
En avril dernier, Stability AI annonçait la sortie bêta de Stable Diffusion XL(SDXL), et présentait en juin dernier, SDXL 0.9, son dernier ajout à la suite de modèles Stable Diffusion. La semaine dernière, la société en a publié la version améliorée en open source : SDXL 1.0.
Suite à la version limitée de SDXL 0.9, la version complète de SDXL a été améliorée pour devenir le "meilleur modèle de génération d’images ouvertes au monde" selon de Stability AI.
La sortie publique de Stable Diffusion avait été annoncée par la licorne en août 2022. Ce modèle text-to-image open source est le fruit de sa collaboration avec RunwayML, des groupes de recherche du centre Machine Vision & Learning au LMU de Munich (anciennement laboratoire CompVis à l’Université de Heidelberg), d’EleutherAI et de LAION.
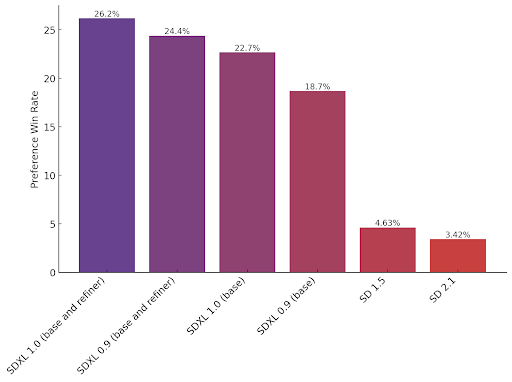
Par la suite, Stability AI a amélioré le modèle et publié Stable Diffusion 2.0 en novembre 2022. SDXL 1.0 est aujourd'hui le modèle d’image phare de Stability AI et, selon ses dires, le meilleur modèle ouvert pour la génération d’images. On peut voir les préférences des personnes ayant testé ses différents modèles ouverts sur le graphique ci-dessous.
Les points forts de SDXL 1.0 vs SDXL 0.9
SDXL 0.9 offrait déjà des résultats photoréalistes et esthétiques nettement supérieurs à ceux des versions précédentes : l’anatomie humaine est nettement mieux gérée, même si le problème des doigts subsiste parfois, la génération de portrait de style photo est, quant à elle, très réaliste.SDXL 1.0 peut générer des concepts notoirement difficiles à rendre pour les modèles d’images, tels que les mains et le texte ou les compositions arrangées spatialement (par exemple, une femme en arrière-plan poursuivant un chien au premier plan comme dans l'image ci-dessous).

Crédit Stability AI Meilleure configuration spatiale et contrôle du style, y compris le photoréalisme.
Selon Stability AI, celui-ci est particulièrement bien réglé pour des couleurs vives et précises, avec un meilleur contraste, un meilleur éclairage et de meilleures ombres que son prédécesseur, le tout en résolution native 1024x1024.
SDXL 0.9 dispose de fonctionnalités qui vont au-delà de la simple invite de texte à image, notamment l’invite d’image à image (saisie d’une image pour obtenir des variations de cette image), Inpainting (reconstruction des parties manquantes d’une image) et outpainting (construction d’une extension transparente d’une image existante),dont hérite SDXL 1.0.
Les invites sont mieux comprises que par les précédents modèles et beaucoup plus simples : quelques mots suffisent pour créer des images complexes et détaillées.
Le plus grand modèle d’image ouverte
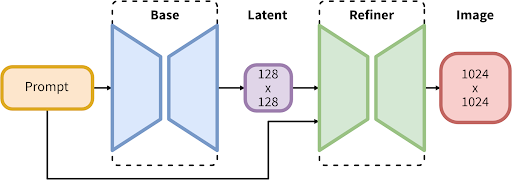
Toutes ces améliorations ont été rendues possibles du fait que SDXL 1.0 possède l’un des plus grands nombres de paramètres de tous les modèles d’images en libre accès : il a été construit sur une nouvelle architecture innovante composée d’un modèle de base de paramètres de 3,5 milliards et d’un affinement de paramètres de 6,6 milliards.Dans un premier temps, le modèle de base génère des latents (bruyants), qui sont ensuite traités avec un modèle de raffinement spécialisé pour les étapes finales de débruitage.
La start-up peaufine le contrôle d’image.
SDXL 1.0 fonctionne sur les GPU grand public avec 8 Go de VRAM ou des instances cloud facilement disponibles.
Pour démarrer avec SDXL 1.0 :
-
SDXL 1.0 est en ligne sur Clipdrop. Suivez ce lien.
-
Les poids de SDXL 1.0 et le code source associé ont été publiés sur la page GitHub de Stability AI.
-
SDXL 1.0 est également disponible pour API sur la plate-forme Stability AI.
-
SDXL 1.0 est disponible sur AWS Sagemaker et AWS Bedrock.
-
Le Discord Stable Foundation est ouvert aux tests en direct des modèles SDXL.
-
DreamStudio dispose également de SDXL 1.0 pour la génération d’images.