
Meta a présenté hier la famille de modèles Llama 3.1 : Llama 3.1 8B et Llama 3.1 70B, deux versions améliorées de Llama 3 7B et Llama 3 70B présentés en avril dernier, mais également Llama 3.1 405B. Ce nombre impressionnant de paramètres, alors que la tendance ces derniers temps est aux modèles plus légers, fait de ce dernier le plus grand modèle open source à ce jour.
Meta Llama 3.1 405B est, comme les deux précédents modèles de la famille Llama 3, un modèle textuel. Pour l'entraînement, Meta a utilisé le même ensemble de données publiques, totalisant plus de 15 000 milliards de jetons, soit 7 fois plus que celui de Llama 2. Il compte également plus de données non anglaises, plus de données mathématiques et de code ainsi que de données Web récentes.
Les trois versions de la nouvelle famille sont aujourd'hui multilingues (anglais, allemand, français, italien, portugais, hindi, espagnol et thaïlandais), disposent d'une fenêtre contextuelle pouvant aller jusqu'à 128 000 jetons et de capacités de raisonnement renforcées. Meta a également apporté des modifications à sa licence, permettant aux développeurs d'utiliser les résultats des modèles Llama, y compris le 405B, pour améliorer d'autres modèles.
Les trois modèles sont à la disposition de la communauté en téléchargement sur llama.meta.com et Hugging Face.
Optimisations techniques
L’entraînement de Llama 3.1 405B a représenté un défi technique majeur en raison de sa taille. Pour mener à bien ce processus, Meta a optimisé sa pile d'entraînement complète et utilisé plus de 16 000 GPU H100. Cette infrastructure massive a permis d’entraîner le modèle sur une échelle sans précédent et d’obtenir des résultats en un délai raisonnable.Meta a opté pour une architecture de modèle de transformateur standard uniquement avec décodeur avec des adaptations mineures pour maximiser la stabilité de la formation. Cette approche a été préférée à celle des modèles composés d'experts, qui peuvent être plus complexes à gérer et moins stables.
Amélioration des procédures de post-entraînement
Meta a adopté une procédure de post-entraînement itérative, où chaque cycle utilise un réglage fin supervisé et une optimisation directe des préférences. Cela a permis de créer des données synthétiques de haute qualité pour chaque cycle, améliorant ainsi les performances du modèle sur toutes ses capacités.Comparée aux versions précédentes de Llama, la qualité des données pour le pré-entraînement et le fine-tuning a été considérablement améliorée grâce à des pipelines de prétraitement plus soignés et des approches de filtrage rigoureuses.
Inférence et quantification
Pour prendre en charge l'inférence de production à grande échelle, Meta a quantifié ses modèles de 16 bits (BF16) à 8 bits (FP8). Cette quantification réduit efficacement les exigences de calcul, permettant au modèle de s'exécuter sur un seul nœud de serveur, une optimisation cruciale pour déployer des modèles aussi grands dans des environnements de production tout en contrôlant les coûts et les ressources nécessaires.Performances de Llama 3.1 405B
Meta a évalué les performances du modèle sur plus de 150 jeux de données de référence couvrant de nombreuses langues. Des évaluations humaines approfondies ont également été réalisées pour le comparer à des modèles concurrents dans des scénarios réels.Les résultats montrent que Llama 3.1 405B est compétitif avec les principaux modèles de fondation comme GPT-4, GPT-4o et Claude 3.5 Sonnet.
