

Le mois dernier, la Direction Générale des Entreprises a présenté son rapport intitulé “Intelligence artificielle : État de l’art et perspectives pour la France”. Une étude qui dévoile un état de l’art technologique du domaine, une analyse sectorielle, le positionnement de la France en matière d’IA et les stratégies territoriales avant de développer les opportunités nationales ainsi que les principales recommandations de la DGE.
La dynamique d’innovation et d’investissement est forte dans le domaine de l’IA qui est sujet à une concurrence mondiale intense. En France, acteurs privés et publics ont multiplié par dix leurs investissements au cours des cinq dernières années afin de maîtriser cette technologie stratégique, porteuse de promesses.
Conscients des très forts enjeux liés à l’IA, la Direction générale des entreprises (DGE), le Commissariat général à l’égalité des territoires (CGET) et TECH’IN France ont confié à Atawao Consulting l’étude « Intelligence Artificielle – État de l’art et perspectives pour la France ». Après un état de l’art des différentes technologies du domaine, l’étude propose une méthode de classification des secteurs potentiellement les plus transformés par l’essor de l’intelligence artificielle et établit une analyse macroscopique de son adoption par ceux- ci. Elle approfondit ensuite cette analyse pour quatre secteurs : Énergie et environnement, Transport et logistique, Santé et Industrie. Pour chacun de ces quatre secteurs, un bilan des opportunités générées par l’IA est établi et une stratégie cible à adopter est proposée.
Dans sa dernière partie, l’étude dessine une feuille de route ainsi que des recommandations sectorielles et transverses qui permettront à la France et à ses entreprises de relever les défis en matière d’intelligence artificielle.
L’IA en France : analyse sectorielle et positionnement
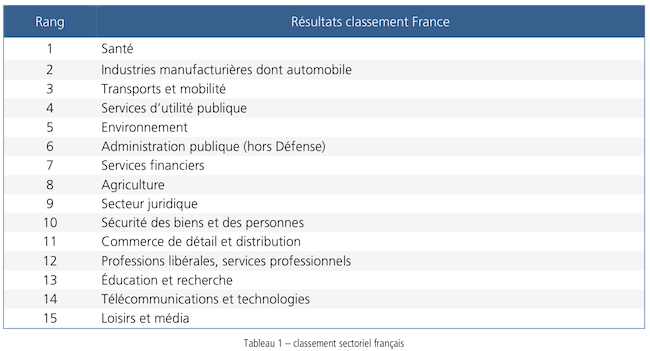
En ce qui concernant l’analyse sectorielle, les experts consultés pour la rédaction de ce rapport ont notamment mis en avant les secteurs considérés comme les plus impactés par l’intelligence artificielle en France aujourd’hui. La santé arrive en première position devant les industries manufacturières dont l’automobile devant les transports et la mobilité.
Selon la DGE, “analyser ses impacts sur les territoires, revient à analyser dans les années 90, l’impact spatial de la diffusion de l’internet mobile. Les acteurs interrogés n’ont pas encore de vision des impacts sur les territoires de la diffusion de l’IA ou sur l’attractivité d’entreprises en IA. Vouloir analyser de manière très spatialisée les effets de l’IA nécessiterait des études précises et localisées.
En conséquence, pour étudier le lien entre IA et territoires, l’approche retenue permet d’illustrer quelques expériences territoriales emblématiques à l’échelle mondiale et de faire le parallèle avec le territoire national. La méthode utilisée est la suivante :
- Étude des territoires les plus compétitifs à l’échelle mondiale sur les sociétés innovantes et les talents en IA.
- Illustration de l’attractivité de talents et d’investissements de ces territoires.
- Identification des usages innovants d’IA pour comprendre quelles actions locales peuvent être entreprises.
- Établissement des principaux constats et des recommandations associées.
3 645 start-up appartiennent au domaine de l’IA dans le monde dont 40 % aux États-Unis, 11 % en Chine, 10 % en Israël et 7 % au Royaume-Uni. Avec 109 start-up, la France est au septième rang mondial (3,1 %) proche du Canada, du Japon et de l’Allemagne.
Une ambition atteignable serait d’arriver au niveau du Canada, voire de dépasser celui-ci. Ce pays avec une économie et une population moins importante que la France possède 2 villes dans le peloton de tête mondial”.
Des stratégie territoriales inégales
Hors métropole francilienne, plusieurs grandes villes commencent à s’organiser sur la thématique IA (Lyon, Lille, Marseille, Toulouse…) indique le rapport.
“Avec l’aide de la puissance publique pour amplifier les efforts et dans le cadre d’une stratégie bien ciblée, Lyon pourrait rejoindre le peloton de tête mondial. Le fait d’apparaître dans le classement de tête de la localisation de l’innovation IA (représentée notamment par le volume de startups spécialisées sur la thématique) a pour vertu d’envoyer un signal aux différents acteurs (investissements, talents) et de contribuer à les attirer”.
