
Yang Li et Gang Li, chercheurs à Google Research ainsi que Brian Wang de l'Université de Toronto ont étudié et démontré la viabilité de l’utilisation de grands modèles linguistiques (LLM) pour permettre diverses interactions linguistiques avec les interfaces utilisateur mobiles. Ils ont présenté l'article consacré à leurs travaux « Enabling Conversational Interaction with Mobile UI using Large Language Models » à la CHI 2023, conférence internationale sur l’interaction homme-machine, qui s'est déroulée à Hambourg fin février dernier. Il a également fait l'objet d'une publication sur arXiv.
Les assistants intelligents, Alexa, Google Assistant et Siri, ont considérablement fait progresser l'interaction basée sur le langage pour effectuer des tâches quotidiennes simples telles que la mise en place d'un minuteur, mais rencontrent encore des limites dans le soutien de l'interaction conversationnelle dans les interfaces utilisateur mobiles, où de nombreuses tâches utilisateur sont effectuées. Par exemple, ils ne peuvent pas répondre à une question d'utilisateur sur des informations spécifiques affichées à l'écran, ne possédant pas une compréhension computationnelle des interfaces utilisateur graphiques (GUI).
Récemment, les grands modèles de langage pré-entraînés tels que GPT-3 et PaLM ont démontré leur capacité à s’adapter à diverses tâches en aval lorsqu’ils sont sollicités avec quelques exemples de la tâche cible. Cependant, peu de travaux ont été menés pour comprendre comment les LLM, entraînés avec des langues naturelles, peuvent être adaptés aux GUI pour des tâches d’interaction
Cet article étudie la faisabilité de permettre des interactions conversationnelles polyvalentes avec des interfaces utilisateur mobiles à l’aide d’un seul LLM.
Activation de l’interaction conversationnelle avec l’interface utilisateur mobile à l’aide de grands modèles de langage
En catégorisant les scénarios de conversation entre les utilisateurs et les agents lors des tâches mobiles, les chercheurs ont identifié quatre tâches d'interface utilisateur essentielles à étudier : génération de questions d’écran, résumé d’écran, réponse aux questions d’écran et mappage d’instructions à l’action de l’interface utilisateur.Les résultats d'expériences avec les quatre tâches sélectionnées menées pour évaluer l'efficacité de leur approche, démontrent que celle-ci peut atteindre des performances compétitives en utilisant seulement deux exemples de données par tâche, alors que les pipelines d'apprentissage automatique traditionnels nécessitent une collecte de données coûteuse et un entraînement de modèle.
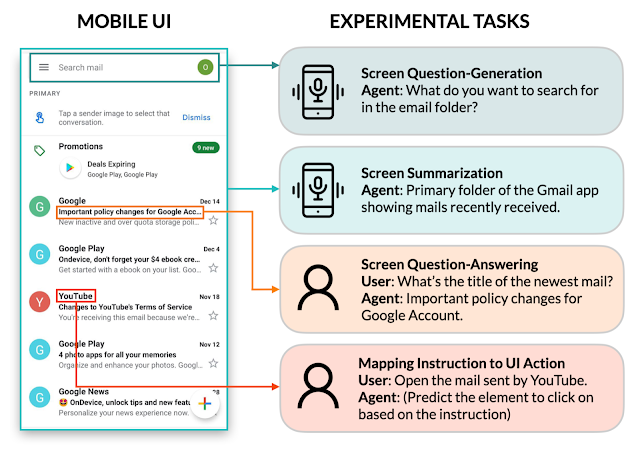
La génération de questions à l’écran
Compte tenu d’un écran d’interface utilisateur mobile, l’objectif de la génération de questions d’écran est de synthétiser des questions cohérentes et grammaticalement correctes en langage naturel pertinentes pour les éléments de l’interface utilisateur nécessitant une entrée utilisateur.Les chercheurs ont constaté que les LLM peuvent tirer parti du contexte de l’interface utilisateur pour générer des questions pour obtenir des informations pertinentes. Les LLM ont nettement surpassé l’approche heuristique (génération basée sur des modèles) en ce qui concerne la qualité des questions.
