
Lorsqu'ils avaient présenté I-JEPA en juin dernier, les chercheurs de Meta avaient déclaré appliquer prochainement leur approche à la vidéo. C'est chose faite : Meta vient de publier V-JEPA (Video Joint Embedding Predictive Architecture), un modèle non génératif qui prédit les parties manquantes d'une vidéo grâce à l'apprentissage auto-supervisé. V-JEPA a été publié sous une licence Creative Commons Non Commercial pour que d'autres chercheurs puissent l'explorer et le développer.
En 2022, Yann LeCun avait partagé Joint-Embedding Predictive Architecture (JEPA), l'architecture sur laquelle ont été construits I-JEPA en 2023 et V-JEPA qui vient d'être publié.
Pour lui :
“Les animaux humains et non humains semblent capables d’acquérir d’énormes quantités de connaissances de base sur la façon dont le monde fonctionne grâce à l’observation et à travers une quantité incompréhensible d’interactions d’une manière indépendante des tâches et non supervisée. On peut émettre l’hypothèse que ces connaissances accumulées peuvent constituer la base de ce que l’on appelle souvent le bon sens.”
Ajoutant :“Et le bon sens peut être vu comme une collection de modèles du monde qui peuvent guider sur ce qui est probable, ce qui est plausible et ce qui est impossible”.
Selon lui, pour construire une IA de niveau humain, les systèmes doivent apprendre des “modèles mondiaux”. Dans son blog "V-JEPA: The next step toward Yann LeCun’s vision of advanced machine intelligence (AMI)", Meta explique :"En tant qu'êtres humains, une grande partie de ce que nous apprenons sur le monde qui nous entoure, en particulier dans nos premières étapes de vie, est obtenue par l'observation. Prenons la troisième loi de Newton : même un nourrisson (ou un chat) peut intuitivement, après avoir renversé plusieurs objets d'une table et observé les résultats, comprendre que ce qui monte doit redescendre. Vous n'avez pas besoin de passer des heures à être instruit ou à lire des milliers de livres pour arriver à ce résultat".
V-JEPA, un modèle non génératif
Les architectures génératives apprennent en supprimant ou en déformant des parties de l’entrée du modèle, par exemple, en effaçant une partie d’une photo ou en masquant certains mots dans un passage de texte. Elles essaient ensuite de prédire les pixels ou les mots manquants.V-JEPA n'essaie pas de combler les pixels manquants dans une vidéo. Pré-entraîné sur 2 millions de vidéos collectées à partir de jeux de données publics, il apprend à prédire les parties manquantes ou masquées d'une vidéo dans un espace de représentation abstrait, sans utiliser de données étiquetées.
Son approche non générative lui confère une grande flexibilité, lui permettant d'ignorer les informations imprévisibles et de se concentrer sur ce qui est essentiel. "Après tout, si une vidéo montre un arbre, vous n'êtes probablement pas préoccupé par les mouvements minimes de chaque feuille individuelle", souligne Meta.
De plus, sa capacité à fonctionner avec un minimum de données étiquetées après le pré-entraînement pour une tâche spécifique en fait un outil extrêmement efficace pour l'apprentissage et l'adaptation à de nouveaux domaines et tâches.
