

Moins d’un mois après le lancement de ChatGPT, Open AI publie, dans Arvix, Point·E : « Un système pour générer des nuages de points 3D à partir d’invites complexes C. Cette IA générative associe un modèle d’IA texte-image à un modèle image-3D pour modéliser un objet en seulement 1 à 2 minutes sur un simple GPU. Parallèlement à l’article, Open AI a également publié le code sur GitHub.
Les modèles d’Open AI, que ce soit GPT-3, qui effectue une variété de tâches en langage naturel, Codex, qui traduit le langage naturel en code, ou DALL· E, génératrice d’images originales, ont tous connu le succès. Après la génération d’images, Open AI s’intéresse à la modélisation 3D qui est aujourd’hui utilisée dans de nombreuses applications notamment pour le design industriel, les jeux vidéo ou la réalité virtuelle.
Point·E ne crée pas réellement des objets, il génère des nuages de points qui représentent une forme 3D. Le « E » signifie « efficacité » car il est beaucoup plus rapide que les systèmes existants comme Google DreamFusion à qui il faut une grosse puissance de calcul et plusieurs heures pour générer des modèles 3D tandis que POINT-E n’a besoin que d’un GPU et une à deux minute de travail. Par contre, si les nuages de points sont plus faciles à synthétiser, ils ne capturent pas la forme ou la texture fine d’un objet, ce qui est d’ailleurs la limitation majeure du nouveau modèle text-to-3D.
Les IA génératrices d’images ont été entraînées sur des milliards de paires image-texte. L’adaptation de cette approche à la synthèse 3D se heurte au manque d’ensembles de données 3D à grande échelle.
Les chercheurs d’Open AI ont choisi de combiner un modèle texte-image avec un modèle image-3D. Tandis que leur modèle text-to-image s’appuie sur un vaste corpus de paires (texte, image) lui permettant de suivre des invites diverses et complexes, le modèle image-3D est formé sur un jeu de données de paires (image, 3D) plus restreint.
Pour le modèle texte-image, ils ont utilisé un modèle GLIDE affiné sur les rendus 3D (plusieurs millions d’images d’objets 3D et les informations explicatives les concernant) et pour le modèle image-3D, une pile de diffusion de modèles qui génèrent des nuages de points RVB.
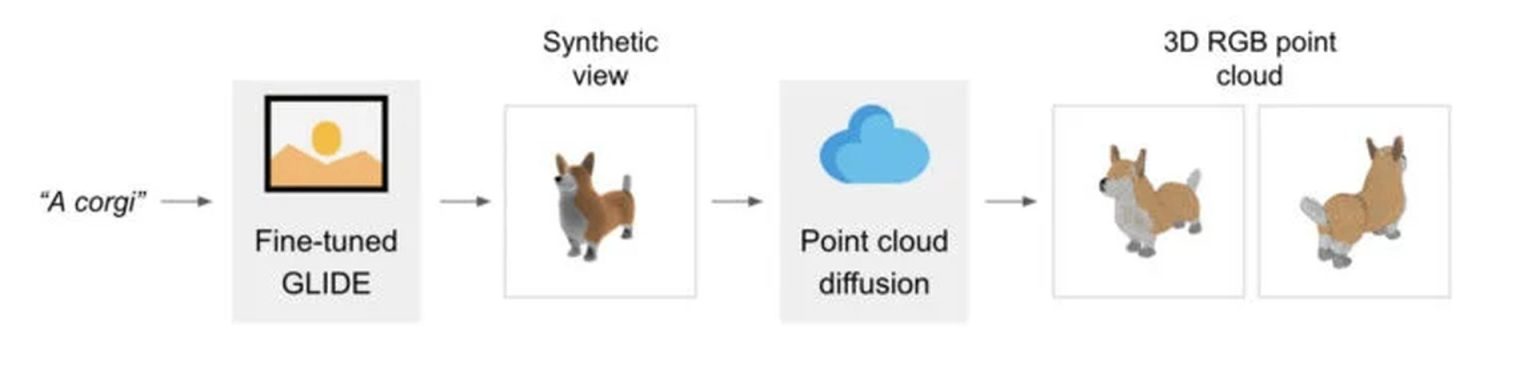
D’un nuage de points grossier (1 024 points) conditionné par la vue synthétique, les chercheurs ont réussi à produire un nuage à points fins (4 096 points).

Pour les évaluations basées sur le rendu, ils ont produit des maillages à partir de nuages de points générés à l’aide d’une approche basée sur la régression.
Bien que très performant, Point·E a ses limites et l’équipe présente 2 modes de défaillances de son modèle :

Les chercheurs espèrent que leur approche pourra servir de point de départ pour d’autres travaux dans le domaine de la conversion du texte en 3D synthèse. Il est possible d’obtenir une démonstration sur : https://huggingface.co/spaces/openai/point-e
Sources de l’article :
Point·E: A System for Generating 3D Point Clouds from Complex Prompts, https://arxiv.org/pdf/2212.08751.pdf
Auteurs :
Alex Nichol , Heewoo Jun, Prafulla Dhariwal , Pamela Mishkin , Mark Chen.
Le code : https://github.com/openai/point-e