
À l’instar de l’Intelligence humaine qui revêt plusieurs aspects et différentes formes, l’Intelligence Artificielle a expérimenté de nombreuses approches pour la simuler. Ainsi, du perceptron au dernier algorithme de Google (Switch-C) en passant par les systèmes experts et la programmation par contraintes, l’imagination des chercheurs a exploité, au fil du temps, toute la puissance des outils et les combinaisons les plus complexes pour approcher au mieux la perception et le raisonnement des humains. Cependant, schématiquement, toutes ces technologies peuvent se classer en deux grandes catégories : L’Intelligence Artificielle Numérique et l’Intelligence Artificielle Symbolique. ActuIA vous propose de découvrir ce que recouvrent ces deux approches et, parce que le monde est complexe et non binaire, suggère une perspective de rapprochement entre elles pour une IA encore plus efficace, plus compréhensible et plus conforme à son modèle humain.
Dans le cadre des jeux olympiques 2024, nous vous offrons chaque jour un article issu du magazine ActuIA n°4, dont le dossier principal est "Le sport à l'ère de l'IA". Afin de découvrir le magazine ActuIA, nous vous invitons à vous rendre sur notre boutique. Tout nouvel abonnement d'un an vous donne droit à l'ensemble des archives au format numérique.
L’Intelligence Artificielle numérique : Apprendre des données du monde
Article rédigé par Françoise Soulié, conseiller scientifique du Hub France IAL’Intelligence Artificielle numérique, dont les méthodes connexionnistes font partie, ne s’appelait pas du tout IA à l’origine ! Cette appellation était réservée à l’IA symbolique. Comment s’est-elle retrouvée affublée de ce nom d’« IA » ?
L’IA connexionniste a pour source l’idée que l’intelligence de la machine devrait s’inspirer de l’intelligence humaine. C’est d’abord la cybernétique : Wiener trouve l’inspiration des machines dans le système nerveux, il est rejoint au MIT par Pitts, qui travaille avec McCulloch pour réaliser une machine de Turing avec un réseau de neurones. Leur article¹ contient le modèle du neurone artificiel encore utilisé aujourd’hui dans les réseaux de neurones artificiels et autres modèles de deep learning. Puis Rosenblatt propose le perceptron², un réseau de neurones capable d’apprentissage et qui bénéficie d’une énorme publicité. Mais l’ouvrage de Minsky et Papert³ montre bientôt les limitations du perceptron qui ne peut pas résoudre des problèmes (complexes ?) comme la connectivité des spirales imbriquées de la couverture des ré-éditions de 1987 et 2017 du livre. Mais comme, de plus, aucune application industrielle du perceptron n’émerge, les financements se tarissent et le premier hiver des méthodes connexionnistes s’installe.
Premier rebond
À partir du début des années 1980, le travail sur les réseaux connexionnistes repart. Les chercheurs du domaine se retrouvent lors de la conférence NIPS (créée en 1987, devenue NeurIPS en 2018⁴) avec son prequel à Snowbird, des conférences d’INNS et ENNS (International / European Neural Network Societies) et aussi de plusieurs conférences OTAN en France. De nombreuses équipes, partout dans le monde, avancent en parallèle.Aux États-Unis, David Rumelhart (Parallel Distributed Processing group à San Diego) publie l’article fondateur sur la rétro-propagation⁵ que Yann Le Cun avait également développé dans sa thèse en France en 1987⁶. Larry Jackel crée une équipe aux Bell labs avec Le Cun, Bengio, Bottou, Vapnik. Ils exploitent l’algorithme de rétro-propagation du gradient et commencent à travailler sur les réseaux multi-couches convolutionnels (Time
Delay Neural Networks, à l’époque). Ils proposent en 1989⁷ un réseau à trois couches cachées de filtres convolutionnels pour la reconnaissance de caractères. Geoffrey Hinton, à Carnegie Mellon, puis à l’université de Toronto, est sans doute l’un des plus prolifiques contributeurs à l’IA connexionniste : il a travaillé sur les réseaux de neurones, les machines de Boltzmann, les réseaux deep belief, les réseaux convolutionnels... Yoshua Bengio, à l’université de Montréal, se spécialise dans les réseaux convolutionnels, les graph transformer networks⁸ (le modèle de lecture automatique des codes postaux décrit sera déployé à l’U.S. Postal Service et traitera environ 10 % des chèques aux États-Unis au début des années 2000). D’autres équipes en France ont travaillé sur ces sujets. L’équipe de Françoise Soulié-Fogelman et Patrick Gallinari (d’où sont issus Le Cun et Bottou), a travaillé sur des modèles de réseaux convolutionnels (avec 3 à 5 couches de filtres convolutionnels) pour la reconnaissance de la parole (Bottou⁹) ou de visages (Viennet¹⁰) par exemple.
