
Les progrès de l'intelligence artificielle permettent un véritable essor technologique, notamment en matière de traduction automatique. Après la traduction statistique, le nouveau paradigme dominant est maintenant la traduction basée sur des réseaux de neurones, également appelée traduction neuronale. De nombreux articles de recherche sont publiés sur le sujet et les GAFAM s'y intéressent plus que jamais. En 2016, SYSTRAN, qui fête ses 50 ans, a lancé le premier moteur de traduction neuronal, Pure Neural® MT (PNMT®). Destiné aux professionnels et optimisé pour être toujours à la pointe, il exploite les dernières avancées en matière d'intelligence artificielle, d’apprentissage profond (deep learning) et de réseaux de neurones artificiels. Nous avons eu la chance de nous entretenir avec Jean Senellart, Directeur Technique & Innovation du groupe SYSTRAN et Gaëlle Bou, Directrice Commerciale & Marketing à ce propos.
[caption id="attachment_5693" align="aligncenter" width="800"]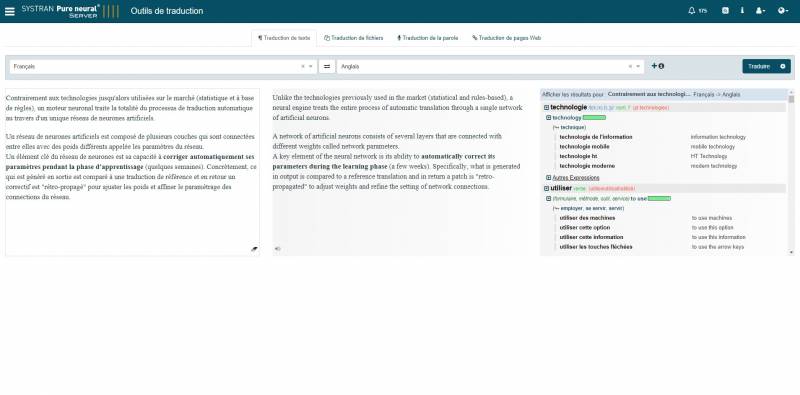 Systran[/caption]
Systran[/caption]
Les modèles neuronaux et le deep learning au service de la traduction automatique
Éditeur de logiciels spécialisé dans la traduction automatique et le traitement naturel du langage, SYSTRAN a toujours été l'un des pionniers dans le domaine et a mis sur le marché fin 2016 une nouvelle génération de solutions, basées sur un framework opensource OpenNMT développé en collaboration avec Harvard NLP. OpenNMT a notamment été récompensé par ACL 2017, la conférence mondiale des experts en linguistique informatique dans la catégorie des systèmes opérationnels.Au-delà du moteur générique, SYSTRAN propose d’optimiser les réseaux neuronaux dans un processus post entraînement, appelé "spécialisation". Cette méthode de spécialisation apporte une nette amélioration du score de qualité de la traduction en un temps record comme l'indique Jean Senellart :
« La traduction neuronale apporte indéniablement une nette amélioration de la qualité de la traduction et ce n’est qu’un début. Ce qui, de mon point de vue, est encore plus excitant, c‘est la gamme de nouvelles applications que cette technologie va offrir dans un avenir proche.Par exemple, il est déjà possible d'introduire une interaction instantanée entre le traducteur humain et la traduction neuronale, avec des interfaces de traduction prédictive et incrémentale. Ces dernières apportent des propositions plus pertinentes, au fur et à mesure des corrections effectuées par le traducteur. »
Une technologie révolutionnaire rendue open source
En lançant PNMT®, SYSTRAN a en même temps rendu open source les outils utilisés lors de son développement, comme nous l'ont indiqué Jean Senellart et Gaëlle Bou :« Un positionnement inédit pour SYSTRAN puisque c’est une société privée qui a toujours protégé son code source. Nous avons décidé de franchir le pas de l’open source car c’est le sens de l’histoire et parce que c’est toute une communauté qui participe à l’évolution de cette technologie d’excellence. Bien évidemment de notre côté nous développons autour de ce noyau technologique des fonctionnalités additionnelles, des interfaces utilisateurs et des outils de productivité qui rendent la technologie opérationnelle et facile à intégrer dans les systèmes d’information des entreprises. ».[caption id="attachment_5695" align="aligncenter" width="800"]
