statistique d'autres solutions. Cette méthode offre l'avantage de produire des résultats exploitables dès la mise en production, sans nécessiter la longue phase d'apprentissage contrôlé propre aux technologies de machine learning.
Cette technologie sémantique constitue le socle sur lequel sont basées divers types d'interfaces, commercialisés en mode SaaS : InbentaBot (chatbot), FaqBot (FAQ dynamique), IndexBot (moteur d'indexation sémantique) ou encore le HomeBot (applications sur assistant vocaux type Google Home/Amazon Alexa).
Pour faire simple, le moteur de recherche, peu importe l’interface, va piocher les résultats d’une requête dans une base de connaissances, consistant en un ensemble de contenus sous forme de question/réponse. Notre algorithme est ainsi capable d’associer la requête utilisateur à la question la plus adéquate de la base de connaissances : il s'agit de "matching".
Exemples :
Comment ouvrir un compte chez MaBanque ?
-> souscrire MaBanque
-> ouvrir comte
-> souscrire une carte MaBanque
[caption id="attachment_5866" align="aligncenter" width="800"]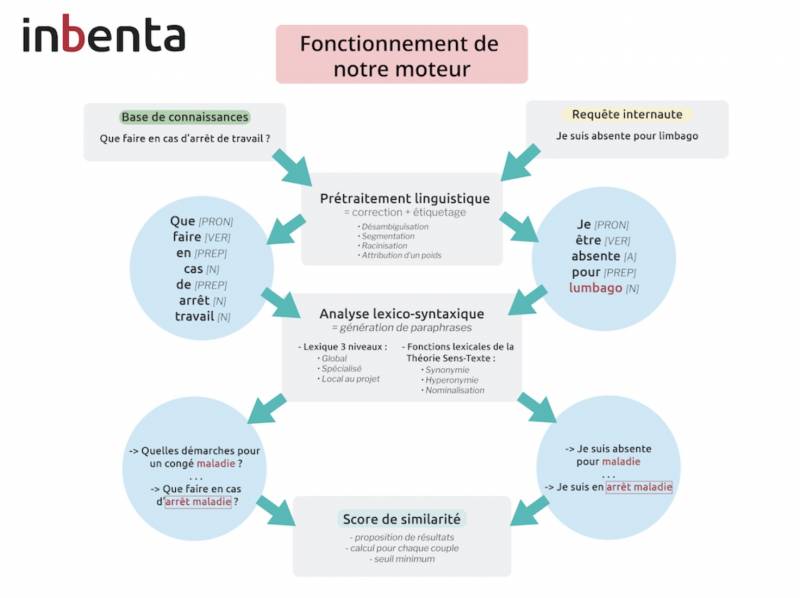 Inbenta[/caption]
Inbenta[/caption]
En amont, la requête de l'utilisateur est traitée afin de rendre possible son analyse : la phrase est découpée en mots, qui sont désambiguïsés à l’aide de règles contextuelles. Ensuite, ils sont étiquetés en fonction de leur catégorie grammaticale, et enfin, un poids est assigné en fonction de l’importance de cette dernière (pour donner de la force aux verbes et réduire l'impact des déterminants par exemple).
Exemple :
Comment puis-je déclarer mes congés payés ?
Comment [PronInter] pouvoir[V] je[PronPers] déclarer[V] mon[Det] congé[N] payé[VA] ?
Cette phase repose principalement sur le lexique : il s'agit d'un dictionnaire orienté "usage", composé d’entrées qui peuvent être des mots ou des locutions. Ces entrées sont potentiellement connectées à d’autres par des relations sémantiques (synonymie, hyperonymie, etc). Ces dernières permettent de connecter des phrases ayant un même sens tout en étant formulées de manières différentes.
Exemples :
Prix - Coût - Montant
Ouvrir un compte - Souscrire
Animal > Chien - Chat - Souris
...
Ces expansions possibles permettent de générer à la fois des paraphrases pour la requête utilisateur et pour les titres de la base de connaissances. Ces dernières sont ensuite comparées entre elles par l'algorithme de matching. Différents critères sont pris en compte, tels que la fréquence d'apparition du terme dans la base de connaissances, ou le poids attribués aux mots, afin de calculer un coefficient de similarité. La concordance est retenue au-delà d'un seuil de pertinence et des contenus sont alors suggérés à l'utilisateur.
Plus que de la suggestion de contenu, la technologie d'Inbenta est un outil d'analyse de données qui permet de mieux comprendre les interrogations des clients. L’approche statistique de ces interrogations permet de juger du taux de réponses pertinentes remontées par le moteur pour chaque question posée, du taux de satisfaction, des contenus qui retournent le plus d’évaluations positives ou négatives, de l’évolution, etc.
D’autres fonctionnalités permettent par exemple d’effectuer des regroupements de questions utilisateurs pour avoir une lecture facile et rapide de celles se référant à un même sujet. Enfin, le suivi client qu’Inbenta propose comprend des suggestions d'améliorations systématiquement basées sur des données naturellement posées par les internautes afin de modifier et enrichir la base de connaissances en fonction des besoins réels des internautes.