
Facebook AI a annoncé en fin de semaine dernière deux découvertes jugées comme majeures en matière d'intelligence artificielle et de vision par ordinateur. Ces modèles sont le fruit d'une collaboration avec Inria et plusieurs institutions académiques. Le premier, baptisé DINO, se base sur la transformation de la vision grâce à l'apprentissage auto supervisé, le second, PAWS, est un modèle d'apprentissage semi-supervisé permettant d'obtenir des résultats détaillés avec moins d'étapes d'apprentissage qu'un modèle plus classique.
DINO, un modèle d'apprentissage auto supervisé performant pour la segmentation
DINO est un modèle d'apprentissage auto supervisé de transformation de la vision. Cet outil peut analyser et segmenter des objets, des animaux ou des végétaux présents au premier plan d'une image ou d'une vidéo grâce à une supervision automatisée. Ci-dessous, on retrouve une illustration explicitant le fonctionnement de ce modèle. Sur la gauche, la photographie d'un chien, au milieu, la segmentation de l'image générée par un modèle supervisé et à droite, un exemple généré par le modèle auto supervisé développé par Facebook AI.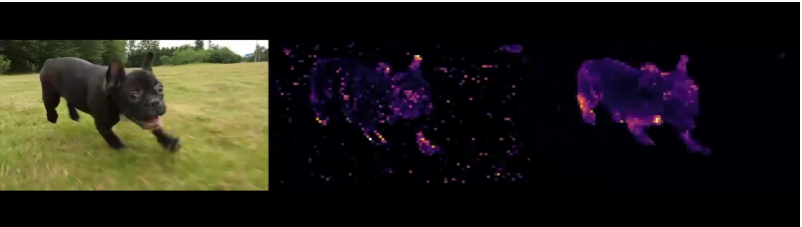
Dans l'exemple qui suit, on peut remarquer que DINO se concentre sur l'animal au premier plan, malgré qu'il puisse exister un arrière-plan qui rend la segmentation plus compliquée :

Cette découverte a fait l'objet d'un article publié par Mathilde Caron, Hugo Touvron, Ishan Misra, Herve Jegou, Julien Mairal, Piotr Bojanowski et Armand Joulin pour Facebook AI Research, Inria et Sorbonne Université. Leurs recherches se concentraient initialement sur l'apprentissage auto supervisé et la vision par ordinateur et ont contribué à la création de ce nouveau modèle.
Segmenter les objets présents dans une image est une opération complexe qui peut être réalisée grâce à la vision par ordinateur. Sa mise en place permet de faciliter certaines tâches comme la permutation de l'arrière-plan d'une image avec un objet présent au premier ou alors permettre aux robots de naviguer sur une image dont l'environnement est encombré. Si habituellement, une segmentation peut être réalisée avec un modèle d'apprentissage supervisé qui nécessite un grand volume de données, la conception de DINO prouve que l'apprentissage auto supervisé et une architecture appropriée peuvent tout à fait convenir.
Une autre découverte concerne le droit d'usage des images. Les modèles basés sur DINO pourraient potentiellement devenir des systèmes de détection de copies ou de violation du droit d'auteur. Même si cet outil n'a pas été conçu pour ça, les chercheurs ont remarqué que cette tâche rentre dans les capacités fournies par le modèle.
