Une équipe de chercheurs du MIT a présenté Ithemal, un outil de machine learning permettant de prédire la vitesse à laquelle les puces informatiques exécuteront le code de diverses applications. Dans plusieurs présentations faites dans des articles et à l'occasion de conférences telles que l'IEEE et NeurIps, ils ont expliqué le fonctionnement de ce modèle permettant d'automatiser ce processus.
Comme l'explique le MIT, pour que le code s'exécute le plus rapidement possible, les développeurs et les compilateurs - des programmes qui traduisent le langage de programmation en code lisible par la machine - utilisent généralement des modèles de performance qui exécutent le code par une simulation d'architectures de puces données.
Les compilateurs utilisent cette information pour optimiser automatiquement le code, et les développeurs l'utilisent pour s'attaquer aux goulets d'étranglement des performances des microprocesseurs qui l'exécuteront. Mais les modèles de performance pour le code machine sont écrits à la main par un groupe d'experts relativement restreint et ne sont pas correctement validés. En conséquence, les mesures de performance simulées s'écartent souvent des résultats réels.
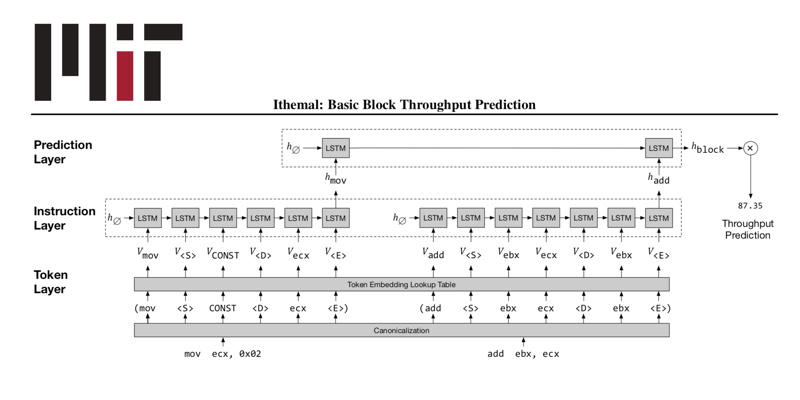
Dans une série d'articles de conférence, les chercheurs du MIT ont décrit un nouveau pipeline de machine learning capable d'automatiser ce processus, le rendant plus facile, plus rapide et plus précis. Dans un article présenté à la International Conference on Machine Learning en juin dernier, les chercheurs ont présenté Ithemal, un modèle de réseau neuronal qui s'entraîne sur des données étiquetées sous forme de "basic blocks" - des bribes fondamentales d'instructions de calcul - pour prédire automatiquement le temps qu'il faut à une puce pour exécuter des "blocs de base" inédits. Les résultats suggèrent qu'Ithemal est beaucoup plus précis que les modèles traditionnels.
Puis, lors du symposium international de l'IEEE sur la caractérisation de la charge de travail, en novembre, l'équipe de chercheurs a présenté une suite de blocs de base de référence provenant de divers domaines, dont le machine learning, les compilateurs, la cryptographie et les graphiques, qui peuvent être utilisés pour valider les modèles de performance. Ils ont regroupé plus de 300 000 des blocs profilés dans un ensemble de données de source ouverte appelé BHive. Au cours de leurs évaluations, Ithemal a prédit la vitesse à laquelle les puces Intel exécuteraient du code encore mieux qu'un modèle de performance construit par Intel lui-même.
En fin de compte, les développeurs et les compilateurs peuvent utiliser cet outil pour générer du code qui s'exécute plus rapidement et plus efficacement sur un nombre toujours croissant de puces diverses et de conception "boîte noire".
