
Microsoft Research a récemment présenté Orca, un nouveau LLM open-source construit sur llama13b et a démontré que, malgré le fait qu’il n’ait "que" 13 milliards de paramètres, il atteint souvent ou dépasse les performances de ChatGPT, et que dans certains domaines, il rivalise même avec GPT-4.
Les grands modèles de fondation tels que ChatGPT et GPT-4 présentent des performances zero-shot remarquables pour un large éventail de tâches. Celles-ci peuvent être attribuées à la mise à l’échelle des tailles de modèle et du jeu de données, ainsi qu’à l’incorporation d’une deuxième couche d’entraînement pour mieux aligner les modèles avec l’intention de l’utilisateur. Cet alignement est accompli en affinant les modèles via un apprentissage supervisé et grâce à un apprentissage par renforcement.
Des recherches récentes se sont concentrées sur l'amélioration des capacités de modèles plus petits grâce à l'apprentissage par imitation, en s'appuyant sur les sorties générées par des LFM, ChatGPT et GPT-4 ont ainsi été utilisés pour Alpaca, WizardLM et Vicuna. Bien que ces derniers modèles puissent produire du contenu qui correspond au style de leurs enseignants, ils sont souvent loin du raisonnement et des compétences en compréhension affichées par les plus grands modèles de fondation.
Les chercheurs ont entraîné Orca à imiter le processus de raisonnement des LFM à partir de signaux riches provenant de GPT-4, y compris des traces d’explication, des processus de réflexion étape par étape et d’autres instructions complexes, avec l’assistance de ChatGPT.
Les résultats
Les chercheurs ont comparé les performances zero-shot de Text-da-vinci-003, ChatGPT, GPT-4, Vicuna et Orca dans le benchmark AGIEval sur des questions à choix multiples en anglais.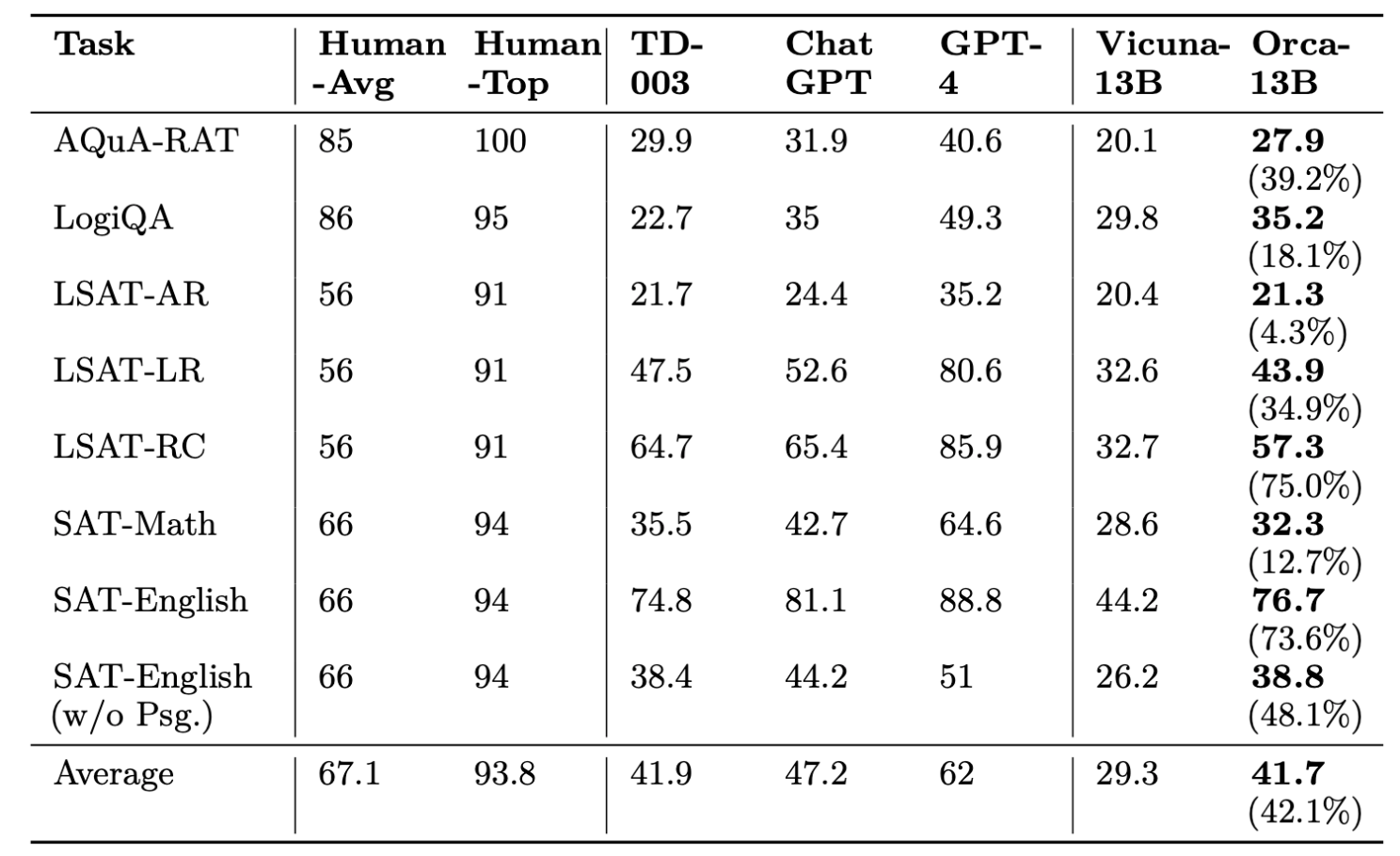
Dans l’ensemble, Orca se comporte au même niveau que Text-da-vinci-003, conservant 88% de la qualité de ChatGPT mais nettement en retard sur GPT-4. Il surpasse toutefois Vicuna de 42%.
Sur Big-Bench Hard avec un déclenchement standard zero-shot (pas d'exemple, pas de CoT), Orca se comporte légèrement mieux que ChatGPT en agrégat sur toutes les tâches, significativement en retard sur GPT-4 mais surpasse Vicuna de 113%.
Les résultats indiquent qu'Orca surpasse nettement les autres modèles plus petits en open-source. De plus, dans certains contextes, il peut égaler ou même dépasser la qualité de ChatGPT, bien qu'un écart substantiel avec GPT-4 subsiste.
Cependant, tout comme les autres LLM, il peut comporter des biais présents dans les données sources. Les chercheurs avertissent également du fait que "Ce modèle est uniquement conçu pour des environnements de recherche et ses tests n’ont été effectués que dans de tels environnements. Il ne doit pas être utilisé dans des applications en aval, car une analyse supplémentaire est nécessaire pour évaluer les risques potentiels ou les biais dans l’application proposée.”
Cette étude suggère toutefois que des modèles plus petits peuvent être entraînés pour être plus concentrés et adaptables dans des contextes contraints sans perte substantielle de qualité.
Référence : Orca: Progressive Learning from Complex Explanation Traces of GPT-4 arXiv : 2306.02707v1
Auteurs : Subhabrata Mukherjee, Arindam Mitra, Ganesh Jawahar, Sahaj Agarwal, Hamid Palangi, Ahmed Awadallah, Microsoft Research