Après une étude de la place de l’IA dans plusieurs autres pays tels que les États-Unis, la Chine ou encore Israël, le rapport s’est intéressé plus précisément à la France qui, d’après le rapport Roland Berger-Asgard, est la première nation continentale européenne et Paris la première ville européenne, en termes d’attractivité des start-up IA.
“Paris localise les deux tiers des start-up (73 sur 109). C’est aussi à Paris que se sont localisés les centres de R & D en IA de Facebook ou de Google par exemple. En mars 2018, le CNRS, L’Inria, l’Université PSL, Amazon, Criteo, Facebook, Faurecia, Google, Microsoft, Naver Labs, Nolia Bell Labs, PSA, Suez et Valeo, se sont associés pour créer l’Institut PRAIRIE. Plus largement, 45% des laboratoires français publics et privés, disposant de compétences IA sont localisés en Île-de-France.
Cette dynamique autour de l’IA en Île-de-France, se traduit par une augmentation des demandes de profils qualifiés. Selon l’Association pour l’emploi des cadres (Apec), le nombre d’offres d’emploi pour des projets d’intelligence artificielle a doublé en 201716 avec 2 398 postes dont 63 % des entreprises en Île-de-France.
L’annonce récente faite par la région Île-de-France du lancement du Plan « IA 2021 » devrait renforcer cette polarisation autour de Paris et de sa région. Cet état de fait n’est pas anormal, car même à l’échelle de très grands pays comme les États-Unis ou la Chine, les principaux pôles d’attractivité de l’innovation IA sont limités (sept aux États-Unis et deux en Chine). On peut toutefois s’interroger sur un modèle « à la française » qui verrait travailler en réseau les spécialistes IA des quinze pôles industriels français d’envergure mondiale.
Comme le rappelle le rapport, “la France ne fait pas exception aux constats que l’on peut faire à l’échelle internationale, au sein de grandes nations industrielles ou émergentes : les développements récents et les promesses de l’IA étant des opportunités assez nouvelles et peu matures, les politiques publiques dédiées, commencent seulement elles aussi, à apparaître. Elles sont conçues à l’échelle des pays (politiques publiques nationales) et existent peu aux échelles locales.
En effet, à l’échelle mondiale, à part quelques grandes régions (la région Ile de France par exemple ou les exemples chinois cités plus haut) et de très grandes métropoles (Londres comme illustré plus haut), très peu de territoires ont conçu des politiques publiques spécifiquement tournées vers la promotion de l’IA.
En France, le constat est le même : la région Ile de France est la seule, à date, à avoir conçu des politiques publiques spécifiquement dédiées à la diffusion des usages IA et à l’attraction de talents et d’entreprises sur cette thématique.
Par ailleurs, l’examen des différents instruments de développement économique des territoires que sont le SR2I (Schéma régional de développement économique d’innovation et d’internationalisation), les pôles de compétitivité ou encore les TIGA (Territoires d’Innovation- Grande Ambition), n’a pas permis de dégager des orientations fortes des régions en matière d’IA. Ces différents dispositifs intègrent tous le numérique, comme levier d’innovation et de développement économique. A titre d’exemple, plusieurs pôles de compétitivité sont spécialisés autour de cette thématique et comportent probablement divers projets collaboratifs intégrant de l’IA.
Compte-tenu du potentiel de forte transformation apporté par l’IA sur un grand nombre d’activités, il est souhaitable que les territoires s’emparent spécifiquement de cette thématique et mettent en œuvre des diagnostics visant à identifier leurs forces et faiblesses avant de concevoir des stratégies adaptées.
Il sera également nécessaire de fédérer et coordonner ces initiatives locales. L’IA française n’est pas d’une taille suffisante pour permettre une dispersion des initiatives. L’IA requiert, quelles que soient les entreprises, les localisations ou les thématiques concernées, le regroupement de moyens et la réalisation d’économies d’échelles. Qu’il s’agisse de la mise à niveau des ressources de calcul intensif ou de cloud, de l’organisation de rencontres d’envergure internationale, de la structuration de la formation, et avant tout l’enrichissement du patrimoine de ressources immatérielles, le développement de l’IA française doit être organisé sur un mode combinant la recherche de l’excellence et la mise en réseau des acteurs les plus performants.
Ainsi il apparaît essentiel de favoriser l’émergence d’une démarche fédérative de l’IA française. A l’instar des exemples étrangers identifiés plus haut, il faudra associer les collectivités territoriales et notamment impliquer les Régions, qui financent une grande partie de l’effort de recherche et d’industrialisation. La dimension IA devra être prise en compte plus systématiquement dans les grandes politiques de soutien au tissu entrepreneurial et économique et ainsi être intégré par exemple dans la dynamique du programme « Territoires d’industrie ».”
