
Dans chaque pays du monde, pour exprimer nos sentiments, nos émotions ou parfois même une idée, nous utilisons certaines expressions faciales. Toutefois, ces mimiques typiques de la conversation non verbale sont sujettes à interrogation : sont-elles les mêmes selon les contextes dans différentes parties du globe ? Google, en collaboration avec l'Université de Californie à Berkeley, a tenté de réaliser une analyse à grande échelle des expressions faciales utilisées au quotidien. Afin d'y parvenir, les chercheurs ont exploité les capacités des réseaux de neurones profonds (DNN).
Le défi des chercheurs : analyser les expressions faciales grâce à l'intelligence artificielle
Dans le domaine de la communication non verbale, les expressions faciales sont importantes. Les scientifiques se demandent depuis plusieurs années si l'association de ces mimiques avec un contexte particulier est quelque chose d'universel. Est-ce qu'un Japonais va instinctivement sourire en voyant ses amis, comme nous le faisons nous en France ? Est-ce que voir un aliment qui devrait habituellement être d'une autre couleur suscitera le dégout chez un Brésilien, comme il le susciterait chez la plupart des Français ?Pour répondre à cette question, les chercheurs sont obligés d'exploiter des millions d'heures de vidéos et des millions d'images provenant de plusieurs parties du monde afin d'en tirer des conclusions cohérentes. C'est en partant de cette problématique et de cette expérimentation que plusieurs chercheurs ont décidé d'utiliser le machine learning afin de mener à bien leurs recherches.
Plusieurs chercheurs de Google et de l'Université de Californie à Berkeley ont mené une étude pour analyser près de 6 millions de vidéos dans près de 144 pays. Pour réaliser cette tâche beaucoup trop longue à faire manuellement, les chercheurs ont exploité de multiples types de réseaux de neurones. L'ensemble de leurs résultats a fait l'objet d'une publication par Alan S. Cowen et Dacher Keltner, de l'UC Berkeley ainsi que par Florian Schroff, Brendan Jou, Hartwig Adam et Gautam Prasad, de Google Research.
La création d'une base de données grâce à plusieurs types de réseaux de neurones
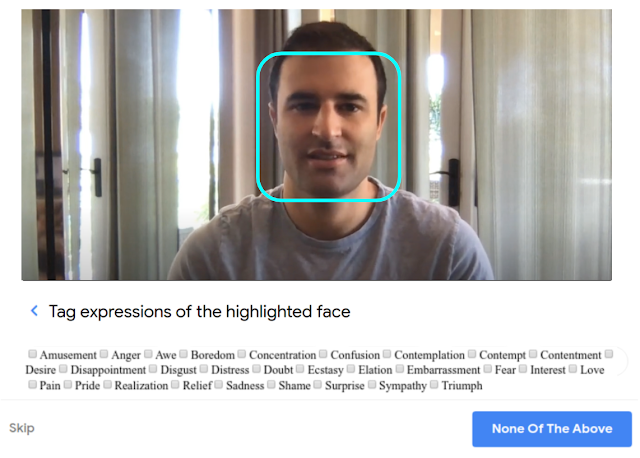
La première étape pour l'équipe de recherche fut de constituer le jeu de données nécessaires pour réaliser les expériences prévues pour l'étude. Des évaluateurs expérimentés ont effectué une recherche manuelle dans une immense banque publique de vidéos afin d'identifier celles qui pourraient convenir pour la suite du processus de recherche. Plusieurs catégories d'expressions ont été présélectionnées afin de faciliter cette tâche. Pour ne conserver que les vidéos correspondant à la région du monde où elles étaient censées être tournées, les chercheurs ont pris le temps de vérifier si l'environnement de la vidéo correspondait à celle indiquée par l'utilisateur ayant proposé le contenu.Ensuite, l'ensemble des visages de ces vidéos ont été identifiés à l'aide d'un réseau de neurones profond convolutif (CNN) qui suit leurs mouvements grâce à une méthode basée sur un flux optique classique. Ce système est similaire à l'API Google Cloud Face Detection. L'ensemble des expressions faciales de ces personnes ont été étiquetées dans 28 catégories distinctes à l'aide d'une plateforme ressemblant à Google Crowdsource. L'image ci-dessous vous présente le design de la plateforme ainsi que l'ensemble des étiquettes, il suffit de cliquer sur la bonne catégorie afin de classer l'expression faciale de la personne :
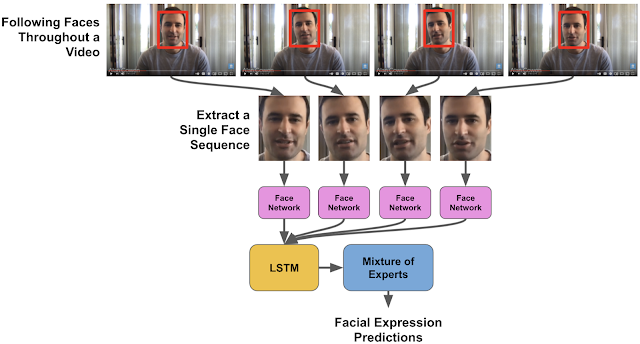
Un réseau Inception préformé a été utilisé pour extraire les caractéristiques les plus flagrantes pour chacune des catégories d'expressions faciales. Ces données ont été introduites dans un réseau de neurones LSTM dont la fonction est de modéliser la façon dont une expression faciale pourrait évoluer au fil du temps.