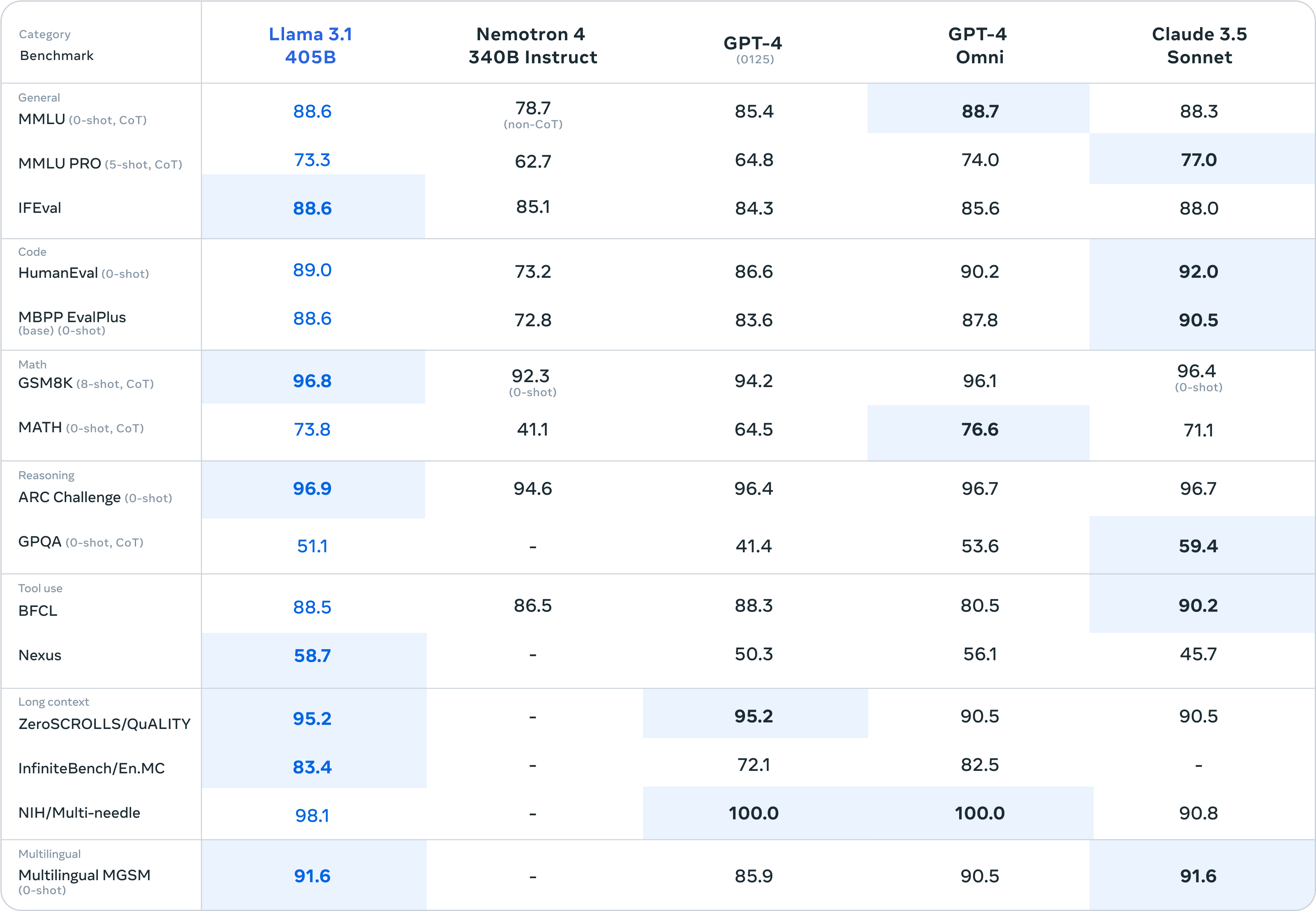
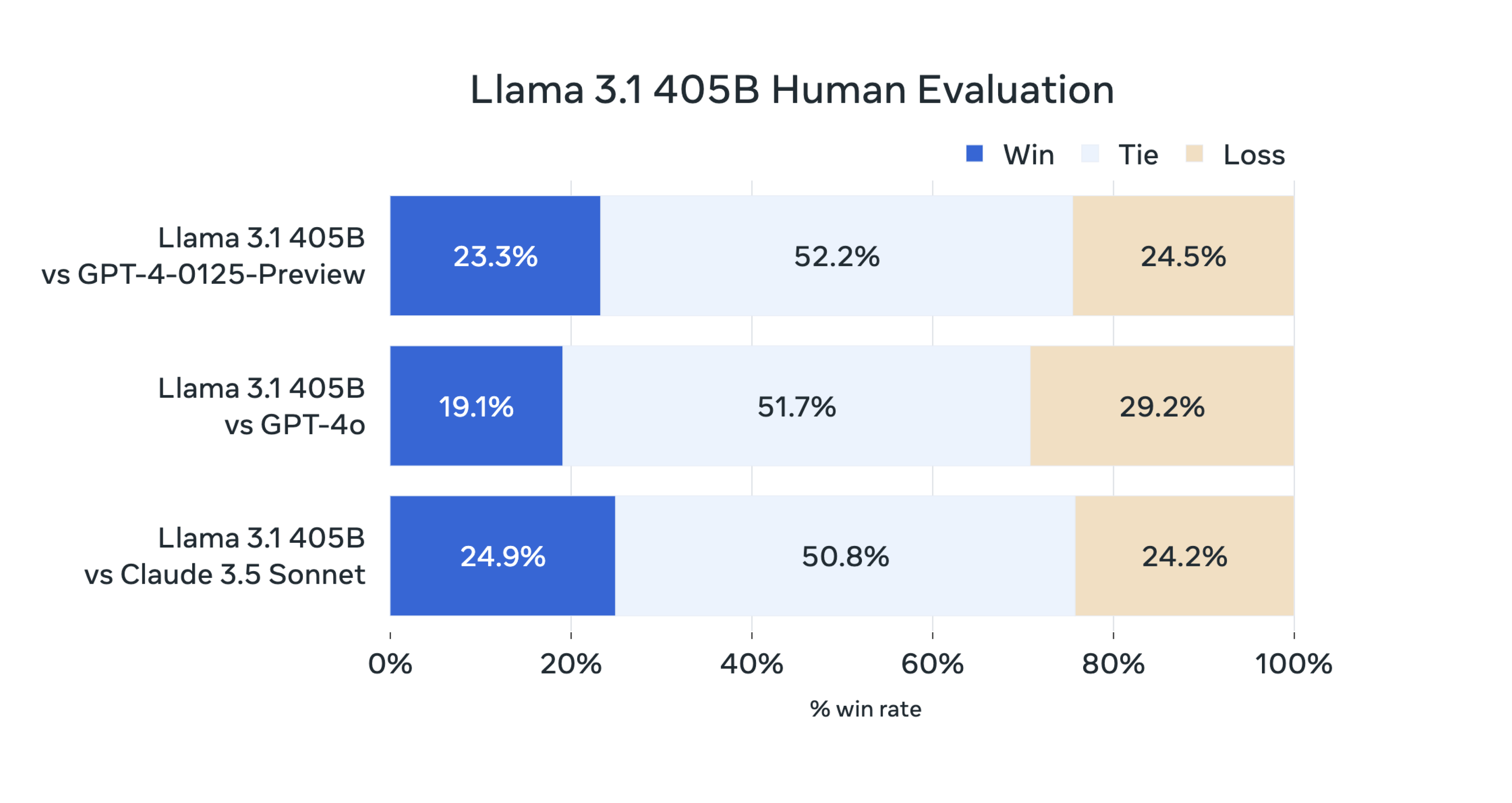
Les modèles plus petits de la famille Llama 3.1 sont eux aussi compétitifs avec des modèles fermés et ouverts ayant un nombre similaire de paramètres.
