
Cet article a été par Ludovic Denoyer. Il est chercheur scientifique au FAIR, se concentrant principalement sur divers problèmes d’apprentissage automatique, en particulier sur l’apprentissage par renforcement et l’interaction homme-machine. Il était auparavant professeur à Sorbonne Universités.
Rendre plus simple la programmation d’algorithmes d’apprentissage par renforcement à l’aide des principes de l’apprentissage supervisé : la librairie « RLStructures ».
Dans le cadre des jeux olympiques 2024, nous vous offrons chaque jour un article issu du magazine ActuIA n°4, dont le dossier principal est "Le sport à l'ère de l'IA". Afin de découvrir le magazine ActuIA, nous vous invitons à vous rendre sur notre boutique. Tout nouvel abonnement d'un an vous donne droit à l'ensemble des archives au format numérique.
L’un des facteurs-clés du succès de l’apprentissage profond (deep learning) est la facilité avec laquelle ce paradigme permet de mettre en application de nouvelles idées et de les expérimenter concrètement sur de volumineux jeux de données. Nous avons en effet assisté à l’émergence conjointe d’avancées déterminantes du côté hardware, avec la mise à disposition de processeurs graphiques (GPUs) à bas coût particulièrement adaptés aux calculs vectoriels et matriciels, ainsi que du côté software, à travers la création de multiples librairies d’autodifférenciation (Theano, Torch, puis TensorFlow, PyTorch, Jax, etc.), permettant de faciliter grandement la programmation d’algorithmes d’apprentissage statistique.
Ainsi, il est désormais possible d’implémenter en quelques heures ce qui pouvait prendre des semaines quelques années auparavant. L’explosion récente du deep learning est au moins autant liée à ces progrès d’infrastructures hardware et software qu’aux progrès conceptuels ou algorithmiques.
Cependant, le deep learning s’attaque principalement à des problématiques d’apprentissage à partir de jeux de données. D’autres cadres d’apprentissage ne sont pas au même point de maturité et ne disposent pas d’outils équivalents. C’est le cas de l’apprentissage par renforcement dont l’objectif est d’acquérir un comportement à partir d’interactions avec un environnement. Popularisé ces dernières années à travers les résultats obtenus sur des problèmes symboliques de l’intelligence artificielle tel que le jeu de go ou les échecs, son cadre est très prometteur car il permet de modéliser des systèmes en interaction (avec d’autres systèmes, des utilisateurs, etc.).
En effet, de nombreuses applications nécessitent des systèmes permettant non pas de faire une prédiction sur une donnée, mais de produire des séquences cohérentes d’actions qui, ensemble, vont permettre d’aboutir à une solution. Ainsi, les algorithmes d’apprentissage par renforcement sont cruciaux dans des applications telles que la robotique, la recommandation, la conception de chatbots, la voiture autonome, etc. Ce domaine reste néanmoins aujourd’hui difficile à aborder, particulièrement dans ses aspects expérimentaux. Si les infrastructures hardware (multiples CPUs et GPUs) sont aujourd’hui souvent disponibles, les infrastructures logicielles sont quant à elles peu matures : l’appren-tissage par renforcement n’a pas encore fait sa révolution.
L’un des enjeux du domaine actuellement est d’extraire des principes-clés de programmation des algorithmes de renforcement sur lesquels il serait possible de bâtir des librairies aussi simples et efficaces que celles dont nous disposons en deep learning. Cela permettrait de démocratiser ce domaine encore trop confidentiel et donc d’y accélérer massivement la recherche et l’utilisation pratique d’algorithmes, ouvrant le champ des possibles de l’IA à des applications bien plus complexes que celles traitées actuellement.
Les librairies de deep learning
Les algorithmes d’apprentissage à partir de données reposent sur quatre composants principaux : 1. un jeu de données. 2. un modèle de prédiction. 3. une fonction de coût permettant de mesurer la qualité du modèle de prédiction, et 4. un algorithme d’optimisation dont l’objectif est de définir (d’apprendre) le meilleur modèle, c’est-à-dire celui dont le coût de prédiction est le plus faible.Pendant très longtemps, la difficulté de mise en œuvre expérimentale ou en production de ces modèles venait du fait que chaque nouvelle idée avait une incidence sur plusieurs de ces composants, nécessitant un travail d’adaptation fastidieux et coûteux. Le deep learning a démocratisé l’utilisation d’une famille particulière de modèles très expressive, les réseaux de neurones, associés à un algorithme d’optimisation précis, la descente de gradient, permettant d’automatiser de grandes parties de ce processus.

