
Le modèle de génération de vidéos Lumiere, récemment présenté par des chercheurs de Google Research, utilise un modèle de diffusion probabiliste basé sur un réseau U-Net spatio-temporel, pour générer des vidéos de 5 secondes réalistes et cohérentes à partir d'invites ou d'images fixes, permettre de les styliser suivant son choix ou créer des cinémagraphes en animant seulement la partie sélectionnée d'une image.
Les modèles de génération d'images tels qu'Adobe Firefly, DALL-E, Midjourney, Imagen ou Stable Diffusion ont soulevé l'enthousiasme et été rapidement adoptés. Une suite logique était la génération de vidéos, Meta AI s’y est attaqué dès octobre 2022 avec Make-A-Video, le laboratoire NVIDIA AI de Toronto a dévoilé un modèle de synthèse Text-to-Video haute résolution basé sur le modèle Stable Diffusion open source de Stability AI qui a de son côté présenté en novembre dernier Stable Video Diffusion, un modèle très performant.
La génération de vidéos est une tâche beaucoup plus complexe que la génération d'images, impliquant une dimension temporelle en plus de la dimension spatiale, le modèle doit non seulement générer correctement chaque pixel, mais également prédire comment ce dernier évoluera pour produire une vidéo cohérente et fluide.
Pour Lumiere, Google Research, qui avait participé au développement du modèle de génération de vidéos W.A.L.T présenté le mois dernier, a opté pour une approche novatrice afin de surmonter les défis spécifiques liés à l’entraînement des modèles text-to-video.
Le modèle LUMIERE se compose d’un modèle de base et d’un modèle de super-résolution spatiale. Le modèle de base génère des clips vidéo à basse résolution en traitant le signal vidéo dans plusieurs échelles spatio-temporelles, en s’appuyant sur un modèle de text-to-image pré-entraîné. Le modèle de super-résolution spatiale augmente la résolution spatiale des clips vidéo en utilisant une technique de multidiffusion pour assurer la continuité globale du résultat.
Les chercheurs expliquent :
"Nous introduisons une architecture U-Net spatio-temporelle qui génère toute la durée temporelle de la vidéo en une seule fois, par un seul passage dans le modèle. Cela contraste avec les modèles vidéo existants qui synthétisent des images clés distantes suivies d’une super-résolution temporelle, une approche qui rend intrinsèquement difficile la réalisation d’une cohérence temporelle globale".
[caption id="attachment_55176" align="alignnone" width="1600"]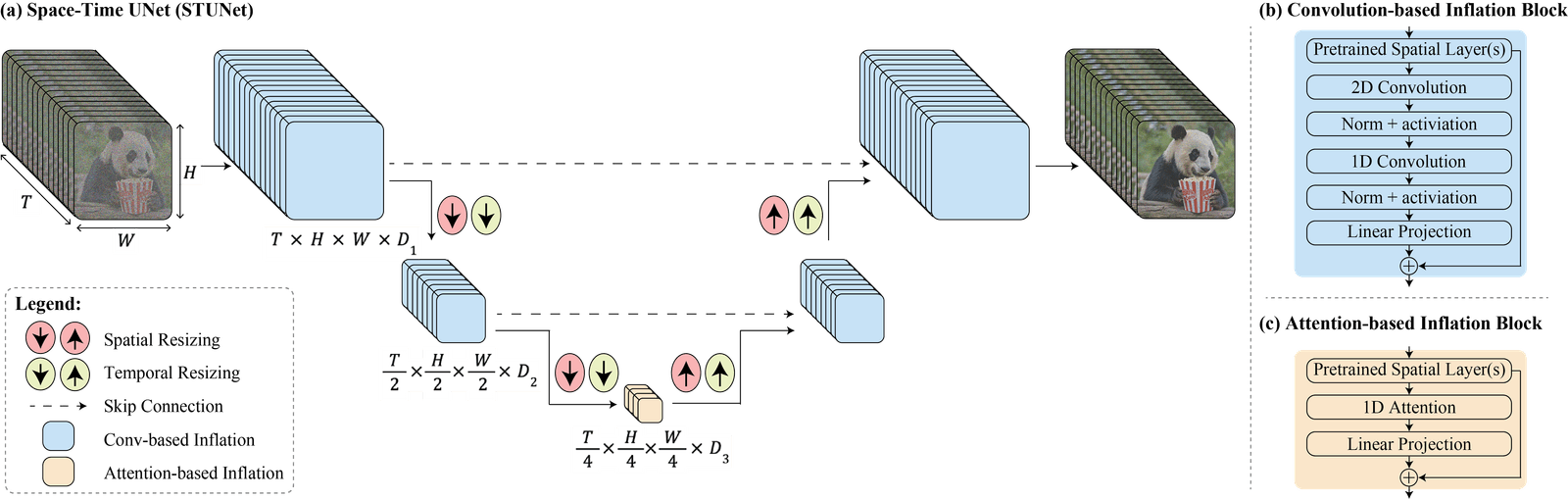 Crédit Google Research[/caption]
Crédit Google Research[/caption]
Applications
Le modèle peut être facilement adapté à une variété de tâches de création et d’édition de contenu vidéo, telles que la génération de vidéos stylisées, la génération d’images-vers-vidéos, l’inpainting et l’outpainting vidéo, et la création de cinémagraphes, comme on peut le constater dans la vidéo ci-dessous.Pour rappel, l'inpainting permet de remplir ou restaurer des parties manquantes ou endommagées d'une vidéo de manière réaliste. On peut l'utiliser pour remplacer des objets indésirables, réparer des artefacts (anomalies ou altérations non désirées) ou des zones corrompues dans une vidéo, ou même pour créer des effets spéciaux.
L'outpainting vidéo, en revanche, se réfère à l'extension ou à l'ajout de contenu au-delà des limites existantes de la vidéo. Il permet d'ajouter des éléments pour agrandir la scène, créer des transitions fluides entre les clips vidéo ou ajouter des éléments décoratifs ou contextuels.
Evaluations
Le modèle Lumiere a été évalué sur 113 descriptions textuelles ainsi que sur le jeu de données UCF101. Il a obtenu des résultats compétitifs en termes de Frechet Video Distance et d'Inception Score, et a été préféré par les utilisateurs pour sa qualité visuelle et sa cohérence de mouvement par rapport aux méthodes concurrentes.Si le modèle a démontré de solides performances, les chercheurs rappellent :
"Notre objectif principal dans ce travail est de permettre aux utilisateurs novices de générer du contenu visuel de manière créative et flexible. Cependant, il existe un risque d’utilisation abusive pour la création de contenu faux ou préjudiciable avec notre technologie, et nous pensons qu’il est crucial de développer et d’appliquer des outils pour détecter les biais et les cas d’utilisation malveillants afin de garantir une utilisation sûre et équitable".
Références de l'article :Article "Lumiere: A Space-Time Diffusion Model for Video Generation"
arXiv, soumis le 23/01/2024, https://doi.org/10.48550/arXiv.2401.12945
Auteurs : Omer Bar-Tal 1 2, Hila Chefer 1 3, Omer Tov 1, Charles Herrmann 1, Roni Paiss 1, Shiran Zada 1, Ariel Ephrat 1, Junhwa Hur 1, Yuanzhen Li 1, Tomer Michaeli 1 4, Oliver Wang 1 Deqing Sun 1, Tali Dekel 1 2, Inbar Mosseri 1
1Google Research 2Weizmann Institute 3Tel-Aviv University 4Technion