
Le 5 septembre dernier, Matt Shumer, PDG d'Hyperside (OthersideAI), a dévoilé Reflection 70B sur X, le présentant comme le LLM open source le plus performant au monde. Basé sur le modèle de langage Llama 3.1 70B publié par Meta en juillet dernier, ce nouveau LLM utilise un mécanisme innovant d'autocorrection, le reflection-tuning. Si cette annonce a été accueillie avec enthousiasme par la communauté de l'IA, les performances impressionnantes annoncées ont vite été remises en cause par une partie d'entre elle.
Matt Shumer a expliqué que le modèle est capable de s'autocorriger en temps réel grâce à un processus de raisonnement étape par étape, imitant un type de métacognition, c'est-à-dire la capacité à "penser sa propre pensée". Le reflection-tuning, d'où le nom du modèle désormais présenté comme "Reflection Llama-3.1-70B" sur Hugging Face, permet à celui-ci de repérer et corriger ses propres erreurs logiques avant de produire une réponse finale. Cette approche permet d'obtenir des réponses plus précises et de surmonter un défi majeur rencontré par les LLM : les hallucinations.
Matt Shumer souligne sur X l'importance du rôle de Glaive, une start-up spécialisée dans la génération de données synthétiques personnalisées, qui a permis au modèle de s'entraîner rapidement sur des ensembles de données de haute qualité, augmentant la précision des résultats tout en raccourcissant les cycles de développement.
Les performances annoncées
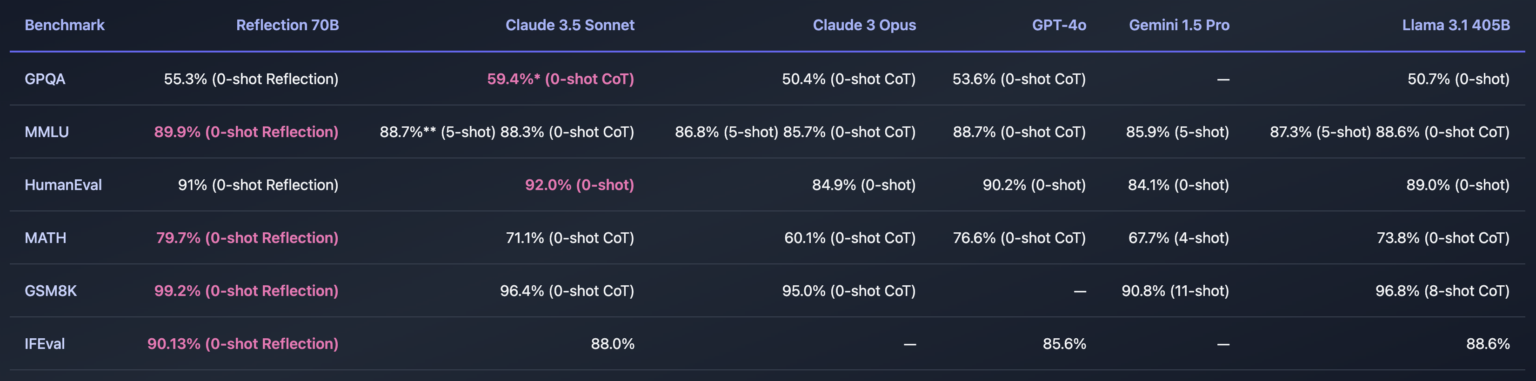
Lors de son annonce, Matt Shumer a vanté les performances de Reflection 70B sur plusieurs benchmarks, affirmant qu'il surpassait d'autres LLMs, y compris certains des modèles propriétaires les plus performants. Parmi ces tests figure le MMLU (Massive Multitask Language Understanding), où le modèle se serait distingué par sa polyvalence, ainsi que HumanEval, qui mesure la capacité des modèles à résoudre des problèmes de programmation.Il a partagé les résultats sur Hugging Face .
Le terrain de jeu Reflection qui permet d’essayer le modèle, indique qu’en raison de la forte demande, la démo est temporairement en panne.