[caption id="attachment_43890" align="alignnone" width="1999"] Exemples de questions d’écran générées par le LLM. Le LLM peut utiliser des contextes d’écran pour générer des questions grammaticalement correctes pertinentes pour chaque champ de saisie de l’interface utilisateur mobile, tandis que l’approche du modèle est insuffisante.[/caption]
Exemples de questions d’écran générées par le LLM. Le LLM peut utiliser des contextes d’écran pour générer des questions grammaticalement correctes pertinentes pour chaque champ de saisie de l’interface utilisateur mobile, tandis que l’approche du modèle est insuffisante.[/caption]
Les LLM peuvent combiner les champs de saisie pertinents en une seule question pour une communication plus efficace : ainsi, des filtres demandant le prix minimum et maximum ont été combinés en une seule question : "Quelle est la fourchette de prix ?"
Des humains ont évalué si les questions générées par LLM étaient grammaticalement correctes et pertinentes pour les champs d’entrée pour lesquels elles ont été générées : elles avaient une grammaire presque parfaite (4,98/5) et étaient très pertinentes pour les champs de saisie affichés à l’écran (92,8%).
Le LLM a également obtenu de très bons résultats en termes de couverture complète des champs d’entrée (95,8%).
Résumé de l’écran
Le résumé d’écran est la génération automatique de vues d’ensemble descriptives du langage qui couvrent les fonctionnalités essentielles des écrans mobiles. Elle permet aux utilisateurs de comprendre rapidement l’objectif d’une interface utilisateur mobile, ce