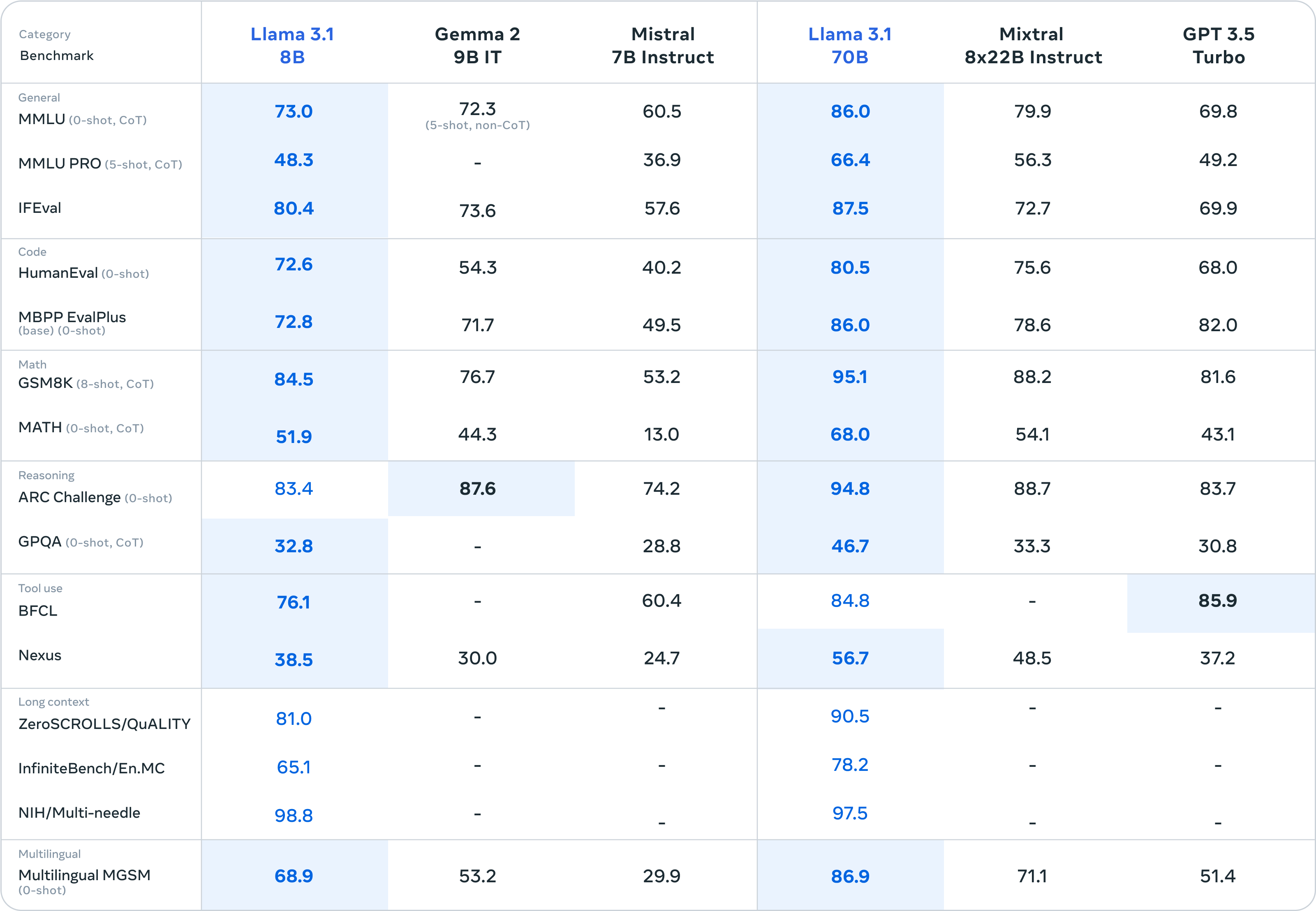
Meta travaille à apporter d'autres modalités au modèle, les images, la vidéo et l'audio. Il pourrait alors ne pas être disponible pour les Européens puisque Meta a décidé de suspendre le lancement des modèles Llama 3 multimodaux au sein de l'UE face à un "environnement réglementaire imprévisible".
Pour Meta, l’IA en libre accès doit devenir la norme du secteur. C'est ce qu'explique Mark Zuckerberg dans le blog "L’IA open source est la voie à suivre", où il présente la collaboration de son entreprise avec des entreprises pour développer l'écosystème d'IA mais également les bénéfices de l'open source pour les développeurs et la société.
Intéressé(e) par l'IA et l'Open Source ? Ne manquez pas le numéro 16 du magazine ActuIA