"Les processeurs informatiques modernes sont opaques, terriblement compliqués et difficiles à comprendre. Il est aussi incroyablement difficile d'écrire un code informatique qui s'exécute le plus rapidement possible pour ces processeurs", a déclaré le coauteur Michael Carbin, professeur adjoint au Département de génie électrique et d'informatique (EECS) et chercheur au CSAIL. "Cet outil est un grand pas en avant vers la modélisation complète des performances de ces puces pour une meilleure efficacité".Plus récemment, dans un article présenté à la conférence NeurIPS en décembre, l'équipe a proposé une nouvelle technique pour générer automatiquement des optimisations de compilateurs. Plus précisément, ils génèrent automatiquement un algorithme, appelé Vemal, qui convertit certains codes en vecteurs, qui peuvent être utilisés pour le calcul parallèle. Vemal surpasse les algorithmes de vectorisation artisanaux utilisés dans le compilateur LLVM - un compilateur populaire utilisé dans l'industrie.
Concevoir des modèles de performance à la main peut être "un black art", explique M. Carbin. Intel fournit une documentation complète de plus de 3 000 pages décrivant les architectures de ses puces. Mais il n'existe actuellement qu'un petit groupe d'experts pouvant construire des modèles de performance simulant l'exécution de code sur ces architectures.
"Les documents d'Intel ne sont ni exempts d'erreurs ni complets, et Intel omettra certaines choses, car elle est propriétaire", précise Charith Mendis. "Cependant, lorsque vous utilisez des données, vous n'avez pas besoin de connaître la documentation. S'il y a quelque chose de caché, vous pouvez l'apprendre directement à partir des données."
Pour ce faire, les chercheurs ont chronométré le nombre moyen de cycles qu'un microprocesseur donné prend pour calculer les instructions de bloc de base - essentiellement la séquence de démarrage, d'exécution et d'arrêt - sans intervention humaine. L'automatisation du processus permet de profiler rapidement des centaines de milliers ou des millions de blocs.
Durant l'entraînement, le modèle Ithemal analyse des millions de blocs de base automatiquement profilés pour apprendre exactement comment différentes architectures de puces exécuteront les calculs. Il est important de noter qu'Ithemal prend du texte brut en entrée et ne nécessite pas d'ajouter manuellement des fonctionnalités aux données d'entrée. Lors des tests, Ithemal peut être alimenté par des blocs de base inédits et une puce donnée, et génère un nombre unique indiquant à quelle vitesse la puce exécutera ce code.
Les chercheurs ont constaté qu'Ithemal réduisait les taux d'erreur de précision - c'est-à-dire la différence entre la vitesse prédite et la vitesse réelle - de 50 % par rapport aux modèles artisanaux traditionnels. En outre, dans leur article suivant, ils ont montré que le taux d'erreur d'Ithemal était de 10 %, alors que le taux d'erreur du modèle de prédiction des performances d'Intel était de 20 % sur une variété de blocs de base dans de nombreux domaines différents.
L'outil facilite désormais l'apprentissage rapide des vitesses de performance pour toutes les nouvelles architectures de puce, indique Charith Mendis. Par exemple, les architectures spécifiques à un domaine, comme la nouvelle unité de traitement des tenseurs de Google utilisée spécifiquement pour les réseaux neuronaux, sont maintenant en cours de développement mais ne sont pas largement comprises.
"Si vous voulez former un modèle sur une nouvelle architecture, il vous suffit de collecter plus de données de cette architecture, de les passer dans notre profileur, d'utiliser ces informations pour former Ithemal, et vous avez maintenant un modèle qui prédit la performance", explique Charith Mendis.
Les chercheurs étudient désormais des méthodes pour rendre les modèles interprétables. Une grande partie du machine learning est une boîte noire, donc on ne sait pas vraiment pourquoi un modèle particulier a fait ses prédictions.
"Notre modèle dit qu'il faut un processeur, disons, 10 cycles pour exécuter un bloc de base. Maintenant, nous essayons de comprendre pourquoi", déclare Carbin. "C'est un bon niveau de granularité qui serait étonnant pour ce genre d'outils."
Ils espèrent également utiliser Ithemal pour améliorer encore plus les performances de Vemal et obtenir automatiquement de meilleures performances.