
Meta AI vient de dévoiler ImageBind, un nouveau modèle d’IA publié en open source capable de lier des informations provenant de six modalités différentes : données textuelles, audio, visuelles, thermiques, de mouvement et de profondeur. En reconnaissant les relations entre ces modalités, le modèle contribue à faire progresser l’IA en permettant aux machines de mieux analyser ensemble de nombreuses formes d’informations différentes.
Selon le post Facebook de Mark Zuckerberg, « ImageBind est un nouveau modèle d'IA qui combine différents sens, tout comme les gens le font".
ImageBind rapproche les machines de la capacité des humains à apprendre simultanément, de manière holistique, à partir de nombreuses et différentes formes d'informations, sans avoir besoin de supervision explicite (processus d'organisation et d'étiquetage des données brutes).
Le modèle apprend un seul espace de représentation partagé, non seulement pour le texte, l'image/vidéo et l'audio, mais aussi pour les capteurs qui enregistrent la profondeur (3D), la thermique (rayonnement infrarouge) et les unités de mesure inertielle (IMU), qui calculent le mouvement et la position.

ImageBind équipe ainsi les machines d'une compréhension holistique qui relie les objets d'une photo à leur son, à leur forme 3D, à leur chaleur ou à leur froid et à leur mouvement.
L'article de recherche de Meta AI démontre qu'ImageBind peut surpasser les modèles entraînés pour une modalité particulière mais pour les chercheurs, il contribue avant tout à faire progresser l'IA en permettant aux machines d'analyser simultanément de nombreuses formes d'informations différentes.
Meta, sur son blog, donne l'exemple de Make-A-Scene qui, en utilisant ImageBind, pourrait créer des images à partir de l'audio, comme créer une image basée sur les sons d'une forêt tropicale ou d'un marché animé. D'autres possibilités futures incluent des moyens plus précis de reconnaître, de connecter et de modérer le contenu, ainsi que de stimuler la création de design, comme générer des médias plus riches plus facilement et créer des fonctions de recherche multimodales plus larges.
Encourager le développement de modèles d'IA multimodaux
Selon Meta, ce dernier modèle s'inscrit dans le cadre de ses efforts pour créer des systèmes d'IA multimodaux qui apprennent à partir de tous les types de données possibles qui les entourent. Il ouvre également la voie afin que des chercheurs essaient de développer de nouveaux systèmes holistiques, tels que combiner des capteurs 3D et IMU pour concevoir ou expérimenter des mondes virtuels immersifs.ImageBind montre qu'il est possible de créer un espace d'incorporation commun à travers plusieurs modalités sans avoir besoin de s'entraîner sur les données des différentes combinaisons de modalités.
Les capacités multimodales d'ImageBind pourraient permettre aux chercheurs d'utiliser d'autres modalités comme requêtes d'entrée et de récupérer des sorties dans d'autres formats. Il peut également mettre à niveau les modèles d’IA existants pour prendre en charge l’entrée de l’une des six modalités, permettant la recherche audio, la recherche intermodale, l’arithmétique multimodale et la génération intermodale.
