L'Agence Nationale pour la Recherche finance chaque année des projets de recherche dont plusieurs sur l'intelligence artificielle. Focus sur le projet d'AISSPER porté par Mohamed Morchid du Laboratoire d'Informatique d'Avignon : Intelligence artificielle pour la compréhension du langage parlé contrôlée sémantiquement.
Résumé de la soumission
L'intelligence artificielle revêt une importance stratégique au niveau national en raison des résultats impressionnants obtenus par les algorithmes d'apprentissage profond dans différents domaines tels que le traitement du langage, la médecine, l'analytique politique dans un large éventail d'applications.La France devient un leader sur le terrain du deep learning grâce aux récents efforts politiques soulignés ces dernières années. Au cours de la dernière décennie, de gros efforts ont été consacrés aux systèmes de compréhension de la langue parlée (SLU) de bout en bout, motivés par la faisabilité d'applications telles que les assistants personnels et les systèmes conversationnels.
Des résultats supérieurs ont été observés avec ces systèmes en reconnaissance automatique de la parole avec des architectures basées sur l'algèbre de nombres huper-complexes appelés quaternions, nécessitant moins de temps de traitement (Morchid 2018) et de paramètres à estimer comparativement à des modèles classiques (Parcollet et al 2018; 2019). La réduction des paramètres des modèle permet de former efficacement des architectures neuronalles avec des quantités de données limitées, souvent difficiles à obtenir pour des concepts et des contextes sémantiques issus de domaines spécifiques.
Des processus d'apprentissage intrinsèquement liés, tels que l'ASR et le SLU, empêchent la parallélisation des exemples d'apprentissage, ce qui devient critique pour les séquences de grande longueur, car les contraintes de mémoire limitent le traitement par lots à l'aide d'exemples. En outre, l’analyse d’erreurs réalisée sur les résultats de projets achevés tels que M2CR, JOKER, VERA, SUMACC, Media ou DECODA, a montré l’importance de tirer parti des connaissances du domaine antérieur pour l’interprétation sémantique. AISSPER étudiera de nouveaux modèles d’attention qui utilisent la sémantique pour se concentrer sur des informations contextuelles spécifiques afin d’améliorer la classification en concepts.
Contexte de AISSPER
La modélisation efficace des variabilités, illustrée par le langage humain au niveau des phonèmes, des mots et des phrases, reste un problème de recherche très ouverte TAL. Plus encore, extraire des mots-clés, des sujets ou des concepts pertinents à partir d'une phrase ou d'un document oral entier reste une tâche difficile, même pour les systèmes de bout en bout les plus avancés. De plus, pour les signaux de parole, les conditions d'enregistrement et le manque de données spécifiques à un domaine rendent difficile l'extraction d'informations pertinentes dans différents contextes sans l'utilisation de connaissances externes, telles que des ontologies spécifiques à un domaine.Un autre problème crucial pour les solutions disponibles est l’interprétabilité et la robustesse des systèmes. La nécessité de traiter ces problèmes dans les systèmes SLU a récemment été abordée lors de l'atelier IRASL au NIPS 2018. Il est donc proposé de mettre en évidence les contextes pertinents appropriés ainsi que l'incertitude relative pour améliorer l'interprétation et la robustesse.
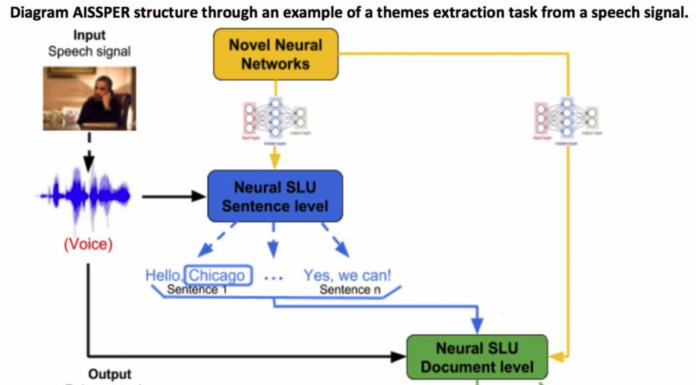
AISSPER vise à développer de nouveaux modèles sémantiques au niveau de la phrase et au niveau de la conversation pour l'extraction d'information pertinente depuis des documents parlés. Plus précisément, AISSPER développera de nouveaux mécanismes d'attention neuronaux pour améliorer les systèmes SLU neuronaux de bout en bout au niveau de la phrase et au niveau du document. Pour ce faire, AISSPER mettra en place une forte collaboration entre des chercheurs établis dans de multiples disciplines: du traitement automatique de la parole et de l'apprentissage automatique du LIUM, du LIA (universitaires) et d'Orkis (industriels). En outre, AISSPER continuera de tirer parti de la collaboration entre LIUM et le MILA axée sur la traduction automatique dans le projet européen / canadien M2CR, ainsi qu'entre le LIA et le MILA pour le développement de réseaux de neurones de quaternions.
Aide de l'ANR 428 393 euros Début et durée du projet scientifique : décembre 2019 - 42 Mois
Le projet sur le site de l'ANR : ici.
Le projet sur le site de ResearchGate : ici.