Le modèle Window Attention Latent Transformer (W.A.L.T) a été récemment présenté par des chercheurs de l'Université de Stanford, de Google Research et du Georgia Institute of Technology. Utilisant l'architecture de réseau neuronal transformer et proposant une nouvelle approche pour les modèles de diffusion vidéo latents (LVDMs), il permet de générer des vidéos photoréalistes à partir d’images fixes ou de descriptions textuelles.
Entraîner un modèle text-to-video s'avère beaucoup plus complexe que le faire pour un modèle text-to-image. Si Stability AI a récemment présenté Stable Video Diffusion, Meta AI s'est attaqué à la génération de vidéos il y a déjà plus d'un an avec Make-A-Video, entre temps le laboratoire NVIDIA AI de Toronto avait dévoilé un modèle de synthèse Text-to-Video haute résolution basé sur le modèle Stable Diffusion open source de Stability AI. Runway et Pika Labs ont également introduit des modèles de génération de vidéos performants, l'équipe de W.A.L.T a opté pour une approche novatrice afin de surmonter les défis spécifiques liés à l'entraînement des modèles text-to-video.
https://twitter.com/i/status/1734253883076063426
L'approche novatrice de l'équipe de W.A.L.T
Les chercheurs ont tout d'abord utilisé un autoencodeur pour mapper à la fois des vidéos et des images dans un espace latent unifié de dimension réduite, ce qui permet l’apprentissage et la génération entre les modalités. En entraînant W.A.L.T dans un même temps sur des vidéos et des images, ils ont donné au modèle une compréhension plus approfondie du mouvement dès le départ.Ensuite, une conception spéciale de blocs de transformers leur a permis de modéliser la diffusion vidéo latente. Ces blocs alternent entre des couches d'auto-attention spatiale et spatiotemporelle, avec une attention spatiale limitée à une fenêtre. Cette conception offre des avantages significatifs, notamment une réduction des demandes computationnelles grâce à l'attention locale fenêtrée et la possibilité d'un entraînement conjoint pour traiter indépendamment les images et les trames vidéo.
Selon l'équipe de recherche :
"Prises ensemble, ces décisions de conception nous permettent d’atteindre des performances de pointe sur les benchmarks de génération de vidéos (UCF-101 et Kinetics-600) et d’images (ImageNet) établis sans utiliser de guidage sans classificateur".
[caption id="attachment_54467" align="alignnone" width="2213"]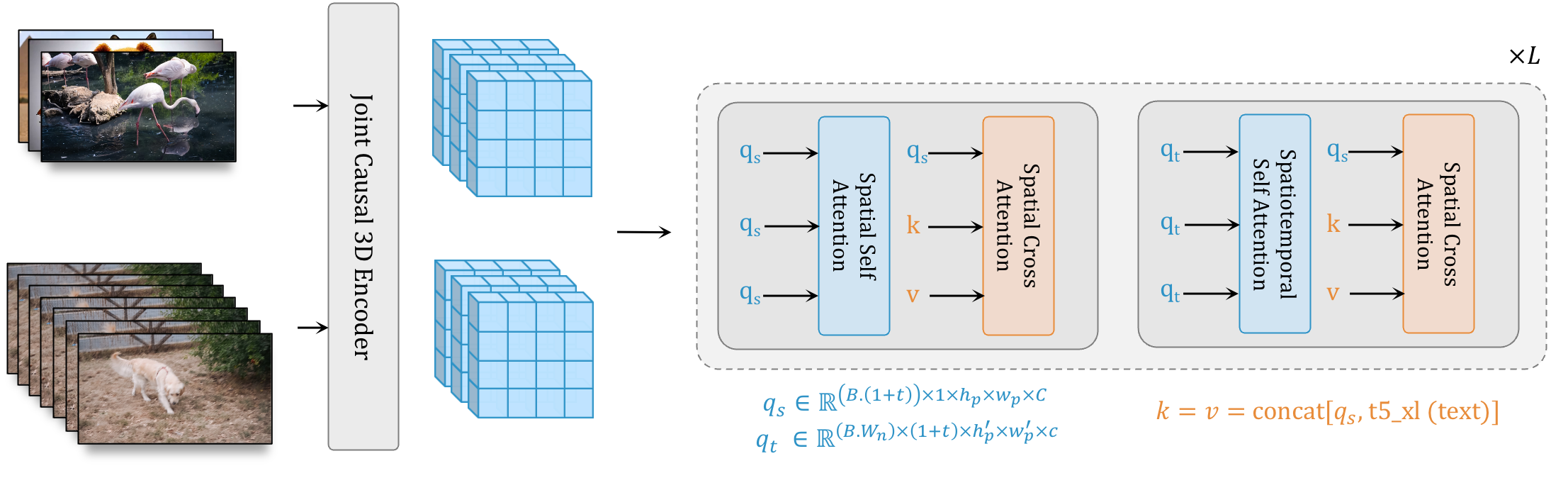 Les images et les vidéos sont encodées dans un espace latent partagé. L’épine dorsale du transformateur traite ces latents avec des blocs ayant deux couches d’attention restreinte à la fenêtre : les couches spatiales capturent les relations spatiales dans les images et les vidéos, tandis que les couches spatio-temporelles modélisent la dynamique temporelle dans les vidéos et les images de passage via le masque d’attention d’identité. Le conditionnement du texte se fait via l’attention croisée spatiale.[/caption]
Les images et les vidéos sont encodées dans un espace latent partagé. L’épine dorsale du transformateur traite ces latents avec des blocs ayant deux couches d’attention restreinte à la fenêtre : les couches spatiales capturent les relations spatiales dans les images et les vidéos, tandis que les couches spatio-temporelles modélisent la dynamique temporelle dans les vidéos et les images de passage via le masque d’attention d’identité. Le conditionnement du texte se fait via l’attention croisée spatiale.[/caption]
Les chercheurs ont entraîné une cascade de trois modèles pour la tâche de génération de texte-vidéo : le modèle de diffusion vidéo latente de base qui génère de petits clips de 128 x 128 pixels, suréchantillonné par deux modèles de diffusion vidéo en super-résolution qui produisent des vidéos d'une durée de 3,6 secondes à 8 images par seconde, atteignant une résolution de 512 x 896 pixels.
W.A.L.T démontre de solides performances notamment en terme de fluidité de l'image et semble donner raison aux chercheurs pour qui "un cadre unifié pour l’image et la vidéo comblera l’écart entre la génération d’images et de vidéos".
Source de l'article :
"Photorealistic Video Generation with Diffusion Models" arXiv:2312.06662v1
Auteurs et affiliations : Agrim Gupta1,2, Lijun Yu2, Kihyuk Sohn2, Xiuye Gu2 ,Meera Hahn2, Li Fei-Fei1, Irfan Essa2,3, Lu Jiang2, Jose Lezama 2.
1 Stanford University 2 Google Research 3 Georgia Institute of Technology