Ces nouvelles techniques sont testées sur les premières applications (lecture de chèques, compréhension de la parole, identification de visages...) et les résultats sont comparables ou supérieurs aux meilleures techniques conventionnelles de l’époque : les limites du perceptron sont complètement dépassées grâce à l’introduction des couches cachées des réseaux multi-couches. Mais des limites apparaissent rapidement : les ensembles de données sont de tailles très limitées et difficiles à assembler, par ailleurs les temps de calcul sur les machines existantes explosent ; l’industrialisation ne démarre pas. Et, à partir de 1995, sans soutien de l’industrie, c’est le deuxième hiver des méthodes connexionnistes.
2012, le tournant
Dans les quinze années qui suivent, l’IA Numérique va se développer fortement, avec des applications nombreuses dans l’industrie (banque, télécommunications, distribution notamment) et une ouverture de la statistique classique à ces méthodes.Progressivement, cette branche de l’IA est alors considérée comme équivalente au terme Machine Learning. Les manuels de Vapnik¹¹ , Friedman, Hastie, Tibshirani¹² posent les bases théoriques du Machine Learning et dans un article¹³ retentissant de 2001, Leo Breiman, l’inventeur des arbres de décision, des forêts aléatoires et des techniques de bagging, incite les statisticiens à s’intéresser au Machine Learning. D’autres techniques sont développées : logique floue, algorithmes génétiques... Au Canada, le Cifar (Canadian Institute For Advanced Research) finance un programme « Calcul neuronal et perception adaptative » qui permet au trio Le Cun (NYU), Hinton (Toronto) et Bengio (Montréal) de maintenir l’activité sur les réseaux de neurones. Cependant, durant ces quinze ans, trois événements vont complètement changer la donne : d’abord, le web et les mobiles suscitent la révolution du big data, les volumes des données et leur variété explosent ; ensuite, les performances des moyens de calcul – dont les GPU, et les moyens de stockage, croissent exponentiellement ; enfin, en 2012, se produit l’événement qui va lancer la « révolution de l’IA ».
Chaque année a lieu la compétition de référence en vision artificielle, Image-Net Large Scale Visual Recognition Challenge (ILSVRC). Jusqu’en 2011 les meilleures performances obtenues ont un taux d’erreur de classification top-5 de 25 %. D’une année sur l’autre les taux d’erreur baissent d’1 ou 2 %. Mais le 30 septembre 2012, le réseau de convolution AlexNet¹⁴ gagne la compétition avec un taux d’erreur de 15,3 %, un gain de 10,8 % par rapport au second. Et pourtant aucun des auteurs (Hinton avec ses étudiants) n’est un spécialiste de vision artificielle ! AlexNet est un modèle très lourd, dont toutes les techniques utilisées sont pourtant bien connues à l’époque, mais combinées avec une maîtrise technologique remarquable. Les années suivantes, tous les candidats à ILSVRC utiliseront des réseaux convolutionnels et les taux d’erreur continueront de descendre jusqu’à atteindre quelques % (mieux que l’être humain). Fin 2012, Hinton publie avec Microsoft Research, Google et IBM Research un article de synthèse¹⁵ établissant la supériorité pour la reconnaissance de la parole des réseaux convolutionnels profonds i.e. avec beaucoup de couches, et apprentissage ou deep learning.
Il y a donc bien un avant et un après-2012 : le monde entier se lance alors dans la « révolution de l’IA » et c’est le printemps de l’IA connexionniste. Le trio Hinton, Le Cun et Bengio publie un article¹⁶ dans Nature où ils décrivent en 9 petites pages (dont 2 de références) les techniques qui ont battu les meilleurs spécialistes mondiaux en vision et en parole. En 2019, le trio reçoit le prix Turing, le Nobel de l’informatique, doté de 1M$. Leur ouvrage¹⁷ devient la bible du domaine.
Près de dix ans après, les techniques de l’IA numérique (dont l’IA connexionniste) ont de multiples applications industrielles et font même parfois mieux que les humains. Aujourd’hui le terme IA se réfère généralement à ces techniques. On trouve des algorithmes d’IA dans tous les systèmes de perception (reconnaissance d’objets pour le véhicule autonome, de visages pour le comptage des foules ou l’identification de personnes en Chine, d’images médicales ou satellite ; reconnaissance de la parole avec les chatbots ou les assistants personnels - Apple Siri, Amazon Alexa, OK Google ; l’analyse de textes – NLP avec les algorithmes de transformers - BERT et successeurs) ; dans de nombreuses applications marketing ou service client (campagnes ; recommandations de produits, octroi de crédit, détection de fraudes...) ; les jeux où les techniques d’IA ont battu les champions humains (pour le jeu de go par exemple, où DeepMind¹⁸ utilise deep learning et reinforcement learning, avec l’IA qui joue contre elle-même) ; pour des applications en droit (analyse de contrats juridiques, prévision de récidive par exemple) ; l’industrie (maintenance prédictive, fonctions d’assistance au conducteur pour les automobiles) ; la génération automatique d’images ou vidéos pour les media (deep fakes), voire la création d’œuvres d’art ou de théories scientifiques, etc.