qui est particulièrement utile lorsque l’interface utilisateur n’est pas accessible visuellement.Les résultats ont montré que les LLM peuvent résumer efficacement les fonctionnalités essentielles d’une interface utilisateur mobile. Ils peuvent générer des résumés plus précis que Screen2Words (modèle de référence publié en 2021, entre autres par les auteurs de cette recherche), précédemment introduit à l’aide de texte spécifique à l’interface utilisateur, comme indiqué dans le texte coloré et les zones ci-dessous.
[caption id="attachment_43891" align="alignnone" width="1999"]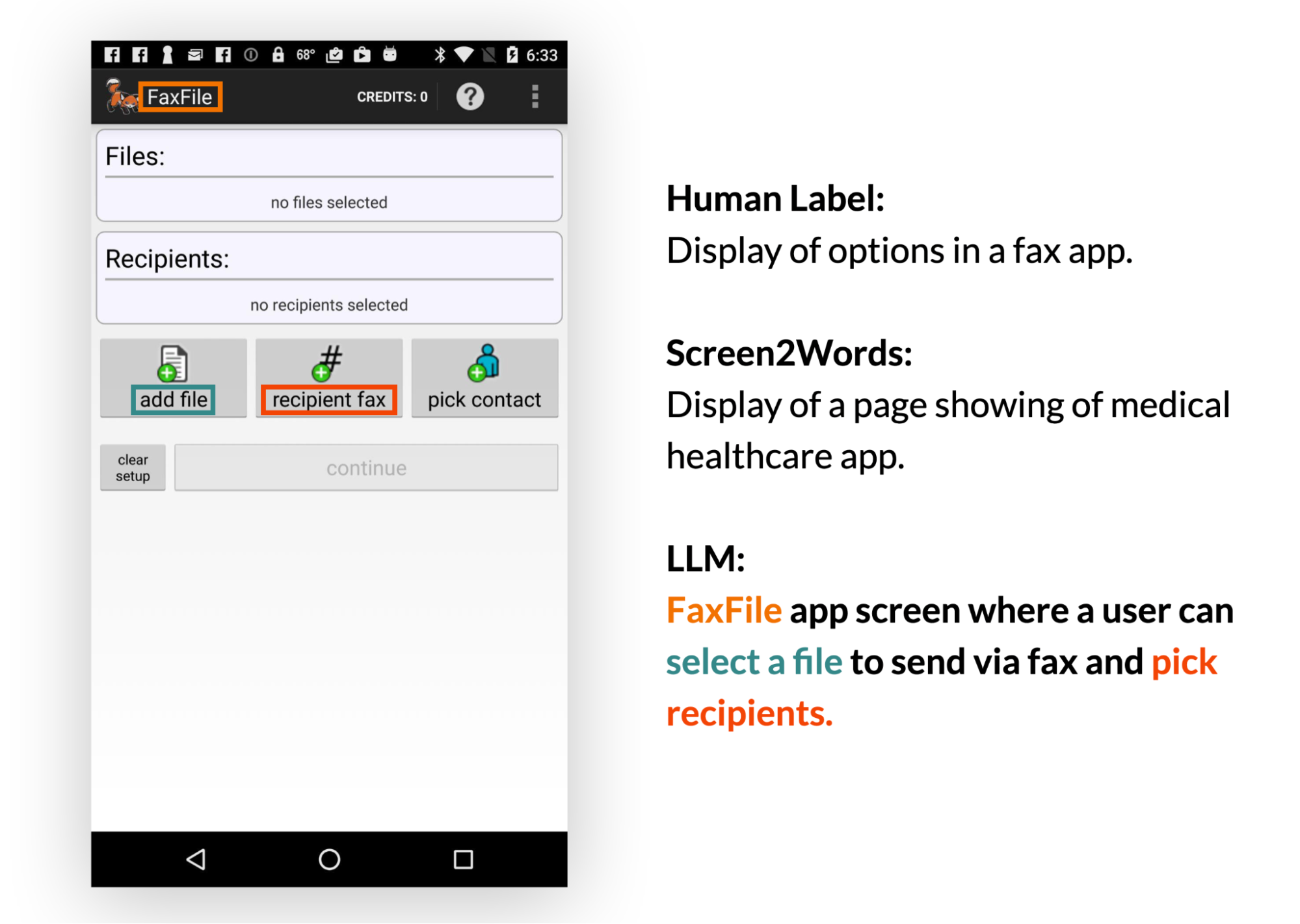 Exemple de résumé généré par LLM 2-shot.Les chercheurs ont constaté que le LLM est capable d’utiliser du texte spécifique à l’écran pour composer des résumés plus précis.[/caption]
Exemple de résumé généré par LLM 2-shot.Les chercheurs ont constaté que le LLM est capable d’utiliser du texte spécifique à l’écran pour composer des résumés plus précis.[/caption]
L'équipe a pu constater constaté les LLM utilisaient leurs connaissances préalables pour déduire des informations qui n’étaient pas présentées dans l’interface utilisateur lors de la création de résumés.
L’évaluation humaine a évalué les résumés LLM comme plus précis que le benchmark, mais ils ont obtenu des scores inférieurs sur des mesures telles que BLEU (bilingual evaluation understudy), un algorithme d’évaluation de la qualité d’un texte traduit automatiquement d’une langue naturelle à une autre. La qualité est considérée comme la correspondance entre la production d’une machine et celle d’un humain