La désillusion
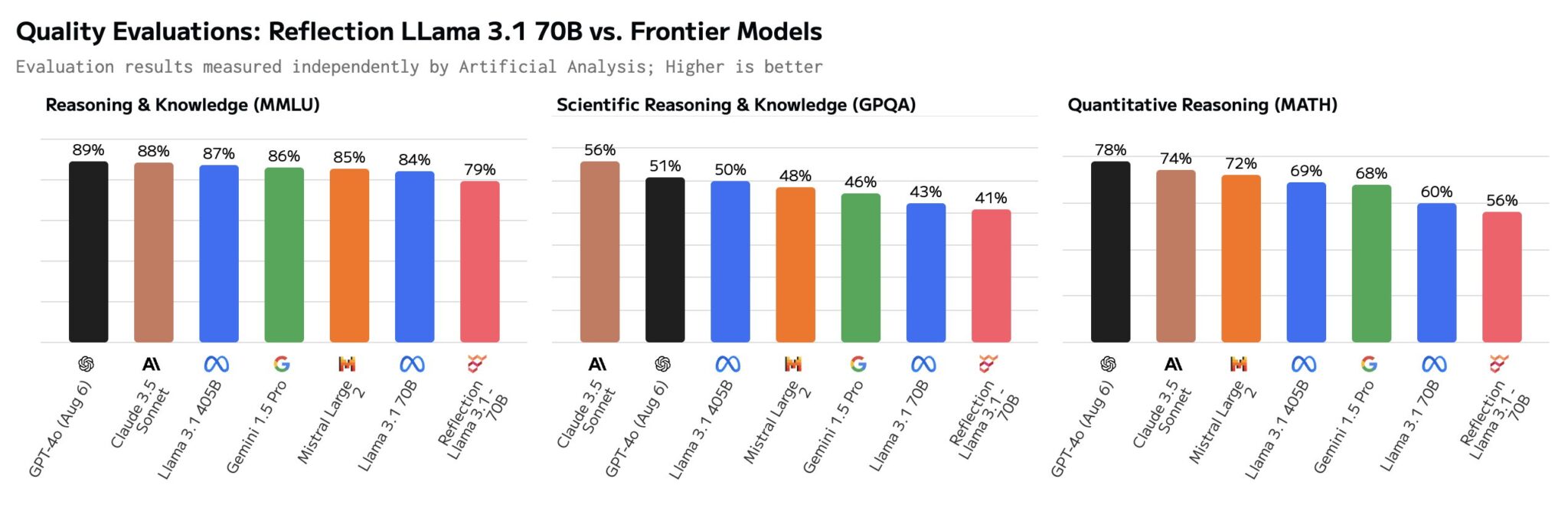
Toutefois, cette révolution annoncée n'a pas tardé à être remise en question. Dès le lendemain du lancement de Reflection 70B, des tests indépendants ont révélé que le modèle n'était pas à la hauteur des attentes. Là où Mat Shumer et son équipe avaient promis une capacité de correction automatique exceptionnelle, le modèle a rapidement montré des faiblesses dans des tâches de base telles que le comptage et le raisonnement logique. Les résultats n'étaient ni constants ni fiables, et Reflection 70B échouait là où d'autres modèles LLM comme GPT-4o et Claude 3,5 Sonnet excellent.Selon l'évaluation d'Artificial Analysis, une organisation dédiée à l’analyse indépendante des modèles d’IA et des fournisseurs d’hébergement, du score MMLU de Reflection Llama 3.170B publiée sur X, le modèle obtient le même score que Llama 3 70B et un score nettement inférieur à celui du Llama 3.1 70B.
Pour certains, Reflection 70B pourrait en fait être Llama 3 avec un réglage LoRA (Low-Rank Adaptation) appliqué, plutôt qu’un affinage de Llama 3.1, pour d'autres le modèle de Shumer n'est pas un modèle original, mais un simple wrapper de Claude 3,5 Sonnet d'Anthropic. En d'autres termes, Reflection 70B ne serait pas le produit d'une avancée technologique inédite, mais plutôt une façade, un reconditionnement d'une technologie déjà disponible.
HyperWrite a répondu aux critiques, admettant que les poids du modèle avaient été corrompus lors du téléchargement sur Hugging Face, ce qui a pu entraîner des performances de qualité inférieure. Pour Matt Shumer, cette corruption des poids est la cause des résultats incohérents observés par des évaluateurs tiers.
Il a publié sur Hugging Face la mise à jour suivante :
"Il y a eu un problème avec le modèle lorsque nous l’avons téléchargé pour la première fois. Si vous l’avez essayé et que vous n’avez pas obtenu de bons résultats, veuillez réessayer, nous pensons avoir résolu le problème".
ajoutant :"De plus, nous savons à l’heure actuelle que le modèle est divisé en une tonne de fichiers. Nous le condenserons bientôt pour rendre le modèle plus facile à télécharger et à utiliser !"
Cependant, malgré cette mise à jour, beaucoup de scepticisme persiste. La communauté s’interroge sur l’ampleur réelle du problème technique initial. La mention explicite de Glaive dans le post Hugging Face, avec la recommandation de "l'utiliser" pour ceux qui souhaitent entraîner un modèle, est perçue par certains comme une tentative de promouvoir la start-up dans laquelle Matt Shumer a investi.L’ensemble de données et un rapport détaillant l'entraînement du modèle devraient être publiés dans les prochains jours et apporter plus d'éclaircissements. Ces accusations doivent être vérifiées par des experts en IA avant de jeter l'opprobre sur Matt Shumer et Hyperside.
Un modèle beaucoup plus grand, Reflection 405B, censé surclasser les modèles open sources actuels, devrait être présenté très prochainement. Mais après les controverses autour de Reflection 70B, la communauté attend désormais plus de transparence et des preuves concrètes avant d'accorder sa confiance.
Pour les acteurs de l'IA, cette affaire est un rappel que l’innovation doit toujours être accompagnée de transparence et d’éthique, et qu'il vaut mieux patienter quelque temps pour obtenir des résultats fiables et vérifiables plutôt que de se précipiter vers des annonces spectaculaires.