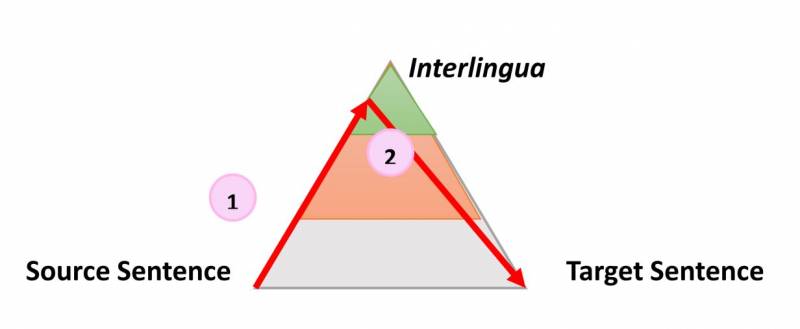 Triangle de Vauquois - Moteur de traduction neuronal - Systran[/caption]
Triangle de Vauquois - Moteur de traduction neuronal - Systran[/caption]
OpenNMT est un système de traduction neuronal Open Source, lancé en décembre 2016, et qui compte plus de 1500 utilisateurs et contributeurs issus du monde académique et industriel. Une vingtaine de chercheurs, linguistes et ingénieurs du centre R&D de SYSTRAN basé à Paris, travaillent au développement de cette plateforme et animent la communauté d’utilisateurs.
« Ce framework initialement développé par un étudiant de Harvard NLP, a été ré-écrit par les équipes R&D de SYSTRAN. Nous avons ainsi créé une dynamique de collaboration longue durée avec le groupe Harvard sur le projet OpenNMT.OpenNMT propose une interface simple d'utilisation avec des modèles et des processus d'entrainement configurables, ainsi que des extensions pour permettre de développer des modèles de résumé automatique, de traduction des images en texte ou même de reconnaissance vocale.Initialement, nous nous basions essentiellement sur le toolkit de calcul Torch initié par Facebook : nous avons d’ailleurs reçu un grand soutien de la part de leurs équipes pour l'utiliser. Puis Facebook a lancé PyTorch et nous avons donc lancé une nouvelle version d’OpenNMT pour PyTorch. Nous avons ensuite été encore plus loin car devant le succès croissant de TensorFlow, nous avons lancé une troisième version d’OpenNMT, cette fois pour TensorFlow. Aujourd’hui nous supportons donc trois frameworks totalement différents et nous sommes en train de travailler sur un quatrième : MxNet ».
« Il s'agit d'un système qui est pensé pour des développements industriels, ce n’est pas seulement un environnement expérimental. De ce fait nous avons beaucoup de développeurs de grandes entreprises, qui construisent leurs propres systèmes en se basant sur les outils OpenNMT. Par exemple, booking.com base son système de production sur OpenNMT et nous sommes ravis de collaborer avec leurs équipes. »OpenNMT réunit une communauté importante de chercheurs. Depuis un an, nous avons presque une centaine d’articles scientifiques publiés sur différentes applications, notamment la traduction automatique mais aussi la génération de textes, dont les auteurs ont utilisé OpenNMT pour leurs recherches.
SYSTRAN, de son côté, bénéficie également de cette communauté et de cette dynamique car à chaque publication intéressante sur le sujet, l’éditeur intègre les algorithmes à sa solution. Par exemple, 'Transformer', la dernière approche de Google concernant la traduction automatique, ou encore l’approche convolutionnelle créée par Facebook. Ces deux algorithmes ont été intégrés à OpenNMT pour qu’ils soient disponibles pour d’autres expériences par la suite. SYSTRAN donne des outils aux chercheurs, suit les publications, intègre de nouvelles fonctionnalités pour que la technologie reste toujours à la pointe de l’innovation.