Réponse aux questions à l’écran
Les chercheurs se sont concentrés sur des questions factuelles, nécessitant des réponses basées sur les informations présentées à l’écran.[caption id="attachment_43892" align="alignnone" width="1999"]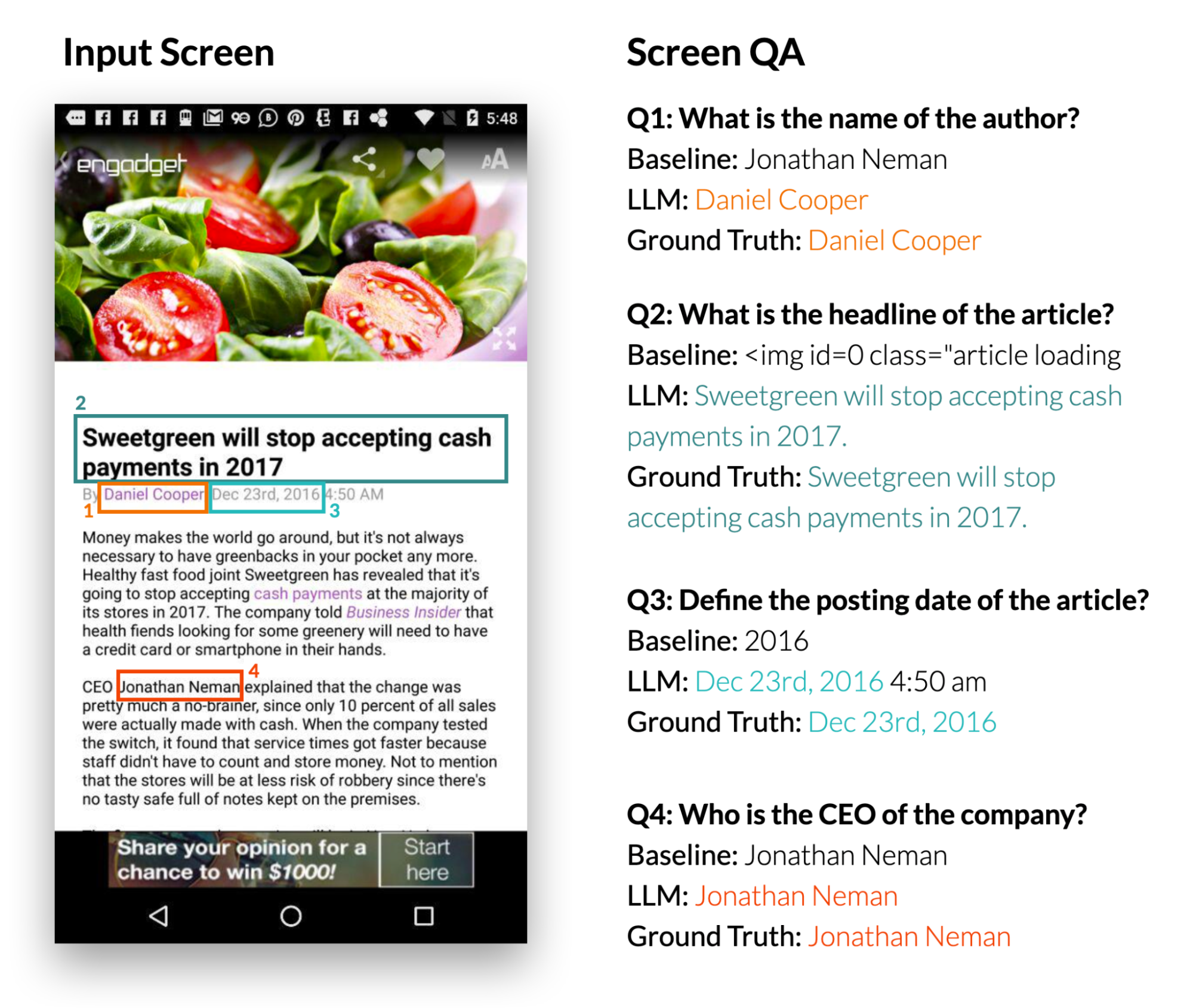 Exemple de résultats de l'expérience question-réponse. Le LLM surpasse significativement le modèle prêt à l'emploi DistillBert atteignant un taux de réponse entièrement correct de 66,7 %. Le LLM 0-shot a notamment atteint un score de correspondance exact de 30,7%, indiquant la capacité intrinsèque du modèle à répondre aux questions.[/caption]
Exemple de résultats de l'expérience question-réponse. Le LLM surpasse significativement le modèle prêt à l'emploi DistillBert atteignant un taux de réponse entièrement correct de 66,7 %. Le LLM 0-shot a notamment atteint un score de correspondance exact de 30,7%, indiquant la capacité intrinsèque du modèle à répondre aux questions.[/caption]
Le mappage de l’instruction à l’action de l’interface utilisateur
Étant donné un écran d’interface utilisateur mobile et des instructions en langage naturel pour contrôler l’interface utilisateur, le modèle doit prédire l’ID de l’objet pour effectuer l’action indiquée.Par exemple, lorsqu’il est invité à utiliser "Ouvrir Gmail", le modèle doit identifier correctement l’icône Gmail sur l’écran d’accueil. Cette tâche est utile pour contrôler les applications mobiles à l’aide de la saisie linguistique telle que l’accès vocal. Yang Li et d'autres chercheurs avaient introduit cette tâche en 2020.
