
Les grands modèles de langage (LLM) présentent des capacités impressionnantes dans différents domaines mais les modèles plus petits (SLM) sont une alternative intéressante pour les entreprises qui peuvent les exploiter à moindre coût pour des tâches spécifiques. Microsoft, qui a introduit le SLM Phi-1 en juin 2023, a présenté le 23 avril dernier la famille de modèles ouverts Phi-3. Le plus petit d'entre eux, Phi-3 mini, d'ores et déjà disponible, compte 3,8 milliards de paramètres et, grâce à sa petite taille, peut être déployé en local sur un téléphone ou un ordinateur.
Microsoft présente les modèles Phi-3 comme "les modèles de langage de petite taille les plus performants et les plus rentables disponibles".
Phi-3 Mini est un modèle de transformateur avec décodeur dense, affiné grâce au fine-tuning supervisé (SFT) et l’optimisation directe des préférences (DPO) pour garantir l’alignement avec les préférences humaines et les directives de sécurité. Il est disponible sur Azure AI Studio, Hugging Face et Ollama.
Il a été entraîné pendant sept jours sur 512 GPU NVIDIA H100 Tensor Core, NVIDIA nous a d'ailleurs précisé qu'il était possible de l'essayer sur ai.nvidia.com où il sera packagé en tant que NVIDIA NIM, "un microservice avec une interface de programmation d'application standard qui peut être déployé n'importe où".
Dans leur rapport technique, les chercheurs expliquent que "L’innovation réside entièrement dans notre jeu de données pour l’entraînement, une version agrandie de celle utilisée pour PHI-2, composé de données web fortement filtrées et de données synthétiques".
Le modèle, entraîné sur 3,3 trillions de jetons, a également été aligné pour la robustesse, la sécurité et le format de chat. Sa fenêtre contextuelle, qui peut aller de 4 000 jusqu'à 128 000 jetons, lui permet d’assimiler et de raisonner sur des contenus textuels volumineux (documents, pages Web, code...). Selon Microsoft, Phi-3-mini démontre de solides capacités de raisonnement et de logique, ce qui en fait un bon candidat pour les tâches analytiques.
Des performances solides malgré une petite taille
Microsoft a partagé dans son blog les performances de Phi-3 mini, mais également celles de Phi-3-small (7B) et Phi-3-medium (14B) qui seront prochainement disponibles et ont été entraînés sur 4,8 trillions de tokens.Les performances des modèles Phi-3 ont été comparées à celles de Phi-2, Mistral-7b, Gemma-7B, Llama-3-instruct-8b, Mixtral-8x7b, GPT-3.5 Turbo et Claude-3 Sonnet. Tous les chiffres déclarés sont produits avec le même pipeline afin qu'ils soient effectivement comparables.
Phi-3-mini surpasse Gemma-7B et Mistral-7B sur certains benchmarks de référence comme MMLU, tandis que Phi-3-small et Phi-3-medium, nettement plus performants, surpassent les modèles beaucoup plus grands, y compris GPT-3.5 Turbo. Cependant, du fait de leur petite taille, les modèles Phi-3 sont moins compétitifs pour les tâches axées sur les connaissances factuelles, telles que celles évaluées dans TriviaQA.
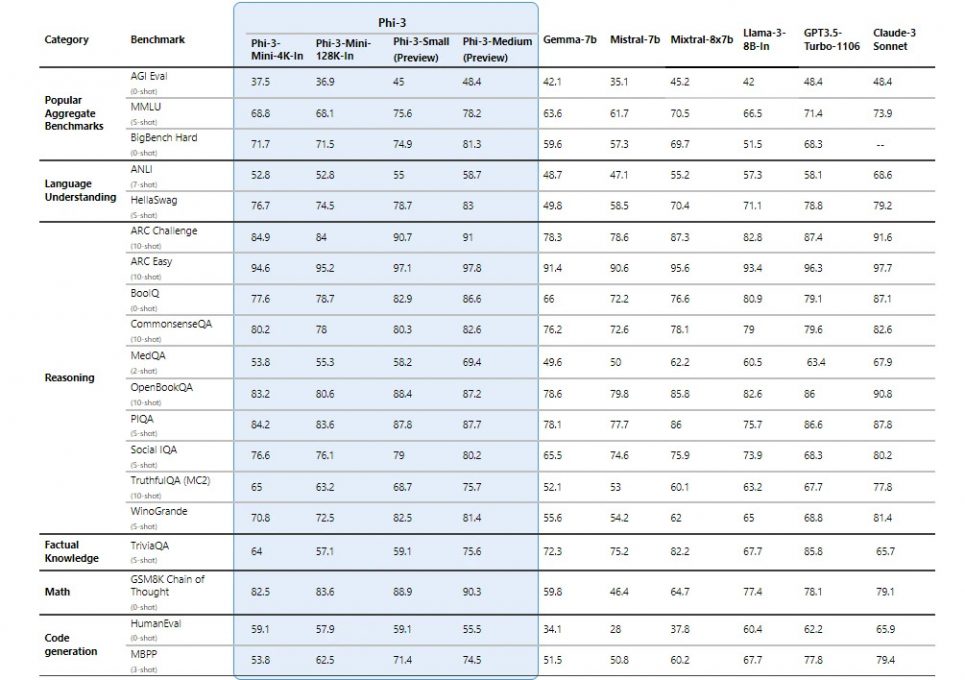
Toutefois, leurs capacités dans de nombreux autres domaines, les rendent particulièrement utiles dans des scénarios où la taille du modèle et les ressources disponibles sont des facteurs critiques, comme dans les environnements à ressources limitées ou les applications nécessitant des temps de réponse rapides.