
Les systèmes d'IA actuels ont été créés pour se concentrer sur une tâche précise, l'IA généraliste, qui serait capable de raisonner comme l'être humain, d'accomplir diverses tâches sans aucun lien, est actuellement la quête de nombreux scientifiques. DeepMind a publié sur le site d'arXiv un article sur Gato, un agent généraliste, formé sur 604 tâches dont jouer à des jeux Atari, sous-titrer avec précision des images, discuter naturellement avec un humain et empiler des blocs colorés avec un bras de robot.
DeepMind a annoncé en décembre dernier avoir développé un nouveau modèle de langage baptisé GOPHER s’appuyant sur un transformeur, un modèle de deep learning utilisé par les générateurs de texte comme le GPT-3 d’OpenAI. Ses chercheurs ont appliqué une approche similaire à celle de la modélisation du langage à grande échelle, pour construire l'agent multimodal Gato capable d'effectuer 604 tâches avec un unique modèle. Ils se sont également inspirés de travaux récents sur la multi-incarnation.
L'agent généraliste Gato
Utiliser un modèle de séquence neuronale unique pour toutes les tâches permet non seulement de réduire le nombre de biais inductifs appropriés à chaque domaine mais aussi d'augmenter la quantité et la diversité des données d'entraînement, le modèle de séquence pouvant ingérer toutes les données en une séquence plate.L'équipe de DeepMind a démontré que la formation d'un agent généralement capable d'effectuer un grand nombre de tâches est possible et qu'avec un peu de données supplémentaires, il pouvait en réussir de nouvelles. Pour la formation de Gato, l'équipe a utilisé le deep learning supervisé hors ligne afin de simplifier son approche.
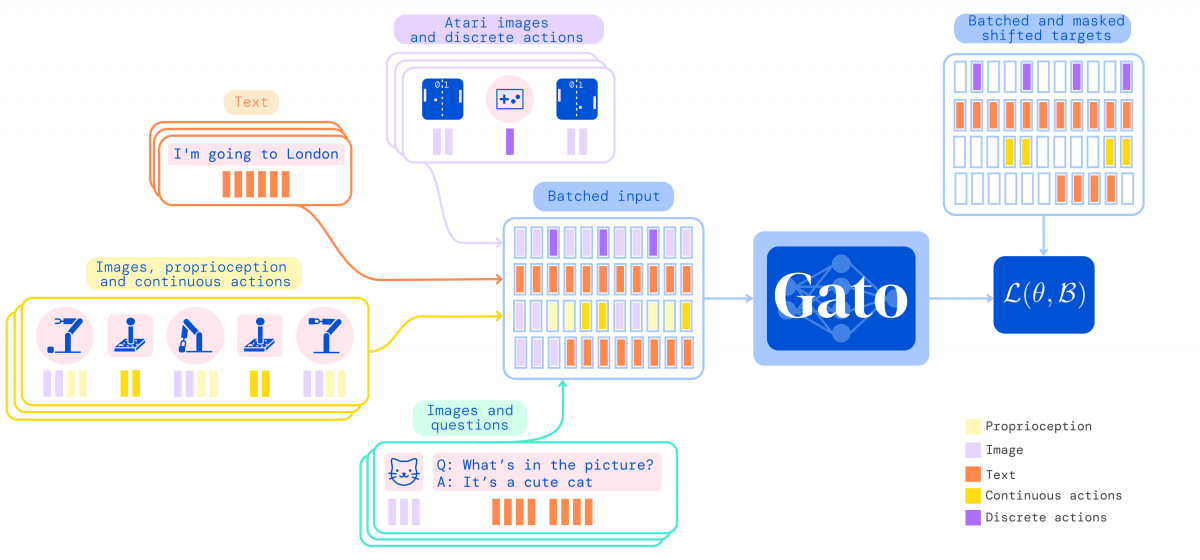
Gato, qui comprend 1,2 milliard de paramètres, a été entraîné sur une grande variété de données telles que les images, le texte, la proprioception, les couples articulaires, les pressions sur les boutons ou encore l'expérience des agents dans des environnements simulés ou réels, qui ont ensuite été sérialisées dans une séquence plate de jetons. Lors du déploiement, les jetons échantillonnés sont assemblés dans des réponses de dialogue, des légendes, des appuis sur des boutons ou d'autres actions en fonction du contexte.