[caption id="attachment_43894" align="alignnone" width="1999"]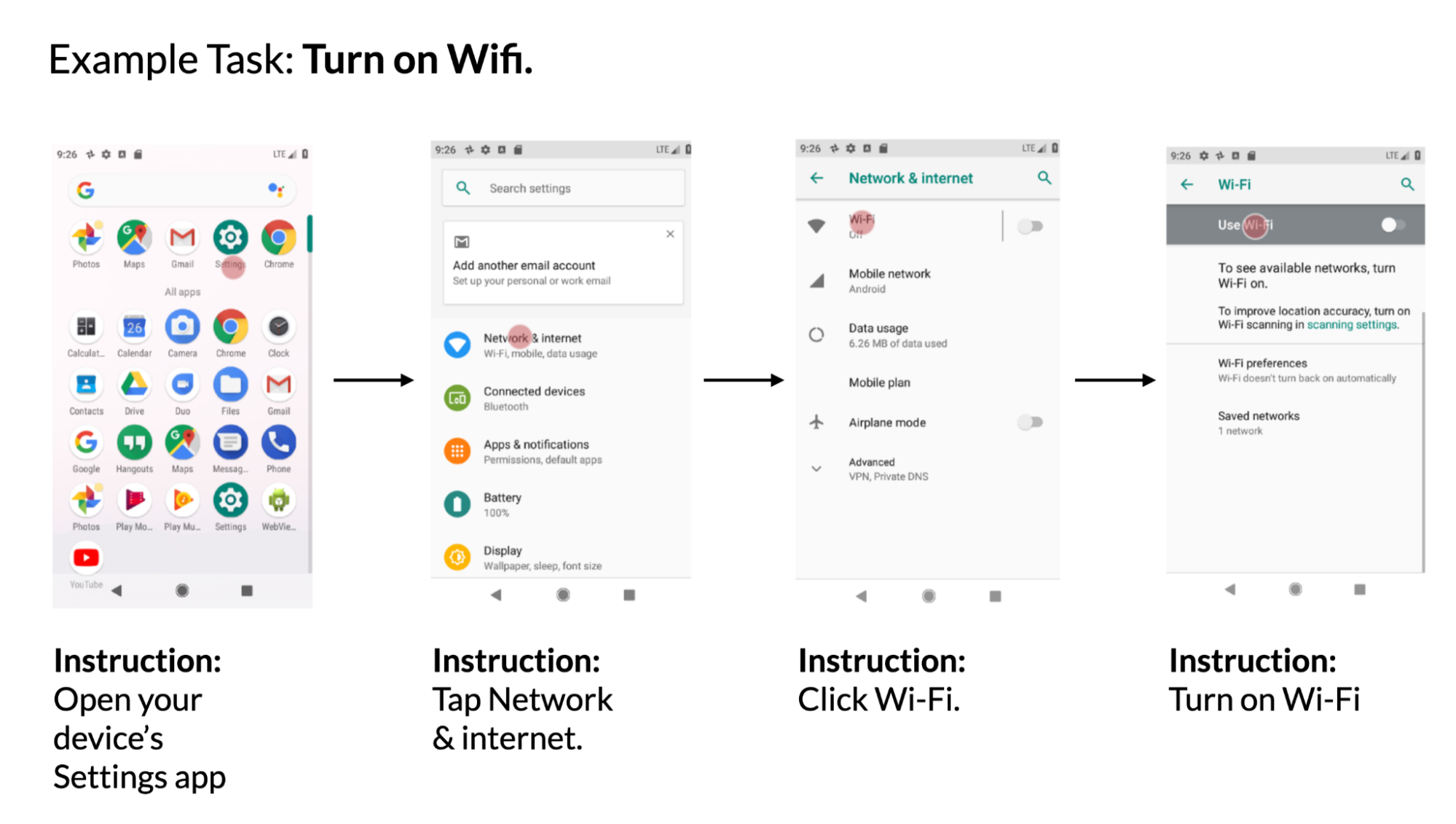 Exemple utilisant les données du jeu de données PixelHelp, Le jeu de données contient des traces d’interaction pour les tâches courantes de l’interface utilisateur telles que l’activation du wifi. Chaque trace contient plusieurs étapes et les instructions correspondantes.[/caption]
Exemple utilisant les données du jeu de données PixelHelp, Le jeu de données contient des traces d’interaction pour les tâches courantes de l’interface utilisateur telles que l’activation du wifi. Chaque trace contient plusieurs étapes et les instructions correspondantes.[/caption]
Bien que cette approche basée sur le LLM n’ait pas dépassé le benchmark formé sur des ensembles de données massifs, elle a tout de même obtenu des performances remarquables avec seulement deux exemples de données incitées.
Selon l'équipe, cette étude dmontre que le prototypage de nouvelles interactions linguistiques sur les interfaces utilisateur mobiles peut être aussi simple que la conception d’un exemple de données. Un concepteur d’interaction peut ainsi rapidement créer des maquettes fonctionnelles pour tester de nouvelles idées avec les utilisateurs finaux. De plus, les développeurs et les chercheurs peuvent explorer différentes possibilités d’une tâche cible avant d’investir des efforts importants dans le développement de nouveaux ensembles de données et modèles.
Références de l'article : Blog Google Research
"Enabling Conversational Interaction with Mobile UI using Large Language Models" CHI 2023 https://doi.org/10.1145/3544548.3580895
Auteurs : Brian Wang de l'Université de Toronto, Yang Li et Gang Li, Google Research