

Meta AI a pour ambition de démocratiser la segmentation, une tâche essentielle en vision par ordinateur utilisée dans un large éventail d’applications. Dans ce but, la société présente Segment Anything (SAM), un modèle d’IA qui peut identifier et « découper n’importe quel objet, dans n’importe quelle image, en un seul clic ». Ce modèle, disponible sous une licence ouverte permissive (Apache 2.0), fait partie du projet « Segment Anything » qui a fait l’objet d’une publication sur arXiv le 5 avril dernier.
La segmentation, c’est-à-dire l’identification des pixels d’une image qui appartiennent à un objet, est une tâche importante de la vision par ordinateur, utilisée dans de nombreuses d’applications, de l’analyse de l’imagerie scientifique à la retouche de photos. Cependant, la création d’un modèle de segmentation précis pour des tâches spécifiques nécessite généralement un travail hautement spécialisé de la part d’experts techniques ayant accès à une infrastructure d’entraînement à l’IA et à de grands volumes de données soigneusement annotées dans le domaine.
Le projet Segment Anything vise à réduire les besoins en expertise de modélisation spécifique à une tâche, en calcul d’entraînement et en annotation de données personnalisées pour la segmentation d’images.
L’objectif pour les chercheurs était de construire un modèle de base pour la segmentation en introduisant trois composants interconnectés: une tâche de segmentation rapide, un modèle de segmentation (SAM) qui alimente l’annotation des données et permet un transfert sans tir vers une plage de tâches via une ingénierie rapide, et un moteur de données pour la collecte.
SAM, un modèle de base pour la segmentation
Selon le blog que Meta consacre à SAM, les données de segmentation nécessaires à l’entraînement d’un tel modèle ne sont pas facilement disponibles en ligne ou ailleurs, contrairement aux images, aux vidéos et aux textes, qui sont abondants sur Internet.
Les chercheurs ont choisi de développer un modèle de segmentation général entraîné sur des données diverses qui puisse s’adapter à des tâches spécifiques, de manière analogue à la façon dont l’entraînement est utilisé dans les modèles de traitement du langage naturel et l’ont l’utilisé pour créer un ensemble de données de segmentation d’une ampleur sans précédent, selon eux.
SAM a appris une notion générale de ce que sont les objets, et peut générer des masques pour n’importe quel objet dans n’importe quelle image ou vidéo, y compris des objets et des types d’images qu’il n’a pas rencontrés pendant la formation. Il est suffisamment général pour couvrir un large éventail de cas d’utilisation et peut être utilisé d’emblée sur de nouveaux “domaines” d’images, qu’il s’agisse de photos sous-marines ou de microscopie cellulaire, sans nécessiter de formation supplémentaire.
Une segmentation par invites
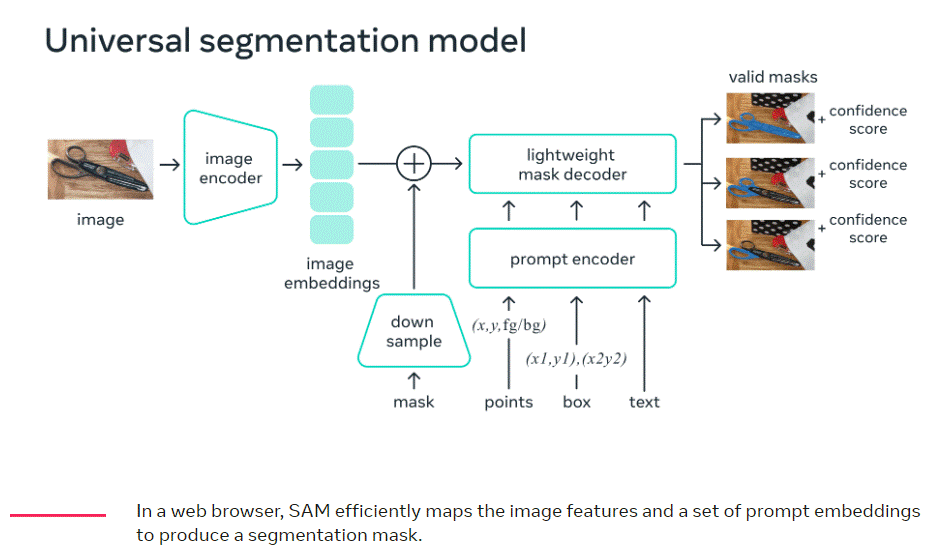
SAM renvoie un masque de segmentation valide pour n’importe quelle invite : des points d’avant-plan/arrière-plan, une boîte ou un masque approximatif, un texte de forme libre, ou, en général, toute information indiquant ce qu’il faut segmenter dans une image.
Un encodeur d’image produit une intégration unique pour l’image, tandis qu’un encodeur léger convertit n’importe quelle invite en un vecteur d’intégration en temps réel. Ces deux sources d’information sont ensuite combinées dans un décodeur léger qui prédit les masques de segmentation. Une fois l’intégration de l’image calculée, SAM peut produire un segment en seulement 50 millisecondes à partir de n’importe quelle invite dans un navigateur web.
SA-1B, un ensemble de données de plus d’un milliard de masques
Selon Meta AI, l’ensemble de données final SA-1B qui comprend plus de 1,1 milliard de masques de segmentation collectés sur environ 11 millions d’images sous licence et préservant la confidentialité, est 400 fois plus volumineux que les ensembles de données de segmentation existants. Il a été collecté à l’aide de SAM et les chercheurs s’en sont servi pour l’entraîner. Les annotateurs humains ont utilisé le modèle pour annoter les images de manière interactive, et ces données ont permis de mettre à jour le modèle. Ce cycle a été répété plusieurs fois pour améliorer à la fois le modèle et l’ensemble de données.
Pour créer cet ensemble de données, les chercheurs ont construit un moteur de données à 3 vitesses : lors de la première, le modèle assiste les annotateurs, comme décrit ci-dessus. La deuxième vitesse est un mélange d’annotation entièrement automatique et d’annotation assistée, ce qui permet d’augmenter la diversité des masques collectés. La dernière vitesse du moteur de données est la création entièrement automatique de masques, ce qui permet à l’ensemble de données de s’adapter.
L’équipe de Meta AI a rendu l’ensemble de données public afin que d’autres chercheurs puissent former des modèles de base pour la segmentation d’images et espère que ces données pourront servir de base à de nouveaux ensembles de données comportant des annotations supplémentaires, telles qu’une description textuelle associée à chaque masque.
En partageant ses recherches et ses données, elle souhaite accélérer la recherche sur la segmentation et la compréhension plus générale des images et des vidéos. Pour elle, que SAM peut devenir un composant puissant d’un système plus large dans des domaines tels que l’AR/VR, la création de contenu, les domaines scientifiques et les systèmes d’IA plus généraux.
Références : blog Meta AI
Retrouver sur Github
Accéder à l’ensemble de données