Au sein du CSAIL, le laboratoire d'informatique et d'intelligence artificielle du célèbre Massachussets Institute of Technology, Brandon Carter et ses collègues ont mené une étude qui a démontré que les réseaux de neurones entraînés sur des ensembles de données populaires comme CIFAR-10 et Image Net souffrent d'une surinterprétation. Cette dernière pourrait avoir des conséquences dramatiques dans le domaine de la santé ou de la conduite autonome.
Le Massachussets Institute of Technology est une célèbre université américaine de l'état du Massachusetts, située à Cambridge. Fondé en 1861 pour répondre au besoin d'ingénieurs, l'institut deviendra pluridisciplinaire, c'est aujourd'hui un centre de recherche scientifique et technique de renommée internationale d'où sont sortis de nombreux prix Nobel. Le CSAIL ou MIT Computer Science and Artificial Intelligence Laboratory est né de la fusion du Laboratory for Computer Science (LCS) et du Artificial Intelligence Laboratory (AI Lab) en 2003 et fait partie du Schwarzman College of Computing.
L'équipe de l'étude
L'étude a été réalisée par Brandon Carter, actuellement CTO de Think Therapeutics mais alors étudiant au CSAIL, axé sur l'apprentissage automatique, avec le soutien et les conseils de David Gifford, professeur de génie électrique et informatique ainsi que de génie biologique au MIT. Ce dernier a notamment développé des méthodes d'interprétabilité pour comprendre les réseaux de neurones profonds et concevoir des thérapies utilisant le ML. Siddhartha Jain et Jonas Mueller, scientifiques d'Amazon, sont venus compléter l'équipe les travaux ont été présentés à la conférence 2021 sur les systèmes de traitement de l'information neuronale qui a eu lieu en décembre dernier.L'étude
L'apprentissage automatique, et plus particulièrement le deep learning, permet de doter des systèmes informatiques de capacités d’apprentissage à partir de données grâce à l’entraînement de modèles et la conception d’algorithmes. La reconnaissance d'images s'appuie sur les réseaux de neurones convolutifs (CNN ou Convolutional Neural Network) qui vont faire correspondre une étiquette à une image fournie en entrée et qui sont actuellement les modèles de classification les plus performants. Même s'ils ont été construits à l'image du cerveau humain, les CNN sont une énigme : pourquoi prennent-ils telle décision plutôt qu'une autre?La surinterprétation
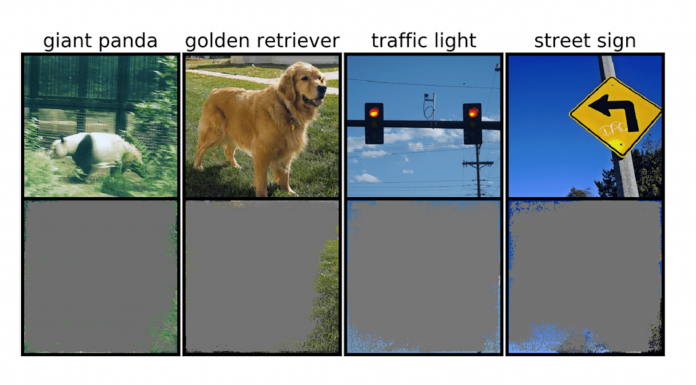
Les photos utilisées pour l'entraînement de modèles comprennent bien l'image de l'objet qui concerne l'apprentissage mais aussi de l'environnement dans lequel il se trouve : ainsi, un feu tricolore va se trouver sur un poteau, sur le bord d'une route, selon l'heure où le cliché a été pris, le ciel aura une luminosité différente... L'équipe a découvert que les réseaux de neurones entraînés sur des ensembles de données populaires tels que CIFAR-10 et Image Net souffraient d'une surinterprétation. Les modèles entraînés sur CIFAR-10, par exemple, ont fait des prédictions fiables même lorsque 95 % des images d'entrée manquaient, ce qu'un cerveau humain n'aurait pu réaliser. Brandon Carter, doctorant au Laboratoire d'informatique et d'intelligence artificielle du MIT a déclaré :"La surinterprétation est un problème d'ensemble de données causé par ces signaux absurdes dans les ensembles de données. Non seulement ces images à haute fiabilité sont méconnaissables, mais elles contiennent moins de 10 % de l'image d'origine dans des zones sans importance, telles que les bordures. Nous avons découvert que ces images n'avaient aucun sens pour les humains, mais les modèles peuvent toujours les classer avec une grande confiance".Selon l'étude, "un classificateur d'images profondes peut déterminer des classes d'images avec une confiance de plus de 90 % en utilisant principalement des bordures d'images, plutôt qu'un objet lui-même." Ce résultat pourrait être très encourageant si on ne l'utilisait que dans des domaines comme le jeu par exemple mais en revanche, pour la médecine ou les voitures autonomes, il est alarmant sachant que toute mauvaise décision peut avoir des conséquences tragiques... L'exemple donné est celui "d'une voiture à conduite autonome qui utilise une méthode d'apprentissage automatique pour reconnaître les panneaux d'arrêt, vous pouvez tester cette méthode en identifiant le plus petit sous-ensemble d'entrée qui constitue un panneau d'arrêt. S'il s'agit d'une branche d'arbre, d'une heure particulière de la journée ou de quelque chose qui n'est pas un panneau d'arrêt, vous pourriez craindre que la voiture s'arrête à un endroit où elle n'est pas censée le faire." Brandon Carter explique :
"Il y a la question de savoir comment nous pouvons modifier les ensembles de données d'une manière qui permettrait aux modèles d'être formés pour imiter plus étroitement la façon dont un humain penserait à la classification des images et donc, espérons-le, mieux généraliser dans ces scénarios du monde réel, comme la conduite autonome et le diagnostic médical, afin que les modèles n'aient pas ce comportement absurde."La conclusion de l'étude est qu'il serait judicieux de présenter aux modèles des images d'objets avec un arrière-plan non informatif...