
Apple semble combler son retard par rapport à Microsoft, Google ou Meta en matière de GenAI. Après le LLM multimodal Ferret open source présenté en octobre dernier, ses chercheurs ont collaboré avec ceux l’Université de Californie à Santa Barbara pour développer le modèle MGIE (MLLM-Guided Image Editing), qui permet de modifier des images à partir d'instructions textuelles. L'équipe a présenté ses travaux dans un article sur arXiv qui a été sélectionné pour la Conférence internationale sur les représentations de l’apprentissage 2024 (ICLR).
Les modèles de langage multimodaux de grande taille (MLLMs) peuvent comprendre naturellement les images en entrée et fournir des réponses qui tiennent compte de la visualisation, agissant ainsi comme des assistants multimodaux.
Pour trouver une solution au défi rencontré lorsque les instructions données aux modèles d'édition d'image ne sont pas assez détaillées ou précises pour produire les résultats souhaités, MGIE utilise un MLLM et un modèle de diffusion pour dériver des instructions précises et fournir un guidage visuel explicite. En s'appuyant sur l'imagination visuelle, MGIE interprète l'intention derrière les invites ambiguës pour produire rapidement des modifications d'image cohérentes et pertinentes.
Par exemple, il peut comprendre une invite telle que "sain" en se basant sur le contexte pour effectuer des éditions appropriées, comme ajouter des garnitures de légumes à une pizza.
Il est également possible d'ajuster le contraste d'une image, d'en supprimer des éléments ou d'y en ajouter, et d'effectuer des modifications plus courantes telles que le recadrage, le redimensionnement, la rotation, le retournement et l’ajout de filtres.

Le MLLM est initialisé à partir de LLaVA-7B , tandis que le modèle de diffusion est initialisé à partir de StableDiffusion-v1.5. Les chercheurs mettent ensuite à jour conjointement ces deux modèles pour la tâche spécifique de l'édition d'image.
[caption id="attachment_55495" align="alignnone" width="3183"]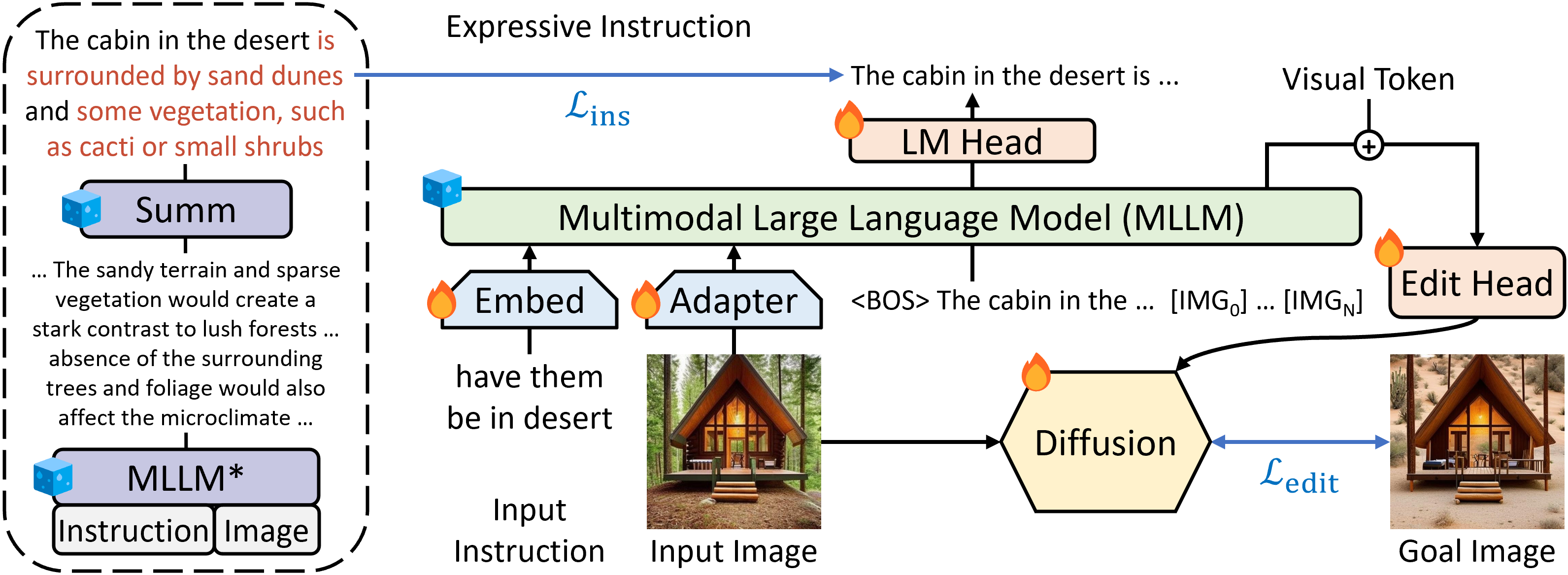 Vue d'ensemble de l'Édition d'Image Guidée par MLLM (MGIE), qui exploite les MLLMs pour améliorer la modification d'image basée sur les instructions. MGIE apprend à dériver des instructions expressives concises et fournit un guidage explicite lié à la visualisation pour l'objectif visé. Le modèle de diffusion est entraîné conjointement et réalise la modification d'image avec l'imagination latente à travers la tête de modification de manière bout à bout. et montre que le module est entraînable et figé, respectivement.[/caption]
Vue d'ensemble de l'Édition d'Image Guidée par MLLM (MGIE), qui exploite les MLLMs pour améliorer la modification d'image basée sur les instructions. MGIE apprend à dériver des instructions expressives concises et fournit un guidage explicite lié à la visualisation pour l'objectif visé. Le modèle de diffusion est entraîné conjointement et réalise la modification d'image avec l'imagination latente à travers la tête de modification de manière bout à bout. et montre que le module est entraînable et figé, respectivement.[/caption]
Evalué sur différents aspects de l'édition d'images, tels que la modification de style Photoshop, l'optimisation globale de la photo et l'altération locale des objets, sur plusieurs jeux de données, MGIE montre des améliorations significatives par rapport aux méthodes de base en termes de métriques automatiques et d'évaluation humaine.
Pour les chercheurs, il permet une retouche d’image raisonnable et peut contribuer à de futures recherche sur la vision et le langage.
Il est accessible sur GitHub et une démo web sur Hugging Face Spaces.
Références de l'article :
"Guiding instruction-based image editing via multimodal large language models"
Auteurs :
Tsu-Jui Fu1, Wenze Hu2, Xianzhi Du2, William Yang Wang1, Yinfei Yang2, Zhe Gan2
1Université de Californie à Santa Barbara, 2 Apple