Voici les opportunités pour la France présentent le rapport :
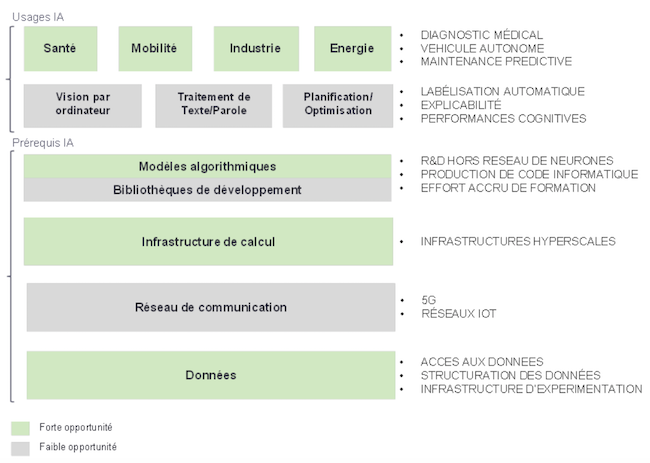
Développer et sécuriser la recherche en intelligence artificielle en France
La révolution de l’intelligence artificielle en est encore à ses prémices. Les techniques développées jusqu’à maintenant ne soutiennent pas la comparaison avec les performances cognitives évoluées des humains. Les progrès actuels, spectaculaires pour certains usages très spécifiques, ne peuvent masquer l’immense chantier de recherche à produire sur les vingt prochaines années pour reproduire efficacement les capacités d’apprentissage uniques des humains.
C’est l’une des premières opportunités pour la France. L’enjeu est double : former et retenir en France les meilleurs chercheurs en intelligence artificielle. Cela suppose de développer des efforts dans plusieurs domaines :
- Prioriser les investissements sur des champs de recherche actifs (apprentissage avec peu de données, robustesse des modèles face à la perturbation, explicabilité, etc.).
- Stimuler les collaborations transdisciplinaires dans les appels à projets, car l’IA est une discipline qui nécessite une forte collaboration entre expertise scientifique, métier et informatique.
- S’assurer que les aides et dispositifs fiscaux de soutien à la R & D ciblent des verrous scientifiques et technologiques prioritaires et non des travaux d’ingénierie sans dépassement de l’état de l’art.
- Valoriser la recherche appliquée en stimulant par exemple la production d’algorithmes documentés en support à la recherche et pas seulement de publications scientifiques.
- Inciter les entreprises privées à compléter fortement les financements publics insuffisants en IA. Lorsque le MIT annonce une décision d’investissement de 1 milliard de dollars dans l’IA, – on comprend qu’elle ne peut pas être traitée à égalité avec les autres thématiques académiques.
- Encourager le secteur privé à mettre en place une R & D à long terme sur l’intelligence artificielle. Il dispose des données, de l’expertise métier, et des enjeux à adresser. En développant une R & D forte ce sujet, il aidera à faire monter en puissance la recherche académique.
- Mettre en lumière (visibilité dans les grands congrès scientifiques, développement de chaires de recherche, etc.) l’élite des centres de recherche français pour structurer autour d’eux des équipes de pointe dans le domaine.
- Inscrire la trajectoire de la recherche française dans une perspective européenne pour mutualiser les efforts. Il s’agira ici non seulement de s’inscrire dans des lignes directrices proposées par la Commission européenne pour générer une masse critique d’efforts de recherche, mais aussi d’approfondir certains sujets avec des pays volontaires. Compte tenu de l’importance du Royaume-Uni sur la thématique IA en Europe, il est crucial que ce pays fasse partie de cette alliance.
Généraliser les offres de formations
Les technologies IA sont des GPT (General Purpose Technologies), c’est-à-dire, des technologies transverses à effet de rupture comme la machine à vapeur, l’électricité, Internet… Aujourd’hui, les technologies étant majoritairement en open source donc accessibles, le défi le plus urgent est dans le développement des compétences qui permettraient de développer ce patrimoine de ressources.
De ce fait, il est crucial pour accompagner leur diffusion, d’intensifier la formation du plus grand nombre d’effectif possible pour que chaque secteur dispose de compétences pertinentes pour ses propres applications.
La France dispose d’atouts importants: grand nombre et variété des écoles d’ingénieur, enseignement mathématique d’excellent niveau, autres formations pouvant développer des compétences de développement logiciel et de machine learning (ex. : formations courtes de type BTS ou IUT pour les premiers niveaux, universitaires généralistes dans des disciplines scientifiques pour des formations plus avancées…).
Se focaliser sur les applications sectorielles de l’IA
Les technologies algorithmiques de base en intelligence artificielle sont largement open source et accessibles à l’ensemble des innovateurs. Elles sont mises au point dans les laboratoires de recherche académiques comme l’Inria avec SciKit-Learn et contribuent au développement des connaissances. Ces technologies concernent tout ce qui est transversal : traitement du texte, de l’image, transformations mathématiques, modélisation des réseaux de neurones, etc. Encourager le développement de ces technologies répond essentiellement à des enjeux scientifiques.