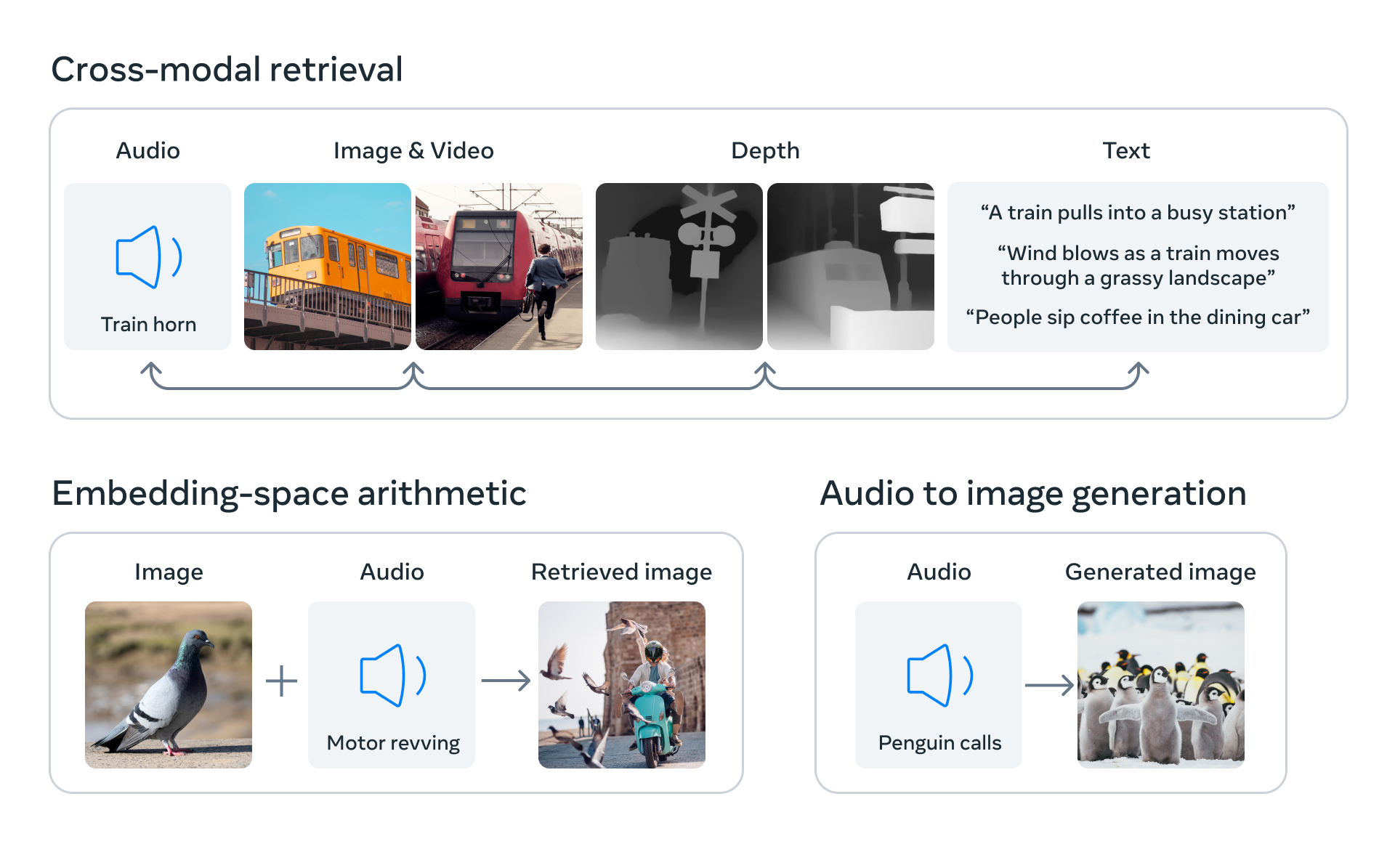
En alignant l'incorporation de six modalités dans un espace commun, ImageBind permet la récupération intermodale de différents types de contenu qui ne sont pas observés ensemble, l'ajout d'incorporations de différentes modalités pour composer naturellement leur sémantique, et la génération audio-vers-image en utilisant des incorporations audio avec un décodeur DALLE-2 pré-entraîné pour travailler avec les incorporations de texte CLIP.
Les performances du modèle
L’apprentissage auto-supervisé aligné sur l’image montre que les performances de notre modèle peuvent en fait s’améliorer en utilisant très peu d’exemples d’entraînement. Selon l'équipe, "le modèle a de nouvelles capacités émergentes, ou comportement de mise à l’échelle, c’est-à-dire des capacités qui n’existaient pas dans les modèles plus petits, mais qui apparaissent dans des versions plus grandes. Cela peut inclure la reconnaissance de l’audio qui correspond à une certaine image ou à la prédiction de la profondeur d’une scène à partir d’une photo".La recherche a également démontré que le comportement d'échelle d'ImageBind s'améliore avec la force de l'encodeur d'image : la capacité d'ImageBind à aligner les modalités augmente avec la force et la taille du modèle de vision. Cela suggère que les modèles de vision plus grands bénéficient aux tâches non visuelles, telles que la classification audio, et que les avantages de l'entraînement de tels modèles vont au-delà des tâches de vision par ordinateur.
Les chercheurs ont comparé les encodeurs audio et profondeur d'ImageBind aux travaux antérieurs en matière de récupération zero-shot ainsi qu'aux tâches de classification audio et profondeur où il les a surpassé.