Les futurs enjeux ne sont pas (que) techniques
L’essor des applications industrielles de l’IA semble donc sans limite. Pourtant de nombreuses questions restent posées, dont celles-ci, pour ne citer que les principales : si l’IA est meilleure que l’humain dans certaines tâches, elle n’a aucune compréhension de la tâche et est incapable de passer d’une tâche à une autre, pourtant très voisine (on dit que l’IA est « étroite ») et encore moins de résoudre n’importe quelle tâche (l’IA dite « générale »), ce que les humains font couramment. De plus, l’IA apprend à partir des données qui lui sont fournies : si ces données sont « biaisées », l’IA en résultant le sera également (une application¹⁹ de reconnaissance du sexe à partir de photos contenant beaucoup d’hommes blancs fait 1 % d’erreurs sur les hommes blancs et 35 % sur les femmes à peau sombre).L’éthique de l’IA est donc un problème très significatif. Ou encore, l’IA ne peut pas toujours « expliquer » ses résultats, ce qui peut nuire à la confiance de l’utilisateur ou poser problème si on veut auditer l’application. Puis, les fakes, créés par des GAN (Generative Adversarial Networks : deux réseaux profonds entraînés l’un contre l’autre) peuvent causer de réels problèmes quant à la véracité des sources, un sujet épineux pour les media ou la sécurité (robustesse et cybersécurité). Enfin, Minsky et Papert avaient déjà discuté de la difficulté à comprendre pourquoi l’IA fonctionne : les grands systèmes récents avec des milliards de paramètres (175 pour le récent modèle de langage GPT-3) deviennent quasiment impossibles à analyser. Il faut donc davantage de résultats théoriques et sans doute encore beaucoup de travail pour apporter la réponse à la simple question posée par Léon Bottou dans le prologue à la réédition de 1988 de Perceptrons : “Are there inherent incompatibilities between those connectionist and symbolic views ?”
1. Warren McCulloch and Walter Pitts. A Logical Calculus of Ideas Immanent in Nervous Activity. Bulletin of Mathematical Biophysics vol.5, pp. 115–133. 1943.
2. Frank Rosenblatt. Principles of neurodynamics. perceptrons and the theory of brain mechanisms. Cornell Aeronautical Lab Inc Buffalo NY, 1961.
3. Marvin Minsky, Seymour Papert. Perceptrons. Cambridge, MA : MIT Press. 1969.
4. https://proceedings.neurips.cc//
5. David E. Rumelhart, Geoffrey E. Hinton, Ronald J. Williams. Learning representations by back-propagating errors. Nature 323.6088 : pp. 533-536. 1986.
6. Yann Le Cun : Modèles connexionnistes de l'apprentissage. Thèse. Juin 1987.
7. Yann LeCun, Bernhard Boser, John S. Denker, Donnie Henderson, Richard E. Howard, Wayne Hubbard, Lawrence D. Jackel. Backpropagation applied to handwritten zip code recognition.Neural Computation 1, no. 4 : pp. 541-551. 1989.
8. Yann LeCun, Léon Bottou, Yoshua Bengio, Patrick Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE 86, no. 11 : pp. 2278-2324. 1998.
9. Léon Bottou, Françoise Fogelman-Soulié, Pascal Blanchet, Jean-Sylvain Lienard. Experiments with time delay networks and dynamic time warping for speaker independent isolated digits recognition, Proceedings of Eurospeech-1989, Paris, France, pp. 2537-2540. 1989.
10. Emmanuel Viennet, Françoise Fogelman-Soulié. Connectionist methods for human face processing, In “Face Recognition : from theory to applications”, H. Weschler, J. Phillips , F. Fogelman-Soulié and T.S. Huang, eds. NATO ASI Series F, Computer and Systems Sciences, Vol. 163, Springer-Verlag, 124-156. 1998
11. Vladimir Vapnik. The nature of statistical learning theory. Springer science & ; business media, 2013.
12. Jerome Friedman, Trevor Hastie, Robert Tibshirani. The elements of statistical learning. Vol. 1, no. 10. New York : Springer series in statistics, 2001. https://web.stanford.edu/~hastie/Papers/ESLII.pdf
13. Leo Breiman. Statistical modeling : The two cultures (with comments and a rejoinder by the author). Statistical science 16, no. 3 : pp. 199-231. 2001.
14. Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems 25 : pp. 1097-1105. 2012.
15. Geoffrey Hinton, Li Deng, Dong Yu, George E. Dahl, Abdel-rahman Mohamed, Navdeep Jaitly, Andrew Senior et al. Deep neural networks for acoustic modeling in speech recognition : The shared views of four research groups. IEEE Signal processing magazine 29, no.6 : pp. 82-97. 2012.
16. Yann LeCun, Yoshua Bengio, Geoffrey E. Hinton. Deep Learning. Nature, Vol. 521, pp 436-444. 2015.
17. Ian Goodfellow, Yoshua Bengio, Aaron Courville. Deep Learning. MIT Press. 2016.
18. Silver, David, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert et al. " ;Mastering the game of go without human knowledge." ; nature 550, no. 7676 : pp. 354-359. 2017.
19. Joy Buolamwini, Gebru Timnit. Gender shades : Intersectional accuracy disparities in commercial gender classification. Conference on Fairness, Accountability, and Transparency. Proceedings of Machine Learning Research 81 : 1-15, pp. 77-91, 2018
L’Intelligence Artificielle symbolique : Utiliser l’abstraction du raisonnement
Article rédigé par Juliette Mattioli, docteur en mathématiques appliquées, Senior Expert Thales, Laurent Cervoni, docteur en sciences appliquées, directeur recherche Talan, Francis Rousseaux, docteur en informatique, recteur adjoint de l’université GalatasarayToutes les « branches » de l’intelligence artificielle (IA) ont pour même ambition de modéliser le raisonnement humain. Dans le domaine de l’intelligence artificielle symbolique, ce sont la capacité d’abstraction de l’être humain et l’utilisation de concepts, les relations entre des objets et les corrélations entre des situations qui sont privilégiées.
Plus discrète que l’intelligence artificielle connexionniste incarnée par l’apprentissage automatique avec l’apprentissage profond, l’IA symbolique aujourd’hui souvent appelée “GOFAI” pour Good Old Fashion AI reste active et adaptée à toute une catégorie de problèmes. En outre, elle peut venir compléter ou s’appuyer sur l’IA Numérique comme l’explique l’article Réconcilier les intelligences dans ce numéro. Nicholas Asher, chercheur CNRS à l’Institut de recherche en informatique de Toulouse (IRIT) et directeur scientifique du projet ANITI, définit cette branche comme une discipline qui « utilise le raisonnement formel et la logique ; c’est une approche cartésienne de l’intelligence, où les connaissances sont encodées à partir d’axiomes desquels on déduit des conséquences. La prédiction doit être juste même si l’on ne dispose pas de données exhaustives». Ce paradigme exploite la manipulation de connaissances sous formes de symboles et de propositions logiques couplée à un mécanisme d’inférence imitant le raisonnement humain dans la résolution de problèmes complexes, comme notamment les problèmes d’optimisation combinatoire, de planification, de décision multicritères. Sa force réside donc dans sa représentation des connaissances et dans son raisonnement par la logique donnant lieu dès le début des années 1970 aux systèmes experts¹ ou aux systèmes à base de connaissances. L’industrie financière utilise aussi la technologie CEP (Complex Event Processing) à base de règles spatio-temporelles dans les systèmes de trading.
Représenter les connaissances
Reposant sur l’idée que « l’intelligence est surtout liée à la connaissance plus qu’à un problème de raisonnement », Edward Feigenbaum, père du premier système expert DENDRAL définit en 1977 l’ingénierie des connaissances (IC) (Knowledge Engineering) comme « l’art d’acquérir, de modéliser et de représenter la connaissance en vue de son utilisation par un ordinateur ». Pour cela, on peut s’appuyer sur :- Des représentations logiques construites selon une syntaxe précise. Ainsi, une base de connaissances est un ensemble de formules décrivant le domaine sur lequel s’appliquent des règles de raisonnement, comme dans le langage PROLOG².
- Des réseaux sémantiques, des graphes conceptuels³ bénéficiant de mécanismes de raisonnement induits par les opérations de graphes comme l’homomorphisme de graphes.
- Des ontologies qui constituent en soi un modèle de données représentatif d’un ensemble de concepts dans un domaine, ainsi que des relations entre ces concepts.