Les enjeux économiques se portent de plus en plus sur des usages sectoriels de l’intelligence artificielle : diagnostic médical, maintenance préventive, détection automatique de piéton, vidéosurveillance automatisée, aide à la vente, etc.
Pour les secteurs grand public (bien-être et prévention en santé, moteur de recommandation pour le Retail, moteurs de recherche, assistants vocaux, etc.), compte tenu de la domination des GAFAM/BATX (ex. : Amazon a une équipe de plus de 5 000 personnes sur les assistants Alexa et Echo) et de l’importance des moyens investis, la France ne dispose pas d’atouts spécifiques. Il n’est pas impossible que des acteurs nationaux de premier plan apparaissent, mais la probabilité est faible et les besoins de ressources conséquents. En conséquence, l’État doit focaliser son accompagnement et ses ressources sur des secteurs B2B ou B2B2C. À l’échelle mondiale, le niveau de maturité des acteurs est sensiblement équivalent dans les secteurs B2B.
L’IA pour la gestion de l’attrition client ou de la fraude dans le secteur bancaire ou pour la maintenance préventive dans l’industrie possède un niveau de maturité proche de celui d’un voisin européen ou d’un acteur nord-américain. Sur ces segments, la France dispose déjà de grands acteurs établis (Dassault Systèmes) ou récents (Criteo), mais surtout d’un écosystème prometteur de start-up de premier plan (Dataiku, Shift Technology, Navya, Easymile, Stanley Robotics, Prophesee, etc.).
À l’aide de la BPI, il faut structurer autour de ces start-up un écosystème complet (autres start-up, grandes entreprises, centres académiques, clients…) pour accroître les passerelles et les coopérations entre les acteurs, rendre visible et attractive les filières d’excellence française et mettre en lumière un potentiel pour le recrutement.
Encourager massivement le développement d’infrastructures numériques
Les acteurs majeurs dans le domaine de l’intelligence artificielle sont aussi ceux qui disposent des plus grandes infrastructures de calcul à leur disposition et ce n’est pas une coïncidence. Dans la course à l’automatisation de tâches cognitives avec des performances comparables aux humains, les leaders s’appuient sur des infrastructures qui permettent un passage à l’échelle des modèles de réseaux de neurones mis au point. Ces infrastructures permettent d’entraîner les modèles avec plusieurs millions de données dans un temps acceptable.
L’Europe et la France en particulier, accusent un retard très important sur l’utilisation de grandes infrastructures de calcul. Très peu d’acteurs ont compris l’importance stratégique de ce sujet technologique. Pour faire une analogie avec la géographie, les États-Unis, l’Europe ou la Chine représentent chacun autour de 7 % de la superficie du globe. En géographie numérique représentée par les centres de données hyperscales, sur 400 infrastructures de ce type dans le monde, 44 % sont aux États-Unis, 20 % en Europe, 8 % en Chine et moins de 1 % en France. Les États-Unis numériques représentent plus de six fois leur taille géographique réelle.
Au-delà de ces chiffres, encourager massivement le développement des acteurs d’infrastructures numériques en Europe et en France est fondamental pour comprendre et maîtriser le résultat de l’entraînement des modèles. La compréhension des mécanismes d’entraînement, c’est-à-dire l’explicabilité, permet de vérifier si une intelligence artificielle respecte les contraintes, les lois, les règles, les règlements ou l’éthique. Dans le cas contraire, l’IA devient une boîte noire, sans que l’on puisse identifier quelles données ont servi à l’entraînement et si ces données respectent toutes les contraintes de diversité, complétude ou précision nécessaire. Un centre de données hyperscales est le lieu où sera mis au point l’ensemble des intelligences artificielles de production.
Lancer des expérimentations ambitieuses
Le principal objectif des actions proposées est de favoriser au maximum l’expérimentation de technologies d’intelligence artificielle sur le territoire. La notion d’expérimentation en environnement et conditions réelles est clé pour fédérer largement tous les acteurs impliqués : acteurs publics des administrations centrales et territoriales, laboratoires de recherche, enseignement, écosystèmes innovants, start-up, grands groupes, financeurs et grand public.
Ce besoin d’expérimentation à grande échelle est notamment à l’œuvre dans le cadre de la mise au point d’un véhicule autonome et mobilise déjà largement l’ensemble des acteurs en ordre plus ou moins dispersé. C’est une dynamique qui est pertinente à reproduire dans le cadre d’autres domaines d’application de l’IA. Ces zones d’expérimentation offriraient un cadre administratif et légal, une infrastructure produisant de la donnée en volume et en flux et une organisation permettant de mettre en application l’IA (utilisateurs, experts, etc.).