Figure 1 : Exemple d’implémentation d’algorithmes de deep learning (à la’ PyTorch). Les quatre composants décrits apparaissent explicitement, et le programmeur implémente différentes idées en modifiant l’architecture du modèle (fonction ‘build_my_neural_ network’) ou la fonction de coût (fonction ‘my_loss_function’). La librairie de deep learning automatise i) le calcul du gradient (compute_gradient) et ii) la lecture des données (DataLoader).
Construites autour de composants logiciels permettant de faire de la différenciation automatique, les librairies actuelles de deep learning permettent de simplifier grandement les composants 2., 3. et 4. décrits précédemment. Concrètement, le programmeur n’a plus qu’à définir une architecture de modèle, une fonction de coût appropriée à son application, la librairie prendra en charge le reste, permettant l’apprentissage aussi bien sur CPU que sur GPU, voire sur plusieurs GPUs simultanément. Enfin, les librairies proposent aussi des composants logiciels souvent peu mis en avant mais essentiels : les data-loaders.
Ces composants permettent l’ingestion par les algorithmes d’apprentissage de volumineux jeux de données à haute vitesse grâce à la parallélisation de la lecture des données et leur agrégation (batching) automatique, et ce de façon complètement transparente pour le programmeur. Cet exemple de code permettant l’apprentissage d’un modèle en figure 1 nous montre que quelques lignes suffisent pour être en mesure d’implémenter un modèle et de l’apprendre sur de grandes quantités de données.
Les difficultés de l’apprentissage par renforcement
En comparaison de l’apprentissage supervisé classique, l’apprentissage par renforcement revêt de nombreuses difficultés.1) La première d’entre elles est celle dite du credit assignment, c’est-à-dire la détection (et le renforcement) des actions déterminantes pour l’obtention d’une grande récompense. En effet, l’agent doit effectuer de multiples actions, et réussir à ‘comprendre’ parmi elles quelles sont les bonnes et quelles sont les mauvaises, alors même que les conséquences de ces actions ne pourront être observées que bien plus tard dans la vie de l’agent.
2) La seconde difficulté est celle dite du dilemme exploration/exploitation : afin de pouvoir trouver des comportement efficaces, un agent doit explorer l’environnement dans lequel il s’exécute. Mais, afin d’éviter une exploration inefficace ou trop coûteuse en termes de temps, il est aussi important pour l’agent d’exploiter l’information collectée afin de se focaliser sur des comportements ‘prometteurs’.
3) Enfin un troisième problème fréquemment rencontré est celui de l’observation partielle de l’environnement : l’agent observe à l’instant t une information uniquement partielle qui ne lui permet pas de se ‘localiser’ facilement dans l’environnement (prenons l’exemple d’un robot face à un mur blanc, qui n’observe donc qu’une image blanche et ignore de ce fait où il se trouve précisément).
Ces trois problèmes fondamentaux qui différencient l’apprentissage par renforcement de l’apprentissage supervisé classique font actuellement l’objet de multiples directions de recherche.
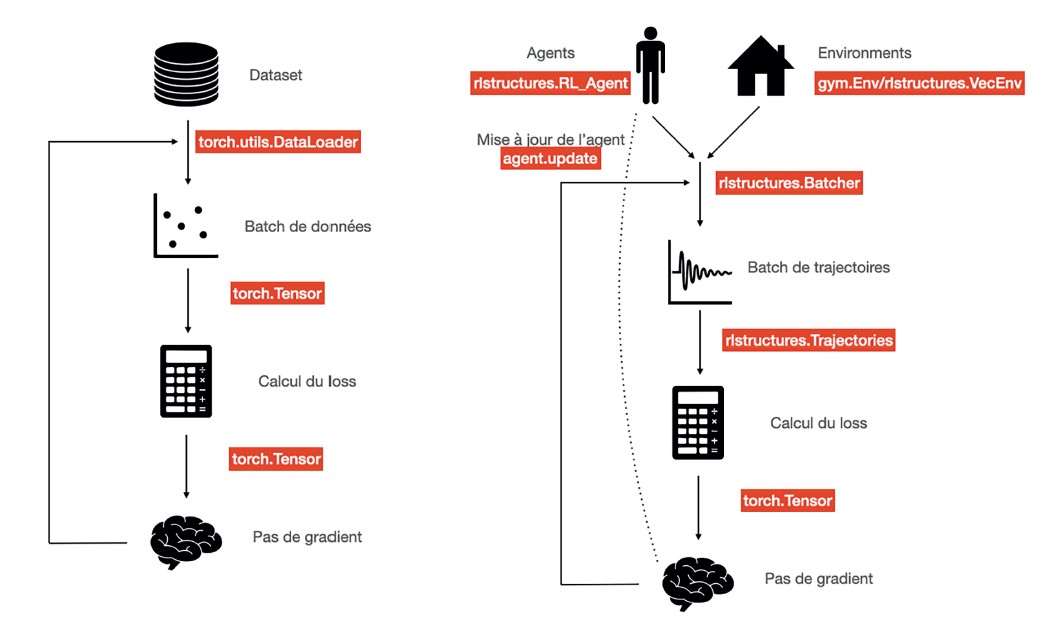
Figure 2 : Apprentissage supervisé (PyTorch) et apprentissage par renforcement en RLStructures
L’apprentissage par renforcement
