Microsoft a récemment publié VALL-E, un nouveau modèle d’IA de synthèse vocale qui peut reproduire une voix à partir d'un échantillon audio de seulement trois secondes. Ce modèle de langage de codec neuronal, qui s'appuie sur la technologie de compression audio EnCodec présentée par l'équipe FAIR de Meta AI en octobre dernier, peut synthétiser une voix tout en conservant le timbre, le ton émotionnel et l’environnement acoustique de l'invite.
L'étude dévoilant VALL-E intitulée "Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers" a été publiée sur arXiv le 5 janvier dernier.
Les chercheurs ont entraîné leur modèle avec la bibliothèque audio LibriLight qui contient 60 000 heures de discours en anglais de plus de 7 000 locuteurs, pour la plupart extraits des livres audio de la bibliothèque numérique gratuite LibriVox.
Selon eux, VALL-E est le premier framework de synthèse vocale (TTS) ayant de fortes capacités d’apprentissage en contexte, à l'instar de GPT-3, utilisant les codes de codec audio comme intermédiaire pour remplacer le spectrogramme Mel traditionnel. Il a une capacité d’apprentissage en contexte et permet des approches rapides pour la TTS à tir zéro, et n'a pas nécessité d'ingénierie des structures, de caractéristiques acoustiques préconçues et ou de réglage fin comme dans les travaux précédents
VALL-E génère des codes de codec audio discrets à partir d’invites de phonème et de code acoustique correspondant au contenu cible et à la voix de l’orateur. Il peut être utilisé pour diverses applications de synthèse vocale, telles que la TTS zero-shot, l’édition vocale et la création de contenu combinées à d’autres modèles d’IA générative comme GPT-3.
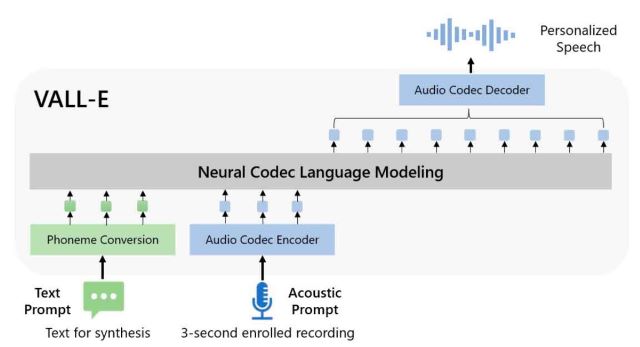
Grâce à la génération de jetons discrets basées sur l’échantillonnage, VALL-E peut synthétiser divers échantillons de parole personnalisés. On peut en retrouver des exemples sur cette page.
Si les résultats de l'étude montrent que Vall-E surpasse le système TTS zero-shot de pointe en termes de naturel de la parole et de similitude du locuteur, les chercheurs entendent à présent mettre à l’échelle les données d’apprentissage pour "améliorer les performances du modèle à travers la prosodie, le style de parole et de similitude des locuteurs".
Microsoft a indiqué que le code source n'était pas disponible étant donné que cet outil pourrait être utilisé à des fins nuisibles :
"Étant donné que VALL-E pourrait synthétiser un discours qui maintient l’identité du locuteur, il peut comporter des risques potentiels en cas d’utilisation abusive du modèle, tels que l’usurpation d’identité vocale ou l’usurpation d’identité d'un orateur spécifique. Pour atténuer ces risques, il est possible de construire un modèle de détection pour discriminer si un clip audio a été synthétisé par VALL-E. Nous mettrons également les principes de Microsoft AI en pratique lors de l’élaboration ultérieure des modèles."Référence : "Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers" arXiv https://doi.org/10.48550/arXiv.2301.02111
Auteurs : Chengyi Wang, Sanyuan Chen, Yu Wu, Ziqiang Zhang, Long Zhou, Shujie Liu,
Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, Lei He, Sheng Zhao, Furu Wei.