- les moteurs dits à « chaînage avant » qui partent des faits et règles de la base de connaissances et tentent de s’approcher des faits recherchés par le problème. Les règles sont utilisées dans le sens conditions vers conclusion ;
- les moteurs dits à « chaînage arrière » qui partent des faits recherchés par le problème et tentent par l’intermédiaire des règles, de remonter à des faits connus. Les règles sont utilisées dans le sens conclusion vers conditions ;
- les moteurs dits à « chaînage mixte » qui utilisent une combinaison de ces deux approches chaînage avant et chaînage arrière.
- détection de similarités ;
- recherche d’analogies ;
- extraction d’explications.
La modélisation du problème peut inclure la connaissance métier et se fait par le biais d’un ensemble de relations logiques : les contraintes. Des mécanismes de propagation des contraintes dans un arbre de branchement permettent la réduction du domaine de décisions. Le solveur de contraintes calcule alors une solution en instanciant chacune des variables à une valeur satisfaisant simultanément toutes les contraintes. Aujourd’hui, de nombreuses applications de la PPC sont déployées, comme dans la grande distribution qui optimise depuis longtemps sa logistique et sa gestion des stocks. Parmi les outils actuellement disponibles en programmation par contraintes, citons OPL et CPLEX d’IBM (issu du rachat d’ILOG), au sein de Python la librairie Python-Constraint (qui offre la gestion de contraintes basiques sur les domaines finis), SWI-PRolog (Prolog Open Source enrichi d’un module de gestion de contraintes) ou encore OR-Tools de Google.
Terrains de jeux de l'IA symbolique
Outre les cas déjà évoqués, l’IA symbolique est souvent utilisée pour concevoir des systèmes d’aide à la décision. En effet, un problème de décision consiste en un choix, ou un classement, entre plusieurs hypothèses mutuellement exclusives résultant d’un processus tenant compte des connaissances que l’on a sur l’état du monde, des préférences et/ou de l’objectif à atteindre. Ces connaissances peuvent être empreintes d’incertitude et les préférences sont par nature nuancées. Un outil simple pouvant être mis en œuvre est alors l’arbre de décision, qui représente un ensemble de choix sous la forme graphique d’un arbre. Les différentes alternatives sont alors les feuilles de l’arbre et sont atteintes en fonction de décisions prises à chaque étape. Cependant, la définition et l’utilisation d’un ou plusieurs critères de sélection sont nécessaires. Contrairement à la situation monocritère qui peut être résolue assez facilement, la décision multicritères nécessite des méthodes plus élaborées. Parmi les techniques utilisées, citons la méthode du What-if ou l’agrégation multicritères. Cette dernière consiste à évaluer globalement les différents candidats ou solutions proposées, à partir de la fusion des appréciations partielles. Reposant sur ce type d’approche, la startup américaine Psibernetix est devenue célèbre en 2016 pour avoir développé une IA à base d’arbres de décision, de logique floue et d’algorithmes génétiques (Genetic Fuzzy Tree) qui a régulièrement battu, lors de simulations de combats aériens, les pilotes les plus chevronnés.
Perspectives
Aptes à fournir des explications intelligibles, à développer des connaissances et à apprendre (machine learning symbolique), les systèmes conçus via l’IA symbolique s’insèrent très bien dans l’épistémologie scientifique traditionnelle car les théories sous-jacentes sont réfutables et interprétables. En revanche, ils pâtissent du fait que les représentations humaines se laissent rarement formaliser sans réductions et sans biais, et qu’elles tendent à évoluer rapidement. La théorie des systèmes d’IA symbolique semblait si naturelle aux scientifiques qu’ils n’ont pas vraiment eu à l’expliciter pour la déployer. C’est pourquoi les mises en garde et les critiques n’ont pas été entendues, et c’est aussi pourquoi les explications sont toujours venues bien après les réalisations de systèmes. Ainsi, pour David Sadek, VP Recherche Technologies et Innovation chez Thales « l’IA connexioniste est l’IA des sens, et l’IA symbolique est celle du sens ». C’est pourquoi, pour couvrir l’ensemble des capacités cognitives, l’avenir est dans l’hybridation de ces deux paradigmes de l’IA souvent mis en opposition. En effet, la principale difficulté de l’approche symbolique est la modélisation des connaissances, là où l’apprentissage peut servir à identifier des modèles présents dans les données. De plus, l’IA symbolique offre des capacités de raisonnement nécessaire pour expliquer, de façon intelligible pour l’usager, les raisons des décisions induites par l’algorithme même si celui-ci manipule des notions ou concepts qui échappent à la compréhension humaine. Ainsi, si l’IA Symbolique est aujourd’hui moins en vue que l’IA Numérique, elle a permis de résoudre des problèmes industriels importants (gestion de haut fourneaux avec SACHEM, dépannage automobile, etc.) et a montré sa capacité à offrir des solutions satisfaisantes quand peu de données sont disponibles ou qu’un raisonnement est modélisable (suivi médical, octroi de crédit, aide à la gestion de carrière). Dans tous les cas, elle est potentiellement complémentaire d’autres approches.1. Citons les deux premiers systèmes experts : DENDRAL, spécialisé dans la chimie moléculaire créé en 1965 et MYCIN, spécialisé dans le diagnostic de maladies infectieuses du sang (méningites) et la proposition de thérapies associées développé en 1972.