L’apprentissage par renforcement est un cadre d’apprentissage différent de l’apprentissage à partir de données, modélisant l’interaction d’un agent avec un environnement (figure 2). À chaque itération, l’agent observe l’environnement et doit choisir quelle action effectuer. Après la mise en œuvre de son action, il reçoit une récompense immédiate. L’objectif de l’apprentissage est de trouver le meilleur agent, c’est-à-dire celui qui va recevoir le plus grand nombre de récompenses cumulées durant un épisode d’interaction. Contrairement à l’apprentissage supervisé classique, la complexité du problème vient du fait que les prédictions (les actions) faites par le modèle peuvent avoir des conséquences plus tard dans la ‘vie’ de l’agent, rendant la compréhension d’une action à entreprendre, et à quel moment, très difficile.Ainsi décrit, ce cadre semble très différent du cadre de deep learning présenté précédemment. Les abstractions proposées dans les librairies de deep learning classiques ne sont pas appropriées et ne peuvent être utilisées facilement pour implémenter des algorithmes d’apprentissage par renforcement. Si nous observons les librairies d’apprentissage par renforcement disponibles actuellement, nous constatons que la plupart d’entre elles visent naturellement à abstraire les concepts spécifiques du domaine (environnement, politique, agent), leur utilisation nécessite donc un prix d’entrée important. Par exemple, l’algorithme d’apprentissage est souvent inclus dans l’agent lui-même, rendant l’apprentissage et l’acquisition de données interdépendants, ou bien les structures de données sont spécifiques à certains types de problèmes et ne peuvent être utilisées dans des cadres plus hétérogènes d’apprentissage par renforcement.
Cependant, à y regarder de plus près, le cadre de l’apprentissage par renforcement présente de multiples similitudes avec l’apprentissage à partir de données. Tout comme en deep learning, un algorithme d’apprentissage par renforcement nécessité :
a) des données, traces d’interaction entre des agents et des environnements et produites ici aussi à grande vitesse ;
b) un modèle de prédiction correspondant à un agent décideur d’actions à effectuer en fonction des observations.
Enfin, la grande majorité des algorithmes existants peuvent être exprimés à travers une fonction de coût (composant c) calculé sur des traces d’interactions, et optimisé par descente de gradient (composant d). Peut-on alors programmer les algorithmes d’apprentissage par renforcement de manière similaire à ceux du deep learning, facilitant par là même leur compréhension ? Quelles en sont les différences ?
La première différence provient de la nature des données traitées. Là où le deep learning représente les données considérées comme indépendantes les unes des autres, l’apprentissage par renforcement traite des trajectoires, c’est-à-dire des séquences temporelles de données complexes (observations, actions, récompenses, etc.). Il est donc nécessaire de pouvoir décrire ce type de données facilement.
La deuxième différence se situe dans la nature du modèle de prédiction : là ou le deep learning produit une prédiction à partir d’une donnée unique, un agent produit une action à partir d’un historique d’interactions, c’est-à-dire à partir des observations et actions rencontrées tout au long d’un épisode. Un modèle doit donc avoir accès à son histoire, aux observations et actions produites précédemment.
Enfin, la troisième différence provient du processus d’acquisition des données : là où les librairies de deep learning classiques proposent des data loaders permettant le chargement rapide de grands jeux de données, il est nécessaire en apprentissage par renforcement de pouvoir échantillonner rapidement des traces d’interactions entre plusieurs politiques et plusieurs environnements à grande vitesse.
Ce processus d’échantillonnage est certainement la partie la plus coûteuse en termes de développement pour un programmeur qui initie un nouveau projet en apprentissage par renforcement, car il implique de pouvoir simuler les interactions entre des agents et des environnements, tout en capturant les informations nécessaires à la mise à jour des agents par apprentissage.