Dans le domaine de la santé par exemple, l’accès simplifié à une ou plusieurs structures de soins pour expérimenter à grande échelle des solutions innovantes accélérerait leur mise au point. Pour une structure qui souhaite expérimenter (un laboratoire de recherche, une start-up ou un grand groupe), un accès simplifié signifierait : un processus simple de signature d’une convention d’expérimentation, le déploiement rapide pendant le temps nécessaire à l’expérimentation au sein d’un service hospitalier, l’accès régulier aux experts métiers et à des données de l’hôpital. Pour améliorer l’accès aux données, une infrastructure pourrait compléter les systèmes existants pour garantir la disponibilité d’un maximum de données.
Dans le domaine des transports et de la mobilité, une ville entière de plusieurs milliers d’habitants pourrait être transformée pour servir de champ d’expérimentation à l’ensemble des technologies innovantes du véhicule autonome. Une infrastructure pourrait être mise en place pour fournir des données et une cartographie de très grande précision, nécessaire à la mise au point de toutes les situations conduite. En dehors d’une ville, d’autres zones d’expérimentation pourraient être mises en place comme une portion d’autoroute de plus de 100 km, une zone montagneuse, etc.
Dans le domaine de l’énergie, un ou plusieurs écoquartiers regroupant l’ensemble des technologies de transition énergétique (production énergétique intermittente, gestion intelligente de la demande, véhicules électriques, etc.) pourraient être mis à disposition des sociétés souhaitant développer des technologies d’IA dans le domaine.
Faciliter un accès rapide aux données
Le second objectif des actions vise à rendre le plus accessible possible toutes les données disponibles pendant la phase de recherche et de développement de technologies d’intelligence artificielle. Les actions proposées visent à créer une distinction explicite et légale entre la phase d’expérimentation et celle de l’usage commercial de données. Cette distinction peut permettre de simplifier considérablement l’accès aux données pendant les phases de mise au point.
La facilité d’accès aux données représente un enjeu clé pour assurer la pérennité des développements de technologies d’intelligence artificielle en France. En santé par exemple, la très grande majorité des technologies d’IA développées par des start-up créées en France l’ont été avec des données provenant d’autres pays, induisant un risque de délocalisation des activités dans ces pays et d’affaiblissement de l’écosystème français .
Principales recommandations du rapport
Des recommandations d’actions sont proposées dans plusieurs domaines. Toutes les recommandations proposées favorisent la création ou l’accès à des données en flux (indispensable à la mise au point d’algorithmes d’apprentissages performants) et/ou favorisent également le développement d’expertises nationales en Intelligence artificielle en développant les lieux d’expérimentation de technologies d’IA.
Créer des zones d’expérimentation à l’échelle d’un hôpital ou d’un réseau de soins
Cette recommandation correspond à créer plusieurs zones d’expérimentation accessible à tous les acteurs innovants, notamment en intelligence artificielle. Chaque zone d’expérimentation permettrait d’accéder à un cadre administratif défini, une infrastructure communicante, des données et des acteurs disponibles pour tester des innovations.
Un premier type d’expérimentation pourrait consister à transformer un ou plusieurs hôpitaux existants en centre d’expérimentation de technologies numériques dont l’intelligence artificielle. Un investissement en infrastructure serait réalisé dans l’hôpital pour rendre accessible l’ensemble des données médico-économiques aux sociétés voulant innover. Chaque service de l’hôpital devra accepter de tester des innovations pendant une période de plusieurs mois. La dimension légale serait également totalement prise en compte par l’hôpital expérimental pour éviter aux acteurs innovants un travail lourd et fastidieux de mise en conformité.
Un second type d’expérimentation correspond à rendre accessible l’ensemble des données des professionnels de santé à l’échelle d’une ville de plusieurs milliers d’habitants : pharmacie, médecine générale, structures de soins, hospitalisation à domicile, etc. L’objectif serait le même, permettre à des acteurs innovants d’expérimenter facilement et rapidement des technologies d’intelligence artificielle. Les investissements seraient de même nature que pour l’hôpital (infrastructure communicante entre les acteurs, données, cadre légal d’expérimentation, etc.).
Ces expérimentations nécessiteraient plusieurs types d’investissements de nature différente :
- La définition d’un cadre administratif et légal particulier et standardisé permettant d’expérimenter sur le lieu.
- Un investissement en infrastructure numérique (capteurs, réseaux, Datacenter) pour permettre à l’ensemble des équipements de santé de fournir des données numériques sur leur usage, les mesures cliniques et biologiques qu’ils permettent, les statuts de fonctionnement, etc.
- La fourniture d’un système d’information capable de collecter ces données pour les rendre disponibles.
- Une organisation dédiée à l’expérimentation pour accueillir tous les acteurs souhaitant innover.
Cette recommandation vise à créer les conditions permettant de tester des innovations en IA avec des délais de mise en œuvre les plus réduits possible.
Créer un cadre légal d’expérimentation à partir de données
La recommandation correspond à créer un cadre légal rendant accessible plus rapidement et facilement des données des structures de santé pour expérimenter des services basés sur leur usage. La législation permettrait aux structures de soins en France de fournir rapidement leurs données aux chercheurs ou aux acteurs innovants qui en feraient la demande.