2. Alain Colmerauer et Philippe Roussel développent à Marseille en 1972 le langage PROLOG (Programmation Logique), au départ pour traiter le langage. Un programme PROLOG est une suite de clauses de Horn sur lesquelles opère un mécanisme de raisonnement utilisant le principe de résolution. Comme LISP, Prolog utilise massivement la structure de liste et il est naturellement récursif.
3. Les graphes conceptuels sont introduits par John F. Sowa (chercheur à IBM) en 1984 pour formaliser la différence entre les concepts individuels (instances), les concepts génériques, et les classes (types).
Réconcilier les intelligences (artificielles)
Article rédigé par Laurent Cervoni, docteur en sciences appliquées, directeur recherche Talan, Éric de La Clergerie, docteur en informatique, chercheur à l’INRIA, Francis Rousseaux, docteur en informatique, recteur adjoint de l’université GalatasaraySouvent les deux approches de l’intelligence artificielle, numérique (dont l’approche connexionniste)et symbolique, présentées dans les précédentes pages, sont opposées l’une à l’autre voire même parfois annoncées comme irréconciliables. L’opposition entre les deux démarches est liée à différentes visions ou explications du cerveau humain que l’IA essaie de modéliser... Pourtant, depuis de longues années, des chercheurs tentent de déterminer une voie pour associer les deux approches.
La vision symbolique traditionnelle présentée dans l’article qui lui est dédié coïncide avec une vision classique conceptuelle du monde et le traitement discret rendu possible par l’informatique. Concepts et relations entre concepts permettent une excellente compression de l’information essentiellement sous la forme très générale de graphes, ceux-ci (en extension ou en intension) pouvant traduire des structures plus ou moins compliquées sur lesquelles mener des raisonnements.
Néanmoins, ces concepts platoniciens reflètent rarement la réalité. Même un concept simple comme « chaise » traduit une grande diversité de formes, textures et même fonctions qui ne gênent cependant pas un humain pour reconnaître une chaise quand il en voit une ! L’ap- proche connexionniste, en particulier sur les aspects images, se révèle bien mieux adaptée pour capturer la nature floue et probabiliste du monde qui nous entoure et que nous conceptualisons.
Ainsi, tout naturellement, l’approche numérique (dont le connexionnisme en est le représentant le plus marquant) est apparue plus adaptée à des problèmes « continus » tels que le traitement du signal, des sons, de la parole, des images (dont l’écriture manuscrite) quand le symbolique s’attaquait au raisonnement et aux mondes discrets.
Cependant, l’intelligence humaine est vraisemblablement une combinaison de ces deux univers, avec plutôt du connexionnisme pour les phases de perception et plutôt du symbolique pour les phases de raisonnement. Aussi, dès les années 1990, de nombreux travaux ont cherché à démontrer l’intérêt de l’articulation entre la démarche connexionniste et la symbolique.
Si ces deux visions du cerveau et de ses mécanismes d’apprentissage expliquent succinctement les différences d’approche entre les deux intelligences artificielles, il n’en reste pas moins que des chercheurs ont pensé qu’il était efficace de tirer parti d’une modélisation symbolique enrichie par une approche neuronale et réciproquement.
Sens de la quête
Vouloir rapprocher les deux visions de l’intelligence artificielle n’est donc pas une lubie de chercheurs mais tente d’apporter de nouvelles solutions aux problèmes que pose la modélisation du raisonnement humain.Une telle démarche d’hybridation trouve d’ailleurs tout son sens lors du démarrage d’un projet où certains concepts doivent être expérimentés et surtout dans tous les domaines où peu de données sont disponibles. Il faut noter qu’il existe des situations en entreprise où des projets concrets sont repoussés ou abandonnés faute de données alors même qu’il existe une expertise humaine. Initier un projet sur la base de cette expertise, appuyé par des outils symboliques, est alors une approche très efficace. Par exemple, FRMG, conçu par l’INRIA, initialement sur une base Prolog, a débuté par un modèle purement symbolique autour d’un « cœur » en Prolog (cf. article sur l’IA symbolique). Cependant, confronté à la richesse de la langue et à la nécessité de résoudre les ambiguïtés de certaines tournures, une partie heuristique est venue compléter l’approche symbolique afin de lever ces ambiguïtés.