PAWS, une méthode pour obtenir des résultats détaillés plus efficacement
L'autre modèle développé par Facebook AI s'intitule PAWS. Il s'agit d'une méthode d'apprentissage semi-supervisé qui exploite une petite quantité d'images étiquetées dans le but d'obtenir des résultats détaillés avec 10 fois moins d'étapes d'apprentissage. Ces résultats ont été obtenus lors du pré entraînement d'un modèle ResNet-50 standard avec la méthode PAWS avec seulement 1 % des étiquettes d'ImageNet. Le schéma ci-dessous montre l'efficacité de PAWS lors de pré entraînements réalisés à l'aide de 1 % des étiquettes d'ImageNet à gauche et de 10 % d'étiquettes à droite :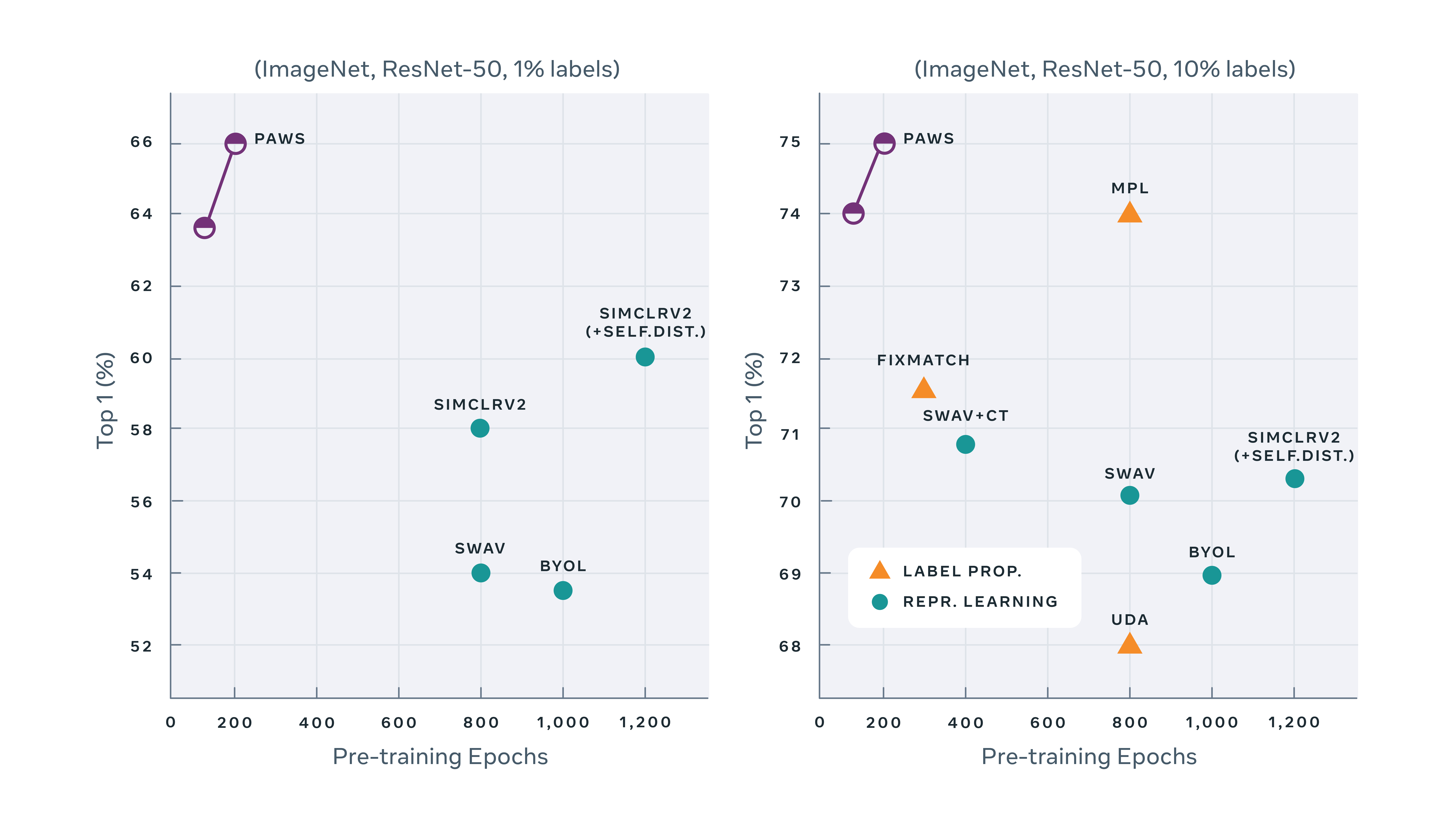
Ce dispositif a lui aussi fait l'objet d'un article écrit par Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Armand Joulin, Nicolas Ballas et Michael Rabbat pour Facebook AI Research, Inria Université Grenoble Alpes, Mila - Québec AI Institute et McGill University.
Contrairement aux méthodes auto supervisées plus classiques qui comparent directement les représentations, PAWS utilise un sous-échantillon aléatoire d'images étiquetées pour attribuer une pseudo étiquette aux vues non étiquetées. Ces pseudo étiquettes sont obtenues en comparant les représentations des vues non étiquetées avec des représentations d'échantillons de support étiquetés. Le modèle est ensuite mis à jour de telle sorte que les pertes soient minimes.