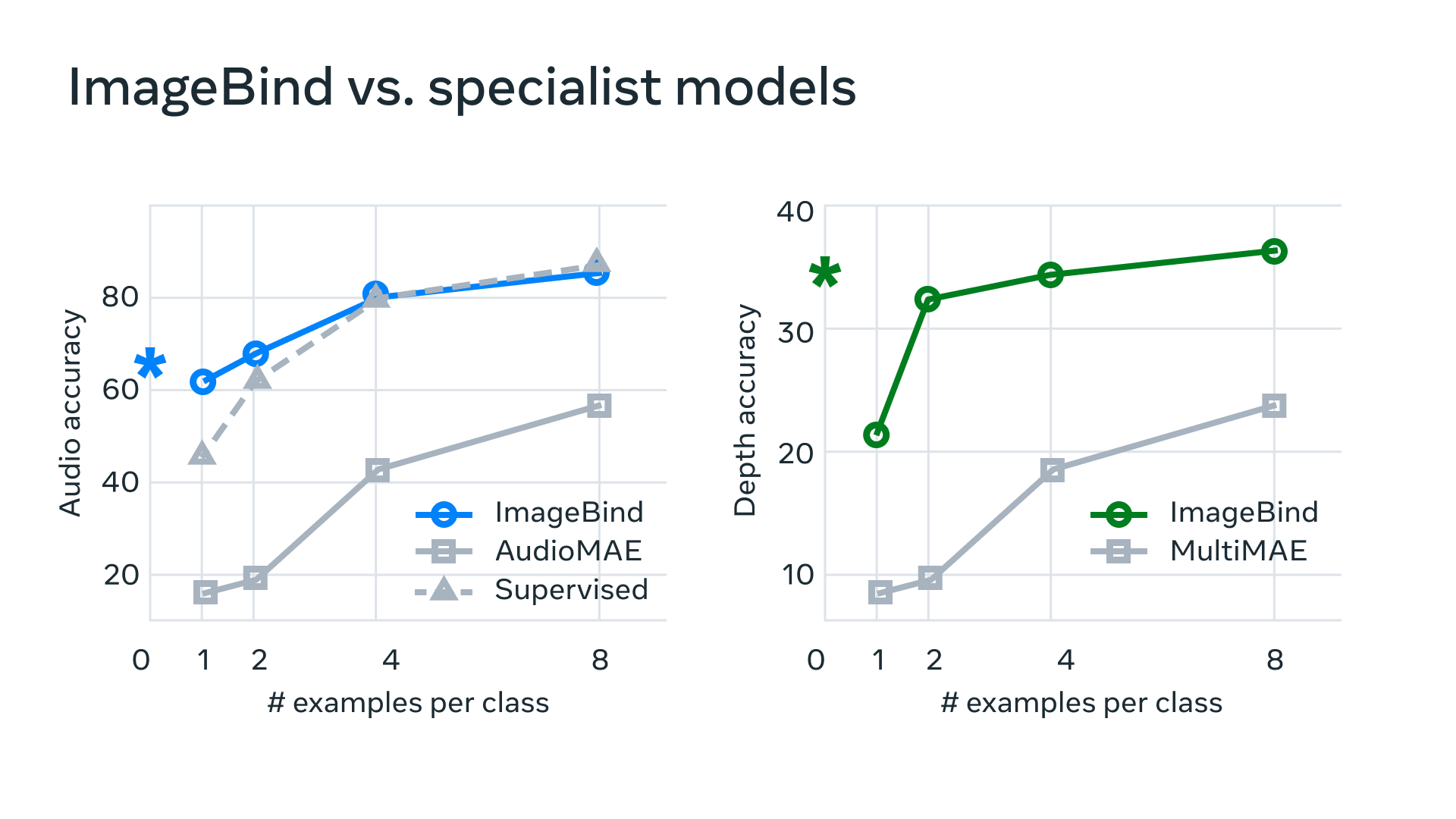
Pour les chercheurs, l'introduction de nouvelles modalités comme le toucher, la parole, l'odorat et les signaux cérébraux IRMf, permettra de créer des modèles d'IA plus riches centrés sur l'homme. Ils espèrent que la communauté de recherche explorera ImageBind et leur article pour trouver de nouvelles façons d'évaluer les modèles de vision et créer de nouvelles applications.
Référénces : blog Meta AI
Pour plus d'informations, voir la démonstration et consulter l'article de recherche : "IMAGEBIND: One Embedding Space To Bind Them All"