Ces heuristiques, initialement exprimées sous forme logique en tant que contraintes pondérées manuellement, ont vu les poids ensuite appris automatiquement à partir de corpus annotés syntaxiquement via une forme de perceptron une fois de tels corpus disponibles.
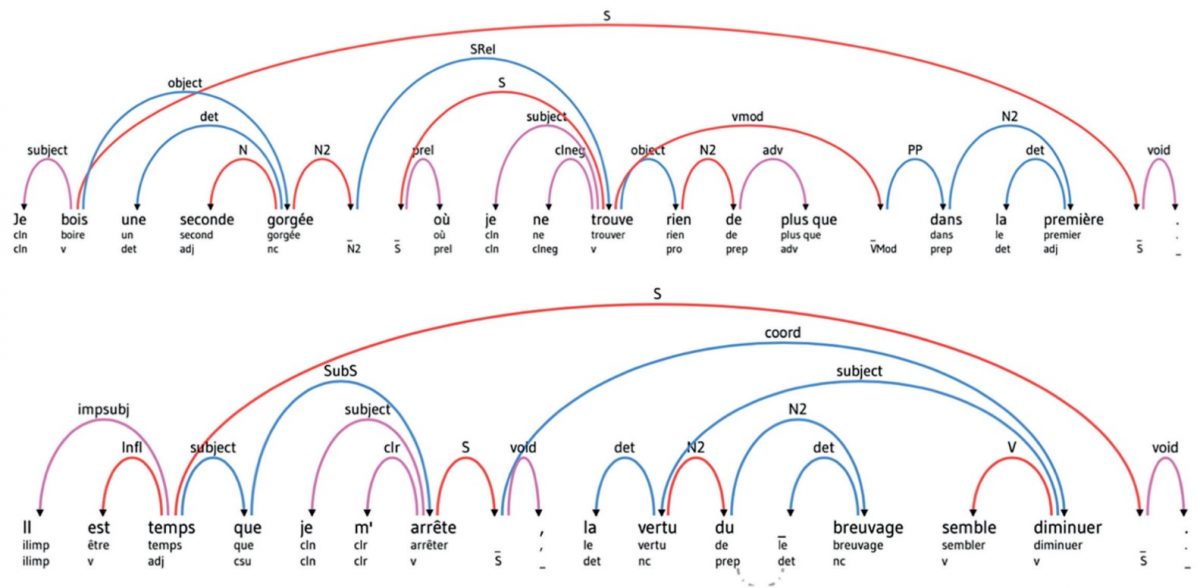
Exemples d’analyses avec FRMG (Extraits de M. Proust, À la recherche du temps perdu)
Le schéma derrière FRMG est finalement typique d’un démarrage rapide sous forme symbolique par manque de données alors qu’il existe une expertise humaine.
Dans ces cas, l’apport de données, éventuellement issues de l’outil symbolique, permet ensuite un couplage avec des approches probabilistes et avec appren- tissage. Ainsi, le Prolog maison utilisé par FRMG a aussi été couplé avec une librairie de réseaux de neurones (DyNet), permettant de combiner raisonnement logique et apprentissage/inférence neuronal(e).
D’autres situations justifieraient une telle démarche d’hybridation itérative comme dans certains domaines de suivis thérapeutiques où il existe peu de données et le corps médical s’appuie sur des règles de consensus. La mise en œuvre de ces règles correspond bien à une modélisation symbolique qui peut alors contribuer à la génération de données exploitables par de « classiques » réseaux de neurones permettant ainsi de valider l’efficacité des règles initiales, de remettre en question, de valider ces règles voire d’en créer de nouvelles.
De manière plus systématique, divers travaux cherchent à formaliser et implanter le couplage de la logique avec probabilités et apprentissage. On peut ainsi citer les travaux de Pedro Domingos sur Markov Logic, qui associent la logique du premier ordre avec une démarche probabiliste, implantés en Open Source dans Alchemy http://alchemy.cs.washington.edu/ et illustrés dans son ouvrage The Master Algorithm : How the Quest for the Ulti- mate Learning Machine Will Remake Our World.
Néanmoins, il est également intéressant d’observer que le symbolique n’est pas nécessairement une surcouche de réseaux neuronaux. Ainsi, il existe de nombreuses bases de connaissances symboliques (bases de données, ontologies, réseaux sémantiques...) en général exprimables sous forme de graphes (Resource Description Framework par exemple). Divers travaux cherchent à s’appuyer sur des réseaux neuronaux pour exploiter de telles ressources symboliques.
Cela passe par exemple par de nouvelles architectures neuronales comme les Graph Convolution Networks et les Multihop Attention Networks... permettant le plongement des nœuds dans des espaces multidimensionnels (embeddings), des promenades au sein des graphes ou des rebonds d’information à information.