Ci-dessous, un graphique décrit le fonctionnement de PAWS, avec en violet, la vue ancrée, en vert, les sous-échantillons et en orange, la vue positive. De gauche à droite, on retrouve les trois étapes : l'acquisition des images, leur représentation, et les pseudos étiquettes :
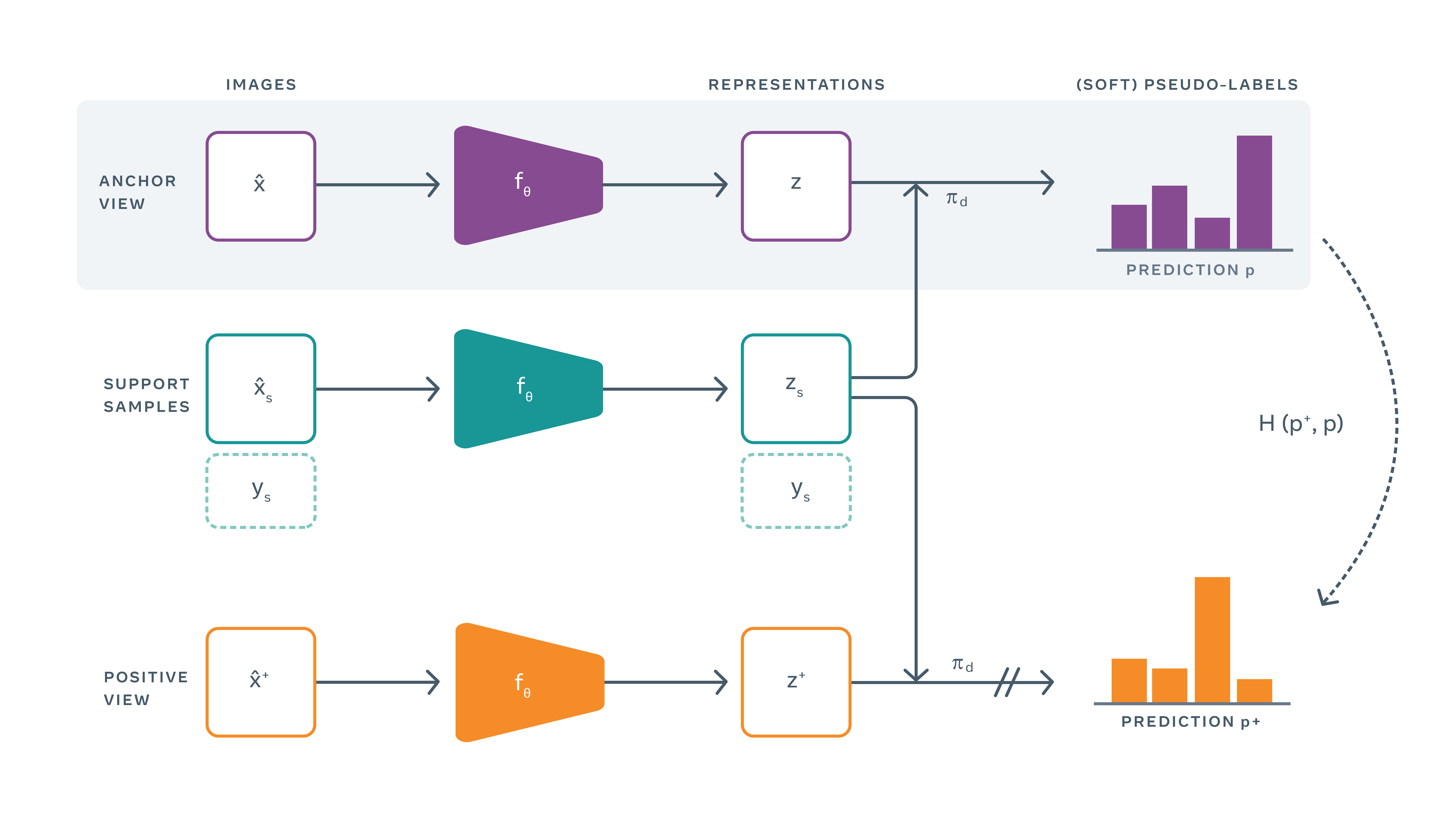
Cette méthode est beaucoup moins sujette au rajustement superficiel des étiquetages contrairement à d'autres modèles d'apprentissage semi-supervisés puisqu'il n'optimise pas directement la précision des prédictions qu'ils souhaitent donner aux échantillons étiquetés.
En combinant DINO et PAWS, la communauté de chercheurs en IA pourra créer de nouveaux systèmes de vision par ordinateur qui dépendront de moins de données étiquetées. L'utilisation d'une grande quantité de données non supervisées offre une excellente opportunité de pré entraîner ces modèles de transformation et de segmentation grâce à une base d'images réduite.