
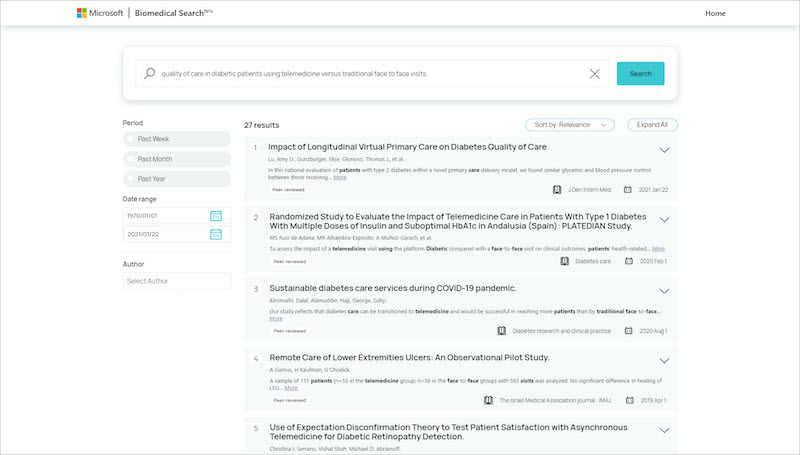
Microsoft a présenté en ce mois de mars Microsoft Biomedical Search, un outil aux chercheurs permettant d’effectuer des recherches dans toute la littérature biomédicale avec des requêtes en langage naturel plutôt que des mots-clés. Ce prototype est le résultat des efforts engagés depuis le début de la pandémie avec la création du COVID-19 Open Research Dataset (CORD-19) et d’une liste de questions représentatives des besoins croissants en information des biologistes et des cliniciens réalisée avec la Cleveland Clinic.
Les outils de recherche et d’extraction d’information scientifique ont un rôle fondamental pour la recherche. Cela a été mis en évidence dans la lutte contre la pandémie actuelle. Les équipes de Microsoft se sont appuyées sur leurs travaux pour CORD-19 et avec la Cleveland Clinic. Dans une publication sur le blog de Microsoft, Eric Horvitz a expliqué :
“Avec Microsoft Biomedical Search, nous avons rassemblé de grands ensembles de données de littérature biomédicale, des charges de travail de requête représentatives et des avancées dans les modèles de langage neuronal à grande échelle pour améliorer la recherche biomédicale. En particulier, nous avons recherché des fonctionnalités qui permettent aux chercheurs de mieux spécifier ce qu’ils signifient avec la précision du langage naturel.
Microsoft Biomedical Search met en lumière les résultats les plus pertinents de plus de 20 millions de documents de CORD-19, Microsoft Academic, PubMed et PubMed Central et repose sur les modèles PubMedBERT, MetaAdaptRank et SaliencyMeasure.
PubMedBERT est un modèle de langage à grande échelle qui a été pré-entrainé sur du texte biomédical plutôt que sur un mélange de langage du domaine général et de langage spécifique à un domaine. Le modèle a été pré-entrainé depuis zéro sur 3 milliards de mots spécifiques à la biomédecine. Nous avons constaté que le modèle surpasse tous les modèles de langage antérieurs sur les applications biomédicales de traitement du langage naturel.
MetaAdaptRank aide à déterminer avec précision la pertinence en tempérant les problèmes courants associés au classement des résultats de recherche de recherche. Les systèmes de recherche d’informations échouent souvent à identifier toutes les informations pertinentes car les requêtes et les documents utilisent des termes différents pour décrire le même concept. Par exemple, cette discordance peut se produire lorsqu’un chercheur ne connaît pas la nouvelle terminologie. MetaAdaptRank peut apprendre la sémantique de domaines spécialisés pour classer plus précisément les résultats, même pour des sujets ou des mots-clés pour lesquels les informations sont rares.
SaliencyMeasure utilise l’apprentissage par renforcement pour prédire l’importance future probable d’un article scientifique, ce qui aide à équilibrer le classement des publications ou des auteurs plus anciens et récents plutôt que de se fier uniquement à des citations”.