Sommaire
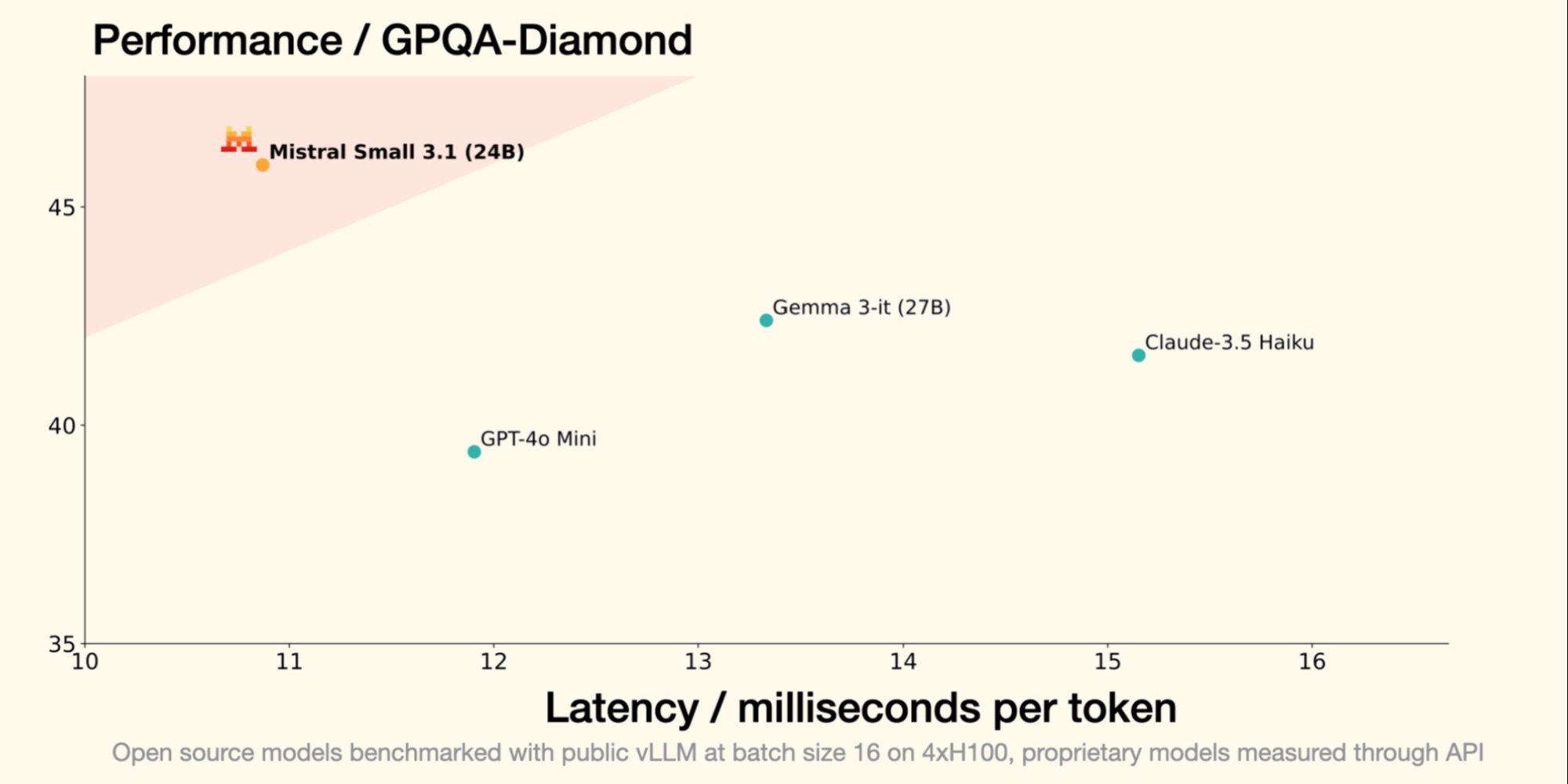
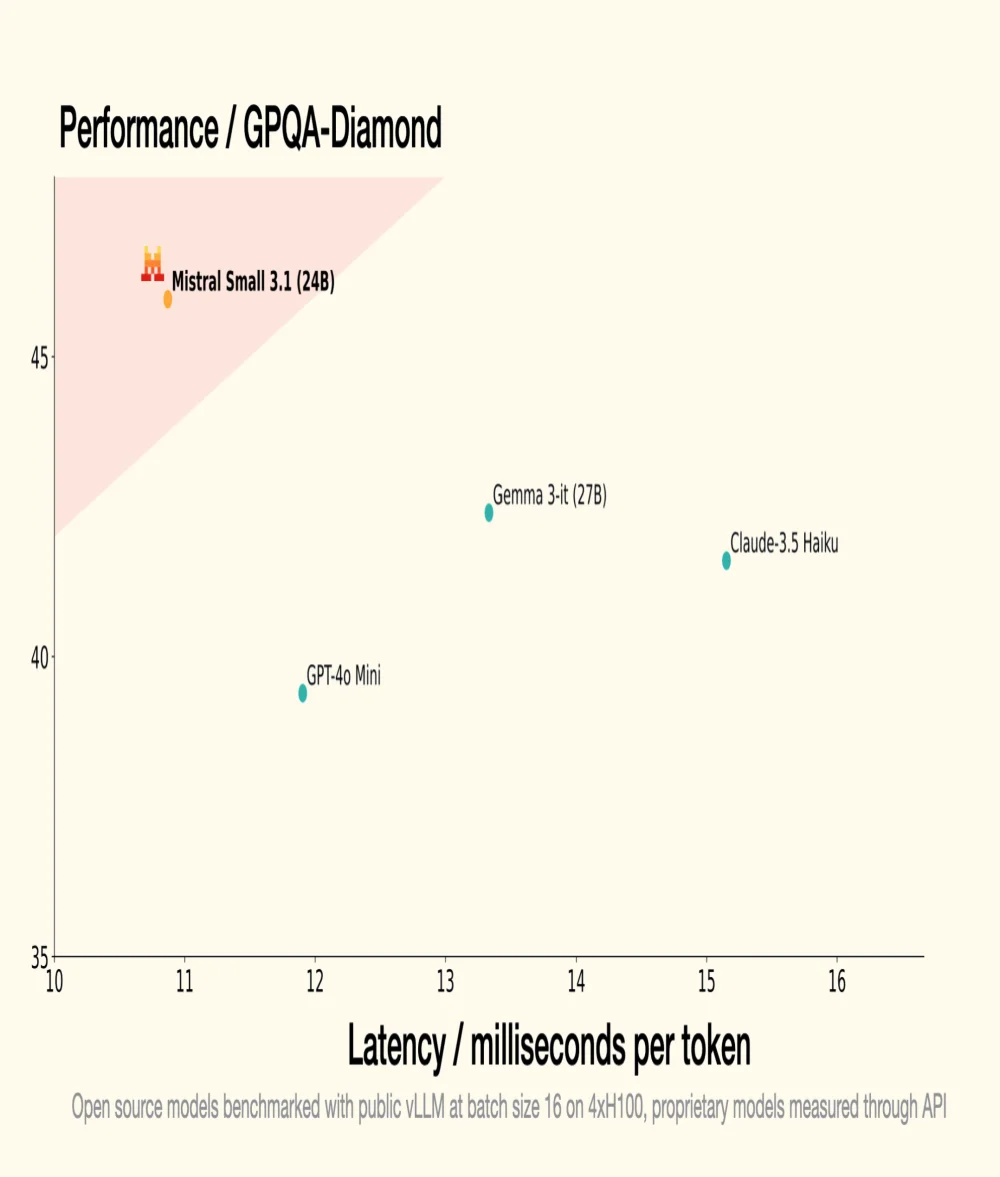
Le 30 janvier dernier, Mistral AI, licorne française de la GenAI, introduisait Small 3, un LLM de 24 milliards de paramètres, démontrant que pour être performant, un LLM ne requiert pas un nombre astronomique de paramètres. Small 3.1, son successeur, conserve une architecture compacte tout en introduisant des améliorations significatives en termes de performance, de compréhension multimodale et de gestion des contextes longs, surpassant ainsi des modèles comme Gemma 3-it 27B de Google et GPT-4o Mini d'OpenAI.
Source: Mistral AI
Optimisation des performances
- Une version instruite, Mistral Small 3.1 Instruct, prête à être utilisée pour des tâches conversationnelles et de compréhension du langage ;
- Une version préentraînée, Mistral Small 3.1 Base, idéale pour le fine-tuning et la spécialisation sur des domaines spécifiques (santé, finance, juridique, etc.).
- Il dépasse GPT-4o Mini d'OpenAI dans des benchmarks comme MMLU, HumanEval et LongBench v2, notamment grâce à sa fenêtre contextuelle étendue à 128 000 tokens ;
- Il surpasse également Claude-3.5 Haiku dans des tâches complexes impliquant des contextes longs et des données multimodales;
