
Google a développé en 2017 un concept de Deep Learning distribué : le Federated Learning. Le géant mise aujourd’hui dessus pour répondre aux problèmes de confidentialité des données.
Le principe
Parmi les craintes légitimes liées à l’intelligence artificielle, figurent les interrogations liées à la confidentialité des données et à la sécurité de leur stockage. Conscient qu’un scandale autour d’une éventuelle fuite de données risquerait de lui être fortement préjudiciable, Google a mis au point un concept de Deep Learning distribué sur les terminaux : le Federated Learning, ou Apprentissage fédéré en français.
Cette solution permet un traitement directement embarqué sur les périphériques Android des données à analyser.
Il est important de comprendre que pour fonctionner, un modèle de Deep Learning n’a pas besoin de données. Celles-ci sont uniquement utilisées de manière à procéder à l’ajustement des poids des liaisons reliant les neurones artificiels au cours de la phase d’apprentissage. Ce sont les informations sur la structure du réseau de neurones et les valeurs des ces poids qui constituent l’ “intelligence artificielle”.
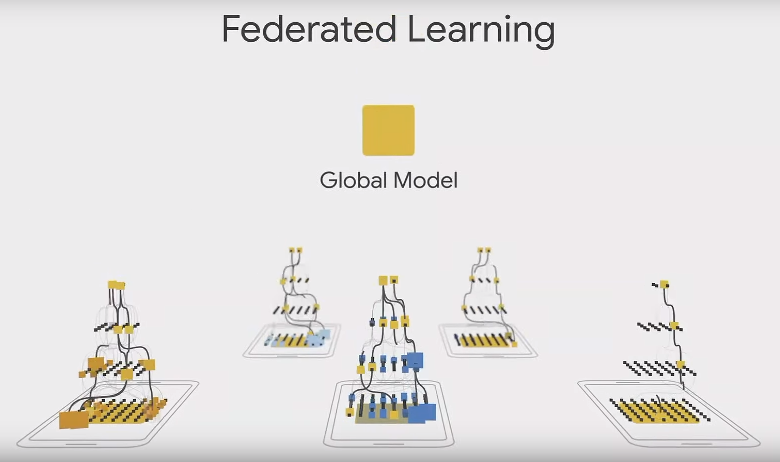
Traditionnellement, les données des utilisateurs sont tout de même transmises aux serveurs des éditeurs de services reposant sur l’intelligence artificielle, en vue de la phase d’apprentissage.
Avec le Federated Learning proposé par Google, un apprentissage basé sur les données est réalisé sur le terminal de l’utilisateur. Seuls les paramètres et poids du modèle de réseau de neurones entraîné sur le périphérique sont transmis aux serveurs Google. Ces derniers centralisent les apprentissages au sein d’un réseau de neurones global. Les données ne quittent pas le périphérique des utilisateurs.
Si cette solution permet d’éliminer les craintes liées à l’utilisation des données, on peut imaginer qu’elle a également l’avantage de réduire les coûts d’infrastructure liés au traitement de ces données, dont les résultats arrivent sur les serveurs de google déjà précalculés. Ce point est loin d’être négligeable quand on connaît les coûts de calculs associés au Deep Learning.
Le fonctionnement en détail
L’apprentissage se déroule sur une version allégée de TensorFlow lorsque le téléphone n’est pas utilisé (quid de la consommation batterie ?). Les données résultant de l’entraînement sont ensuite compressées et transmises aux serveurs Google en utilisant un Federated Averaging Algorithm.
Google n’a donc a aucun moment accès aux données d’origine. Cette sécurité est très appréciable mais n’est pas toujours suffisante : Il serait possible d’utiliser le modèle entraîné pour se renseigner sur l’utilisateur et ses préférences sans toutefois pouvoir accéder aux données d’origine.
C’est la raison pour laquelle, lorsque les données résultant de l’apprentissage sont remontées, seule la moyenne calculée à partir des résultats de plusieurs centaines d’utilisateurs est intégrée à la mise à jour du modèle central, ce qui vient ajouter une sécurité en terme de confidentialité.
Le Federated Learning, l’avenir du Deep Learning ?
Le Federated Learning est actuellement en test sur la suggestion automatique de GBoard. La solution développée par Google est extrêmement intéressante et vient répondre de façon convaincante à l’une des principales problématiques de l’IA.
Cependant, elle est difficilement généralisable : Google possède un avantage de taille, le fait de proposer le deuxième système d’exploitation le plus répandu au monde, avec une part de marché de 35.41%, derrière Windows à 39.89% (source). Or, cette solution nécessite par définition un traitement du côté du client. Chose largement facilitée lorsqu’on est l’éditeur d’un système d’exploitation et que l’on peut intégrer par défaut les briques nécessaires sur les périphériques clients.
Des solutions, telles que l’emploi de Tensorflow Js, peuvent permettre à des sites internet de lancer des traitements sur le navigateur de leur visiteur, mais est-ce suffisant pour gommer la barrière à l’entrée que vient ajouter ce type d’architecture fédérée en la matière ? Rien n’est moins sûr.
Si Google bénéficiait d’un avantage dans le domaine de l’intelligence artificielle grâce à son nombre d’utilisateurs, ce nouveau coup permet d’anticiper de probables renforcements de réglementations en terme d’intelligence artificielle, et par la même occasion, de lui conférer un nouvel avantage technologique.
L’apprentissage fédéré n’est pas un concept nouveau, le premier article de Google sur ce projet date d’ailleurs de 2017. D’autres acteurs en proposent, par exemple Owkin qui a lancé le projet collaboratif Substra pour la protection de la confidentialité des données médicales. Mais Google se montre bien décidé à passer à la vitesse supérieure sur le sujet.