Pour garantir la qualité de l'ensemble des modèles et s'assurer qu'ils puissent réaliser des prédictions correctes en fonction des régions du monde, leur équité a été évaluée sur une base de données conçue préalablement à l'aide d'étiquettes d'expressions faciales semblables à celles utilisées par les chercheurs.
Illustration de l'ensemble du processus, en partant du CNN jusqu'au LSTM :
Pour reconnaître le contexte dans lequel la personne réalise une expression faciale, des DNN ont été exploités. Ils ont permis de modéliser les caractéristiques textuelles d'une vidéo comme son titre ou sa description avec le contenu visuel proposé (modèle vidéo-sujet). Un de ces DNN ne reposait d'ailleurs que sur des données textuelles (modèle texte-sujet). L'ensemble des modèles proposent des milliers d'étiquettes correspondant aux différents contextes.
Les deux expériences réalisées par les chercheurs
Deux expériences ont été conduites par les chercheurs afin de tirer des conclusions sur les expressions faciales à travers le monde :- Dans le cadre de la première expérience, ce sont 3 millions de vidéos publiques provenant de smartphones qui ont été exploités. L'ensemble des expressions faciales ont été corrélées grâce au processus précédemment explicité. Les chercheurs ont constaté que 16 types d'expressions faciales étaient associés à des contextes qui étaient les mêmes, peu importe la région du monde. Les gens rigolent s'ils écoutent une blague, ont une crainte s'ils regardent un feu d'artifice ou sont heureux s'ils regardent un évènement sportif positif à leur égard.
- Pour la seconde expérience, 3 millions de vidéos ont également été exploités. La base de données était différente de celle utilisée dans la première expérience. Toutefois, les contextes ont été annotés avec le modèle utilisant un LSTM qui ne prend en compte que les caractéristiques textuelles de la vidéo, et pas son contenu audiovisuel. Les résultats ont permis de mettre en évidence que les conclusions tirées de la première expérience n'étaient pas si différentes de ceux de la seconde expérience.
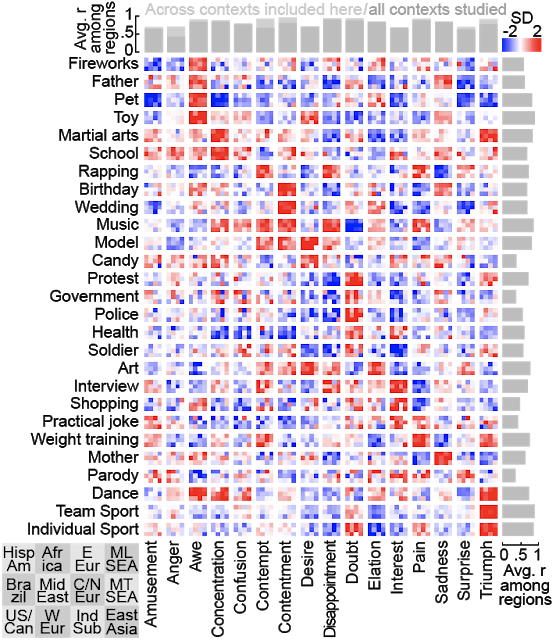
Dans les deux cas, les expressions faciales semblent être similaires, quelle que soit la culture des 12 régions du monde étudiées dans le cadre de cette recherche. Grâce à cette étude, les chercheurs ont souhaité montrer qu'il était tout à fait possible d'exploiter le machine learning pour mieux comprendre et identifier nos comportements et nos méthodes de communication, quelle que soit la culture ou la région d'appartenance des individus.