Le cadre pourrait être basé sur la création d’une liste de lieux d’expérimentations disponibles pour tous les acteurs souhaitant innover. C’est un mécanisme qui existe déjà pour la gestion de la liste des hébergeurs de données de santé par exemple. La gestion de cette liste est l’une des missions de l’Agence Française pour la santé numérique (ASIPSANTE). Une mission supplémentaire pourrait être confiée à cette agence pour créer et maintenir une liste des acteurs pouvant utiliser des données cliniques ou biologiques dans le cadre d’expérimentations.
Cette initiative pourrait s’inscrire dans le cadre de France Expérimentation créée en 2016 qui vise à simplifier le processus administratif pour les acteurs souhaitant innover. Elle doit être l’une des missions prioritaires du « Health Data Hub » annoncé par le ministère de la Santé en juin 2018. Les données seraient fournies à titre expérimental, pour une durée limitée par exemple.
Développer les challenges de données en santé
Cette recommandation correspond à développer les challenges de données en santé sur le même modèle que le challenge Epidemiume en cancérologie. Un challenge en santé permet de mesurer l’évolution de la performance des algorithmes de diagnostic ou de suivi thérapeutique dans le temps.
Un nouveau challenge pourrait être structuré par aire thérapeutique (diabète, maladies cardiovasculaires, maladies du foie, etc.) et confié à l’institut référent en santé dans chaque domaine comme l’Institut du cerveau et de la moelle épinière.
En termes d’investissement important, chaque challenge nécessiterait la création d’un Dataset multidimensionnel (physiologie, environnement, génétique, etc.) pour tester les algorithmes développés. Comme pour Epidemiume, l’organisation portant le challenge regrouperait laboratoires, structures de recherche et innovateurs.
Créer un marché protégé pour les start-up en santé
La structure de remboursement des soins en France ne favorise pas le développement de services payants indispensables au financement des start-up dans la durée.
Cette recommandation correspond à créer une législation motivant les structures de soins à réaliser une partie de leurs d’achats technologiques auprès de structures européennes de petite taille. L’objectif est de créer un environnement de marché propice à l’émergence de sociétés viables économiquement. Ce type d’initiative a déjà été mis en place par le Conseil régional d’Île-de-France en mars 2017. Cette initiative, de type « small business act », impose d’investir 2 % de la commande publique francilienne dans des achats auprès de start-up innovantes.
Un tel dispositif pourrait être mis en place pour le secteur de la santé de manière à créer un débouché pour les start-up.
Créer des zones d’expérimentation de véhicules autonomes à l’échelle d’une ville ou d’une situation de transport à risque (autoroute, zone montagneuse)
Cette recommandation correspond à créer plusieurs zones d’expérimentation accessible à tous les acteurs innovants dans le domaine de la conduite autonome.
Une première zone d’expérimentation correspondrait à une ville d’au moins 50 000 habitants, représentative de situations de conduite en milieu urbain, mais avec une taille qui limiterait le besoin d’investissement en infrastructure communicante.
Une seconde zone d’expérimentation correspondrait à une situation de conduite particulière :
- Une autoroute (plus de 100 km) pour les situations de conduite rapide.
- Une zone montagneuse pour les situations de conduite sur routes sinueuses, à forte déclinaison et/ou en conditions hivernales.
Ce projet nécessitera plusieurs types d’investissements de nature différente :
- La définition d’un cadre administratif et légal particulier et standardisé permettant d’expérimenter sur les lieux.
- Un investissement en infrastructure numérique (capteurs, réseaux, Datacenter) pour permettre à l’ensemble des équipements de transport (signalisation, mesure du trafic, etc.) de fournir des données numériques sur leur usage, leur statut de fonctionnement, etc.
- La fourniture d’un système d’information capable de collecter ces données pour les rendre disponibles.
- Une organisation dédiée à l’expérimentation pour accueillir tous les acteurs souhaitant innover
Cette recommandation nécessitera de créer les conditions permettant de tester rapidement une innovation dans le domaine de l’intelligence artificielle.
Amplifier les zones d’expérimentation à l’échelle d’un écoquartier
Cette recommandation correspond à créer plusieurs zones d’expérimentation correspondant à la taille d’un écoquartier de plusieurs milliers habitants. Cet écoquartier comprendra l’ensemble des technologies de transition énergétique : smart city, production et consommation intermittente, véhicule électrique, transport en commun électrique, etc.
Cette recommandation pourra être reliée à un des programmes Smart Energy en cours en vue de contribuer à amplifier par l’IA, des expérimentations déjà lancées :
- FLEXGRID (Conseil régional de Provence-Alpes-Côte d’Azur),
- SMILE (Conseil régional de Bretagne, en lien avec les Pays de la Loire)
- YOU & GRID (métropole européenne de Lille, en lien avec les Hauts-de-France).