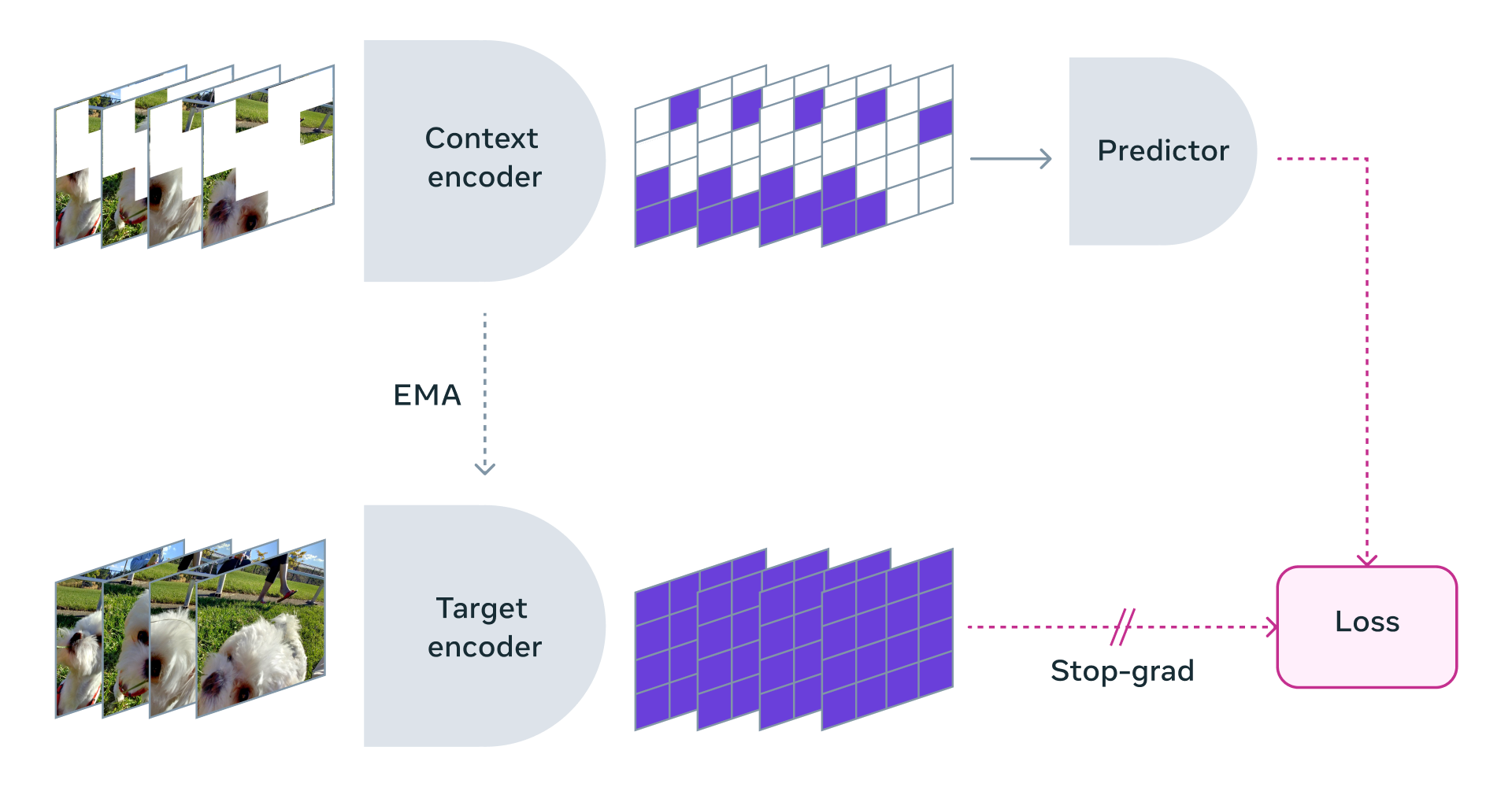
V-JEPA entraîne un encodeur visuel en prédisant des régions spatio-temporelles masquées dans un espace latent appris. Contrairement aux méthodes génératives qui ont un décodeur de pixels, V-JEPA a un prédicteur qui fait des prédictions dans cet espace latent.
L'équipe a utilisé une approche où elle masquait des parties de la vidéo à la fois dans l'espace et dans le temps, ce qui force le modèle à apprendre et à développer une compréhension de la scène.
V-JEPA peut être adapté à différentes tâches en aval, comme la classification d’actions, la reconnaissance d’interactions fines entre objets, et la localisation d’activités. L’équipe de Meta envisage d’améliorer V-JEPA en intégrant l’audio, en augmentant l’horizon temporel des prédictions, et en utilisant le modèle pour la planification et la prise de décision séquentielle. L’objectif est de construire une intelligence artificielle plus ancrée dans le monde physique et capable d’apprendre comme les humains.
Yann LeCun conclut :
"V-JEPA est un pas vers une compréhension plus approfondie du monde afin que les machines puissent atteindre un raisonnement et une planification plus généralisés. Notre objectif est de construire une intelligence artificielle avancée qui peut apprendre davantage comme le font les humains, en formant des modèles internes du monde qui les entoure pour apprendre, s'adapter et élaborer des plans efficacement dans le but de réaliser des tâches complexes".