« Maintenir un outil Open Source pour une utilisation industrielle est un challenge car cela veut dire que tout doit marcher en permanence – il n’y a pas le droit à l’abandon de fonctionnalités ou l’absence de compatibilité ascendante. Quand nous avons lancé la première version d’OpenNMT il y a un an et demi, nous nous sommes engagés à ce que les modèles entrainés à l‘époque marchent toujours aujourd’hui. Nous assurons donc aussi cette maintenance. »[caption id="attachment_5694" align="aligncenter" width="800"]
 OpenNMT[/caption]
OpenNMT[/caption]
L'apprentissage non-supervisé, l'avenir de la traduction automatique ?
L'apprentissage non-supervisé intéresse de nombreux chercheurs et ingénieurs, dans de nombreux domaines. En matière de traduction, deux articles ont eu un écho retentissant en fin d'année dernière. Deux équipes de chercheurs en informatique, l'une formée par Guillaume Lample, Ludovic Denoyer et Marc'Aurelio Ranzato à Paris, et l'autre par Mikel Artetxe, Gorka Labaka, Eneko Agirre, Kyunghyun Cho de l'Université du Pays Basque (UPV) à San Sebastian en Espagne, ont en effet réalisé des avancées particulièrement intéressantes. En utilisant l'intelligence artificielle, les chercheurs ont développé des techniques pour permettre aux réseaux de neurones de traduire entre deux langues sans avoir recours à un dictionnaire ou à une intervention humaine.SYSTRAN s'intéresse donc évidemment à cette technique mais a également un autre axe d’innovation : le training infini.
« On peut prendre l’exemple du ‘Transformer’ de Google qui déclare : « Avec ces 4 millions de phrases qui sont une référence pour tout le monde, nous arrivons à avoir un score de N+2, là où le meilleur résultat pour l’instant était de N ». Il s'agit dans ce cas de la performance de l’algorithme brut dans des conditions contraintes.Apprentissage non-supervisé, training infini, moteur de traduction experts dans différents domaines, SYSTRAN se montre ambitieux dans un secteur où les évolutions sont nombreuses. Comme l'indique Jean Senellart :Cette performance est certes importante mais ne reflète pas les problématiques industrielles. Nous sommes, chez SYSTRAN, sur une logique de long terme, plus compliquée d’un point de vue technique. Notre objectif est le suivant : sur une base de 200 millions de phrases, nous voulons que nos moteurs continuent à apprendre en permanence dans une logique de long terme. Nous les entraînons pendant 6 mois, 1 an, 2 ans, et nous nous assurons qu’ils continuent à apprendre en permanence. C’est ce qu’on appelle le training infini, c'est à dire inculquer des données supplémentaires sur du long terme. Nous avons déjà des résultats intermédiaires et nous constatons que l'algorithme n’arrête pas d’apprendre et a toujours cette capacité d’apprendre plus. Cela fait actuellement 6 mois que nous continuons d'injecter des données dans nos plus vieux moteurs. Certains modèles apprendront plus vite, d’autres moins vite, mais sur le long terme arriveront chacun à des capacités différentes non plus uniformes, mais dépendant de leur propre parcours.
Par extension, dans cette logique long terme et avec le savoir ce que ces modèles cumulent, il y a une autre logique corrélée : l’apprentissage de plusieurs langues en même temps.
Cette capacité d’apprendre plusieurs choses permet de mieux former le système neuronal. Développer un moteur spécialisé sur un domaine c’est très facile, avec 1 million de phrases vous pouvez obtenir un modèle qui sait traduire uniquement dans ce domaine de façon très précise en 3 jours. Ce que nous essayons de faire, c’est d’avoir des moteurs sur lesquels on apprend, sur du long terme, à traduire de façon générique et à potentiellement devenir des experts dans plusieurs domaines à la fois. Une question est de savoir jusqu’où nous serons capables d’entraîner un moteur qui serait générique mais qui serait bon à la fois en traduction informatique, en traduction médicale, etc.