Cela nécessitera plusieurs types d’investissements de nature différente :
- La définition d’un cadre administratif et légal particulier et standardisé permettant d’expérimenter sur les lieux.
- Un investissement en infrastructure numérique (capteurs, réseaux, Datacenter) pour permettre à l’ensemble des équipements de fournir des données numériques sur leur usage, leurs statuts de fonctionnement, etc.
- La fourniture d’un système d’information capable de collecter ces données pour les rendre disponibles.
- Une organisation dédiée à l’expérimentation pour accueillir tous les acteurs souhaitant innover.
Cette recommandation nécessite de créer les conditions permettant de tester rapidement une innovation dans le domaine de l’intelligence artificielle.
Généraliser et normaliser le recueil de données de maintenance
Cette recommandation vise à inciter les acteurs industriels à accélérer la mise d’un cadre global (infrastructures numériques, compétences, processus), favorisant le développement des activités de maintenance prédictive.
Alors que la refonte des systèmes de pilotage des usines du futur intégrant des algorithmes d’IA sera probablement dominée par les grands acteurs actuels (Siemens, Bosch…), les innovations qui touchent à la maintenance sont plus variées (ex. : applications non invasives de machine learning pour capter et analyser en temps réel des données des machines). Elles offrent un potentiel plus fort pour des start-up et des PME nationales. Certaines connaissent déjà un développement prometteur (ex.: TELLMEPLUS, Cartesiam, Scorteo…).
Les activités de maintenance sont profondément transformées par le déploiement progressif et conjoint de l’Internet industriel (Internet des objets appliqué au domaine industriel), de plateformes de Big Data et d’applications d’IA. Grâce à ces mutations, des domaines d’activité, des processus et des données en silo vont pouvoir être rapprochés et des équipements jusque-là faiblement suivis, pourront l’être davantage.
L’enjeu est de mieux comprendre le comportement des équipements et anticiper les défaillances éventuelles, de disposer d’informations en temps réel permettant un meilleur pilotage humain, économique et financier des opérations de maintenance (gestion des interventions, gestion des stocks, relation client…).
La puissance publique pourrait :
- Favoriser les échanges entre les acteurs pour renforcer les normes portant sur les activités de maintenance, intégrant plus systématiquement l’instrumentation par l’Internet industriel et l’analyse prédictive. Les bénéfices à mettre en avant auprès des industriels pour susciter leur adhésion sur cette évolution sont nombreux : gains économiques liés à une optimisation des opérations de maintenance, réduction des risques industriels et des coûts associés en sécurité, etc.
- Financer, sur la base d’appels à projets, les premiers pilotes.
Stimuler la production de données environnementales chez les industriels
Cette recommandation est complémentaire à celle présentée dans les recommandations pour le secteur Énergie- Environnement, intitulées : « renforcer les normes et règlements sur l’instrumentation et la collecte de données portant sur la qualité de l’air ». Elle vise à enrichir sensiblement la quantité, la variété, le degré de finesse et la fraîcheur des données relatives à la pollution industrielle.
L’industrie manufacturière est responsable du rejet d’un grand nombre de polluants atmosphériques. Elle est notamment le premier émetteur de zinc, de sélénium, de plomb, de mercure, de chrome, de cadmium, d’arsenic, de SF6 (hexafluorure de soufre), de PFC (perfluorocarbures) et de composés organiques volatils dans l’air.
Plusieurs maladies graves (cancers, troubles du développement chez le fœtus, affections ORL complexes, etc.) sont corrélées à ces émissions avec des risques à la fois pour les salariés et les riverains.
Aujourd’hui, les pouvoirs publics émettent des lois et règlements a priori, vérifiés par des audits ponctuels.
La recommandation correspond à favoriser, dans les usines, le déploiement plus systématique d’instruments (capteurs, robots) de collecte de données environnementales sur les rejets dans l’atmosphère à des fins de traitement par des algorithmes d’intelligence artificielle.
La recommandation s’appuierait sur deux leviers: la normalisation et le cofinancement de pilotes d’expérimentation.
- Faire effet de levier sur la normalisation.
- Augmenter les mesures : promouvoir le monitoring par des incitations spécifiques.
- Revisiter/réviser les normes existantes avec une vision digitalisation et IA.
- Contribuer au financement des expérimentations.
- Concevoir et mettre en œuvre un crédit d’impôt pour investissement sur le monitoring sur des usines existantes.
- Lancer des appels à projets.
Former rapidement des techniciens, des ingénieurs et des décideurs de l’industrie aux cas d’usages et aux techniques probabilistes de l’IA
Cette recommandation vise à acculturer et à former un grand nombre de dirigeants, ingénieurs et techniciens du secteur industriel, en particulier, dans sa composante Petites et Moyennes Industries (PMI) aux apports potentiels de l’intelligence artificielle. Cette formation devrait porter sur :
- Le partage d’expérience autour de cas d’usage concrets : visites de sites ayant déployé des applications IA, plateforme de partage de cas d’usage et espaces de discussion.