La librairie RLStructures
La librairie RLStructures vise à faciliter le passage de l’idée à l’expérimentation le plus efficacement possible. Elle propose une solution aux trois problèmes identifiés précédemment, et permet d’implémenter des algorithmes aussi facilement qu’en deep learning, reprenant les principes des librairies classiques (PyTorch dans notre cas) en les étendant au cas de l’apprentissage par renforcement.
Figure 3 : Exemple d’implémentation d’algorithme d’apprentissage par renforcement (‘à la’ RLStructures). Les 4 composants apparaissent explicitement, la librairie de deep learning prenant en charge le calcul du gradient, et RLStructures (Batcher) prenant en charge l’acquisition de données par des agents sur des environnements.
Le schéma reste très similaire à la boucle d’apprentissage de la figure 1, permettant une familiarisation aisée.
Conformément à cette description, elle est fondée sur trois composants génériques :
a) elle étend les tenseurs et fournit une structure de données simple et flexible permettant de modéliser des informations complexes (e.g. actions structurées, observations complexes, etc.) ;
b) elle propose une abstraction permettant d’implémenter des agents, notamment à l’aide de réseaux de neurones ;
c) elle fournit un unique composant d’échantillonnage permettant l’acquisition de traces d’interactions entre de multiples agents et environnements à haute vitesse (plusieurs CPUs et GPUs simultanément), à travers la parallélisation sur plusieurs processus.
Assemblés, ces composants simples permettent l’écriture d’algorithmes d’apprentissage par renforcement de manière très similaire à la méthode utilisée en deep learning classique (cf. figure 3).
Se familiariser avec cette librairie et l’utiliser pour implémenter de nouvelles idées devient facile, y compris dans des cadres moins conventionnels tels que l’apprentissage par renforcement non supervisé, les politiques hiérarchiques, l’apprentissage de populations de politiques, etc.
La librairie propose par ailleurs des exemples concrets d’implémentation d’algorithmes du domaine, permettant à un utilisateur de les modifier facilement à son gré, ainsi que des exemples d’utilisation de la librairie dans des cadres moins conventionnels.
Pour de plus amples informations, nous fournissons des tutoriaux et de multiples exemples d’algorithmes. Ludovic Denoyer est professeur à Sorbonne Université où il a longtemps dirigé le master DAC (Données, Apprentissage, Connaissances) axé sur le deep learning. Aujourd’hui détaché de l’université, il est research scientist au sein de Facebook artificial intelligence research (FAIR) et concentre sa recherche sur l’apprentissage par renforcement.
Les fonctionnalités de RLStructures
RLStructures est une librairie dont la principale caractéristique est de permettre à un programmeur d’implémenter des agents facilement, d’exécuter de multiples agents sur de multiples environnements en parallèle, et de récupérer les traces d’interactions facilitant la mise en place de nouveaux algorithmes.Plus particulièrement, RLStructures permet :
• d’exécuter les agents et environnements sur plusieurs CPUs ou GPUs ;
• d’exécuter les agents de manière synchrone ou asynchrone, l’acquisition étant alors effectuée en tâche de fond, sans bloquer l’exécution du programme principal ;
• d’accéder à l’ensemble de l’épisode à chaque instant, afin par exemple de permettre l’implémentation de politiques basées sur des architectures de type transformers.
Par ailleurs, RLStructures fournit des fonctions de replay permettant de re-exécuter un agent sur des trajectoires précédemment acquises dans l’objectif de faciliter l’implémentation d’algorithmes dits off-policy.
Conclusion
Le deep learning et l’apprentissage par renforcement, souvent identifiés comme deux domaines distincts, partagent plus de similitudes qu’il n’y paraît. L’apprentissage par renforcement, plus complexe que l’apprentissage ‘classique’, est un domaine aujourd’hui suffisamment mature pour que nous puissions en extraire des principes-clés permettant de faciliter l’implémentation effective d’algorithmes nouveaux. RLStructures est une première tentative dans cette direction.Elle permet dès à présent un gain de temps non négligeable durant le développement et peut être utilisée comme accélérateur de recherche. Elle peut aussi être envisagée comme cadre d’enseignement de l’apprentissage par renforcement.
Nous sommes impatients de voir comment elle évoluera dans les mois à venir, avec l’aide de la communauté.
Cet article est extrait du magazine ActuIA. Afin de ne rien manquer de l'actualité de l'intelligence artificielle, procurez vous ActuIA n°16, actuellement en kiosque et sur abonnement :