C’est un défi important pour servir nos clients mais également un challenge intellectuel intéressant d’un point de vue recherche puisqu’il s’agit de trouver comment apprendre à des réseaux de neurones à se diversifier et à utiliser cette diversification pour devenir meilleurs. De nombreux articles sur ce sujet, dans des domaines très différents, ont été publiés. Dans le domaine des jeux par exemple, on a montré qu’on était capable d’apprendre à un réseau de neurones à jouer à un jeu mais que si on voulait lui apprendre à jouer à un deuxième jeu en même temps, il perdait une partie de son savoir sur le premier jeu. C’est ce qu’on appelle l’oubli catastrophique (catastrophic forgetting) et c'est un défi scientifique très intéressant. »
« Peut-être que demain, dans un an, dans 10 ans, on aura un moteur de traduction capable de parler six langues, de traduire aussi bien du Shakespeare que du médical et des extraits spécialisés dans le domaine légal ».Mais SYSTRAN ne se limite pas à la simple traduction et s'intéresse de très près à la convergence des différentes technologies :
« Historiquement l’intelligence artificielle a d’abord été appliquée à l’image, puis à la voix et maintenant au texte. Beaucoup de spécialistes pensent qu’il y aura une convergence de ces modalités qui permettra d’améliorer encore la qualité de traduction. Par exemple, si la machine utilise à la fois des sources vidéo et images en plus du texte, la traduction produite sera encore plus précise et adaptée au contexte.Il y a un potentiel très important sur ce sujet et il s'agit d'un enjeu fabuleux. Il pourrait y avoir plusieurs applications et plusieurs modalités en même temps au lieu de la seule traduction, notamment pour extraire de l’information ».
Un modèle économique d'un nouveau genre
Qu'une société comme SYSTRAN ait décidé de proposer en open source son moteur neuronal sur le framework OpenNMT peut étonner. Pourtant, le développement des nouveaux outils passe désormais par ce type d'environnement ouvert permettant aux acteurs de présenter leurs algorithmes au monde entier. Cela leur permet d'être actif au sein d'une communauté dynamique mais aussi de pouvoir, grâce aux échanges et aux retours des membres, disposer du code le plus optimisé possible, de nouvelles fonctionnalités et de nouveaux algorithmes, comme c'est le cas pour OpenNMT.[caption id="attachment_5692" align="aligncenter" width="700"]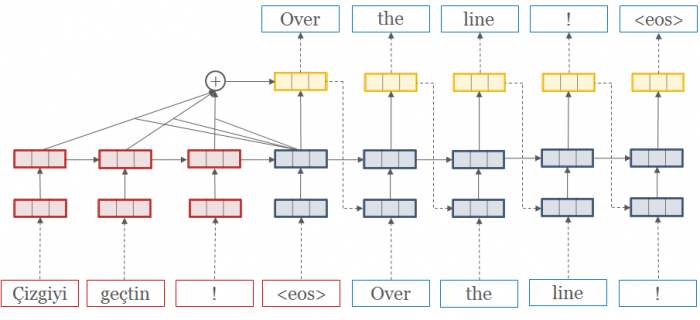 OpenNMT[/caption]
OpenNMT[/caption]
L'objectif de SYSTRAN a toujours été d'offrir aux professionnels des solutions de traduction spécialisée dans leur terminologie métier. SYSTRAN est aujourd'hui un groupe de 200 personnes dont 60 basées à Paris. En rendant open source son moteur neuronal, il fallait démontrer que ce modèle permettait également de rémunérer les chercheurs et de générer des bénéfices. La clé de cette réussite réside dans le fait que la mise à disposition d'OpenNMT s’accompagne d’une offre de services et de solutions clés en main qui répondent aux besoins d’une majorité de clients. Gaelle Bou et Jean Senellart rappelaient à ce propos :
« Nous avons été contactés par de grands groupes industriels après qu'ils aient découvert OpenNMT. Leurs équipes l’utilisaient, et ils souhaitaient savoir si nous pouvions les accompagner pour aller plus loin, car une des valeurs clé de SYSTRAN est le savoir-faire qui est indispensable pour faire de cette technologie un véritable outil de production.Plus d’informations sur OpenNMT.A l’instar d’autres éditeurs open source (Docker, Redhat…), nous sommes en train de développer toute une palette d’outils et de services autour du noyau technologique. En parallèle bien évidement SYSTRAN propose une solide gamme de solutions clés en main pour les entreprises et les organisations publiques qui connait un très beau succès et qui ne cesse d'être optimisée ».
Découvrez le serveur de démonstration Pure Neural™.
L'équipe d'ActuIA tient à remercier Jean Senellart et Gaëlle Bou avec qui nous avons eu grand plaisir à échanger.