- Les méthodes probabilistes, les acteurs et les outils informatiques disponibles pour déployer des usages.
Pour être efficaces et ciblées, ces démarches de formation pourraient être :
- Promues par les pouvoirs publics.
- Mises en œuvre en partenariat entre l’Alliance Industrie du Futur, les différents syndicats industriels et des acteurs spécialisés du numérique.
- Déployées sur le terrain avec l’aide des collectivités locales et des chambres de commerce et d’industrie.
Créer un Datacenter de projets en data science en s’appuyant sur les expertises d’OVH et de TERALAB
Selon l’étude réalisée par l’association ALLISTENE regroupant notamment le CEA, l’IMT, le CNRS et l’Inria, la France ne dispose pas d’infrastructure de calcul pour réaliser des projets en IA permettant de répondre aux défis actuels : gestion des SmartGrids, changement climatique, mise au point du véhicule autonome, etc.
L’une des plus grandes infrastructures publiques, le Centre régional Informatique et d’Applications numériques de Normandie (CRIANN) dispose d’une puissance de 600 TFLOPS (CPU), 170 TFLOPS (GPU) et 2,5 Po de capacité de stockage. Le système de transcription de la parole DEEPSPEECH de BAIDU (un réseau de neurones comportant entre 18 et 100 millions de neurones selon le modèle) a nécessité l’entraînement de plus de 500 modèles, chaque modèle mobilisant 50 TFLOPS sur des processeurs GPU. Ramené aux capacités du CRIANN, l’entraînement aurait mobilisé l’ensemble des ressources pendant plus d’un an, ce qui n’est pas réaliste.
Pour répondre aux besoins d’entraînement de très grands réseaux de neurones, nous recommandons de créer une infrastructure de data science hyperscale souveraine et capable d’adresser tous les problèmes d’IA. Le projet ne vise pas à créer une nouvelle infrastructure de données, mais à s’appuyer sur des initiatives et moyens déjà largement disponibles. Concrètement, le projet pourrait reposer sur un partenariat entre la structure de TERALAB et l’infrastructure de la société OVH, chacun disposant des expertises complémentaires nécessaires.
TERALAB, de par l’expérience acquise depuis six ans sur des projets de recherche en data science avec de grands acteurs privés, assurerait la maîtrise d’ouvrage du projet. OVH, en tant que seul acteur majeur européen d’infrastructure serait responsable de la maîtrise d’œuvre du projet.
L’infrastructure offrirait des services de stockage et de calcul haute performance, simples, sécurisés et abordables pour tous les projets en data science. À terme, une partie des moyens de calculs des universités pourrait basculer sur cette infrastructure.
Encourager des projets centrés sur les assistants intelligents pour le grand public
L’intelligence artificielle dans le traitement du langage naturel est l’un des axes les plus dynamiques aujourd’hui : recherche vocale, assistant du conseiller, assistant d’achat, etc.. Mais la grande majorité des innovations dans ce domaine vient des GAFAs qui adressent leurs propres besoins, ou de start-up qui adressent les besoins de grandes entreprises (B2B).
L’assistant intelligent réellement à l’usage des besoins quotidiens du grand public ne bénéficie pas de la même dynamique, compte tenu notamment de la plus grande difficulté pour trouver un modèle économique rentable. Un tel assistant serait utile, par exemple, pour :
- Faciliter la comparaison d’offres complexes comme des prêts ou des propositions contractuelles.
- Simplifier une démarche administrative.
- Aider à gérer sa santé.
Le développement d’assistants intelligents pour le grand public pourrait se manifester par des appels à projets ou le lancement de marchés publics à destination de start-up.
Créer des formations en ligne (MOOC) sur l’IA et les produits numériques
Compte tenu du caractère récent de l’IA, la majorité des acteurs interrogés manquent de profils adaptés à des projets d’intelligence artificielle en particulier, et en data science en général. Ces profils devraient posséder une triple expertise métier, mathématique et technologies digitales. Le besoin est urgent et nécessite un effort de formation rapide au moins pour travailler sur des problèmes simples de machine learning (classification, régression) à partir de données disponibles.
Un effort de formation pourrait être réalisé au travers de contenus de formation en ligne (MOOC) adressant les principaux sujets : problèmes de data science, bases statistiques, principales techniques de machine learning, outils et framework, passage à l’échelle des problèmes de data science, conception de produits numériques, etc.
Ces contenus de formation n’existent pas en nombre et en qualité suffisante en langue française. Les contenus de qualité proviennent de sociétés (Coursera) ou d’organismes universitaires américains (cours de Machine Learning d’Andrew Ng à Stanford University).
Un projet de MOOC sur les sujets clés d’IA pourrait être confié à un ensemble d’universités et de grandes écoles qui ont tous des initiatives de travail dans le domaine.
Pour lire le rapport dans sa totalité, rendez-vous sur le site de la DGE.