Enfin, les approches les plus ambitieuses seraient de faire émerger les concepts au sein des réseaux neuronaux sous des formes identifiables et manipulables via du raisonnement. Cela contribuerait à fournir une meilleure explicabilité de ces réseaux mais aussi un point de départ pour ensuite travailler sur ces représentations symboliques comme le font les humains. Un faisceau d’indices comme l’hypothèse du ticket de loterie (Frankle & Carbin 2019) tend en effet à suggérer que les modèles neuronaux actuels avec leurs gigantesques quantités de paramètres (jusqu’à mille milliards de paramètres) cachent en leur sein des modèles beaucoup plus petits et quasiment aussi bons.
Cette capacité à généraliser tout en compressant l’information est peut-être une voie vers des réseaux plus conceptuels. Notons aussi les approches cherchant à instaurer des structures dehiérarchie au sein des réseaux, telles les capsules neural network de Hitton : une capsule étant un groupe réduit de neurones permettant la détection d’un certain élément (comme un œil ou un nez) et l’activation d’autres capsules à un niveau hiérarchique plus élevé (par exemple pour vérifier des contraintes topologiques entre nez et yeux).
Perspectives
La voie qui consiste à ingérer d’immenses volumes de documents ou à manipuler simultanément d’importants de jeux de paramètres (à l’image de GPT-3 ou de Switch-C) est particulière- ment impressionnante car ces réseaux parviennent à un niveau de mimétisme humain particulièrement performant, sur un domaine donné. Mais elle exige une importante puissance de calcul brute (dans sa phase d'apprentissage). Parallèlement, il existe des gisements de connaissances symboliques sous-utilisées qui pourraient être mieux exploitées afin d’optimiser les phases d’apprentissages ou de bénéficier de leur pouvoir d’explication.Simultanément, il existe de nombreuses situations concrètes où l’expertise humaine est plus aisée à représenter avant de l’enrichir par des modèles probabilistes ou connexionnistes afin de passer d’un modèle discret à un monde continu, ou plus proche de la réalité du monde. Réconcilier les deux intelligences artificielles pourrait aussi faciliter l’explicabilité des algorithmes et, partant, améliorer leur appropriation par les utilisateurs.
Dans son ouvrage, Pedro Domingos suggère d’ailleurs que la clé d’un système « intelligent » se construit sans doute à l’intersection de plusieurs approches (connexionniste, symbolique, bayésienne, etc.).
Les fondateurs de l’intelligence artificielle avaient conjecturé en 1956 que tout aspect de l’apprentissage (ou autre caractéristique de l’intelligence) pourrait peu à peu être décrit assez précisément pour qu’une machine puisse le simuler. L’approche était résolument pragmatique, guidée par une ingénierie logicielle, et les critiques (telles celles formulées par Dreyfus, Winograd ou encore Varela, souvent inspirées des thèses de la phénoménologie husserlienne), ont été suspendues au profit de l’expérimentation. Mais rien n’empêche, à l’heure de nouvelles faisabilités techniques et de meilleures articulations transdisciplinaires, de faire retour sur le projet initial pour en élargir les considérations théoriques.
Pour aller plus loin
Les références bibliographiques sont classées par ordre de dates décroissantes. Cette liste, non exhaustive, confirme le foisonnement d’idées et d’approches pour tenter d’associer connexionnisme et symbolique. La voie est toujours ouverte...
Honghua Dong, Jiayuan Mao, Tian Lin, Chong Wang, Lihong Li, Denny Zhou, Neural Logic Machines, 2019, https://openreview.net/pdf ?id=B1xY-hRctX
Richard Evans, Ed Grefenstette, Differentiable Inductive Logic Programming, 2018,
https://uclnlp.github.io/nampi/talk_slides/evans-nampi-v2.pdf
Chunyang Xiao, Neural-Symbolic Learning for Semantic Parsing, thèse de 2017.
Pedro Domingos, The Master Algorithm : How the Quest for the Ultimate Learning Machine Will Remake Our World, 2015, Basic Books (pages 246 et suivantes).
Alex Graves, Greg Wayne, Ivo Danihelka, Neural Turing Machine, 2014 https://arxiv.org/pdf/1410.5401.pdf
Fernando Santos Osório, INSS un système hybride neuro-symbolique pour l’apprentissage automatique constructif, Thèse de 1998.
René Natowicz, Apprentissage symbolique automatique en reconnaissance d'images, 1987.
Cet article est extrait du magazine ActuIA. Afin de ne rien manquer de l'actualité de l'intelligence artificielle, procurez vous ActuIA n°16, actuellement en kiosque et sur abonnement :