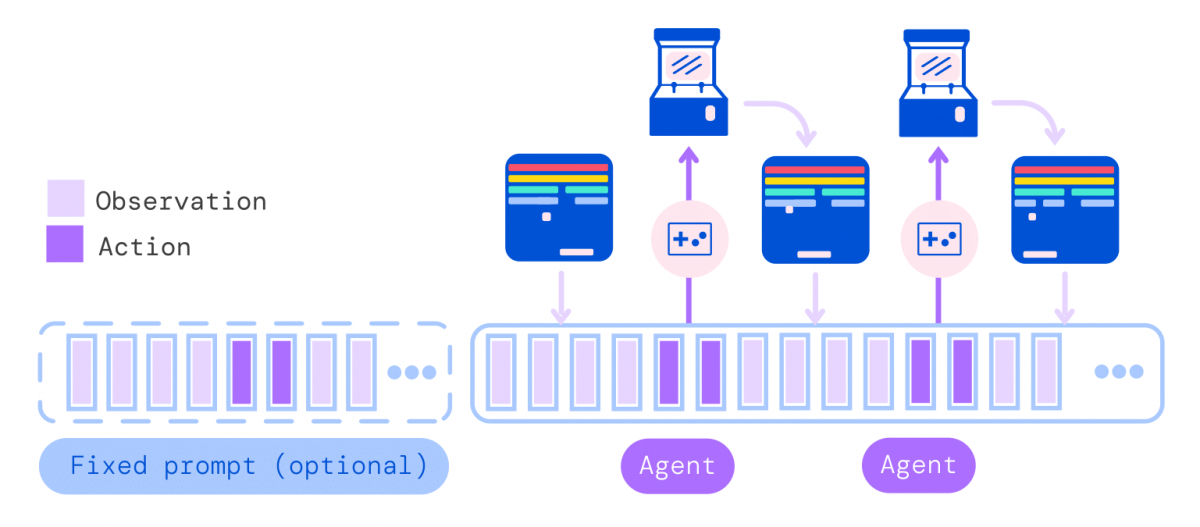
Plus concrètement, lors du déploiement, une invite, comme une démonstration par exemple, est symbolisée et forme la séquence initiale. L'environnement produit alors la première observation, qui est également symbolisée et ajoutée à la séquence. Gato échantillonne le vecteur d'action de manière autorégressive, un jeton à la fois.
Une fois tous les jetons composant le vecteur d'action échantillonnés (déterminés par la spécification d'action de l'environnement), l'action est décodée et envoyée à l'environnement qui, progressant, produit une nouvelle observation, ce processus se répète. Le modèle voit toujours toutes les observations et actions précédentes dans sa fenêtre de contexte de 1 024 jetons.
Si Gato nécessite d'être amélioré grâce à une mise à l'échelle supplémentaire notamment pour les dialogues, il serait selon DeepMind meilleur que les experts humains dans 450 des 604 tâches pour lesquels il a été entraîné.
Sources de l'article : ArVix,
DEEPMIND : Scott Reed, Konrad Żołna, Emilio Parisotto, Sergio Gómez Colmenarejo, Alexander Novikov, Gabriel Barth-Maron, Mai Giménez, Yury Sulsky, Jackie Kay, Jost Tobias Springenberg, Tom Eccles,Jake Bruce, Ali Razavi, Ashley Edwards, Nicolas Heess, Yutian Chen, Raia Hadsell, Oriol Vinyals,Mahyar Bordbar and Nando de Freitas.