- Il excelle face à Cohere Aya-Vision (32B) dans des benchmarks multimodaux comme ChartQA et DocVQA, démontrant une compréhension avancée des données visuelles et textuelles ;
- Small 3.1 affiche des performances élevées en multilinguisme, surpassant ses concurrents dans des catégories comme les langues européennes et asiatiques.
Pour mieux comprendre (assisté par l'IA)
Qu'est-ce qu'un LLM (Large Language Model) en termes de technologie et de fonctionnement ?
Un LLM est un modèle d'intelligence artificielle conçu pour comprendre et générer du langage naturel. Il est composé de milliards de paramètres qui sont ajustés grâce à l'entraînement sur de grandes quantités de texte pour prédire le mot suivant dans une phrase. Les LLMs sont utilisés pour des applications comme la traduction automatique, le résumé de texte, et les agents conversationnels.
Qu'est-ce que la licence Apache 2.0 et pourquoi est-elle importante pour les projets open source ?
La licence Apache 2.0 est une licence de logiciel libre qui permet aux utilisateurs de faire d'importantes modifications et d'utiliser le logiciel à des fins commerciales ou privées tout en accordant des brevets. Elle est importante car elle assure que les contributions restent libres et accessibles, stimulant l'innovation et l'adoption de nouvelles technologies.