Ilia Sucholutsky et Matthias Schonlau, tous deux chercheurs au sein de l'University of Waterloo, au Canada, ont développé une nouvelle méthode visant à rendre le machine learning plus efficace, même avec des datasets limités. Ils ont en effet travaillé sur algorithme capable d'apprendre plusieurs concepts à partir d'une même image, et donc avec une image, ou même moins, par catégorie. Leurs travaux ont été publiés dans un article intitulé ‘Less Than One’-Shot Learning: Learning N Classes From M<N Samples et disponible sur arXiv.
La technique, appelée « less-than-one-shot learning », permet d'entraîner un modèle d'IA pour identifier avec précision plus d'objets que le nombre sur lequel il a été formé - un énorme changement par rapport au processus coûteux et chronophage qui nécessite actuellement des milliers d'exemples d'un objet pour une identification précise.
« Des modèles de machine learning et de deep learning plus efficaces signifient que l'IA peut apprendre plus rapidement, est potentiellement plus petite et est plus légère et plus facile à déployer », a déclaré Ilia Sucholutsky, doctorant à l'Université de Waterloo et auteur principal sur l'étude introduisant la méthode.« Ces améliorations débloqueront la possibilité d'utiliser le deep learning dans des contextes où nous ne pouvions auparavant pas, car il était tout simplement trop coûteux ou impossible de collecter plus de données. »
« Alors que les modèles de machine learning commencent à apparaître sur les appareils d'IoT et les téléphones, nous devons être en mesure de les former plus efficacement, et le ‘less-than-one-shot learning’ pourrait rendre cela possible », a déclaré Ilia Sucholutsky.

La technique du 'less-than-one-shot learning' s'appuie sur des travaux antérieurs que Sucholutsky et son superviseur, le professeur Matthias Schonlau, ont réalisé sur les soft labels et la data distillation. Dans leurs travaux, les chercheurs ont réussi à former un réseau de neurones pour classer les images manuscrites des 10 chiffres en utilisant seulement cinq 'exemples de soft label soigneusement conçus', ce qui est moins d'un exemple par chiffre. En appliquant leur technique au dataset MNIST et ils ont en effet obtenu 94% d'accuracy avec seulement 10 images (créées à partir des 60 000 images d'origine).
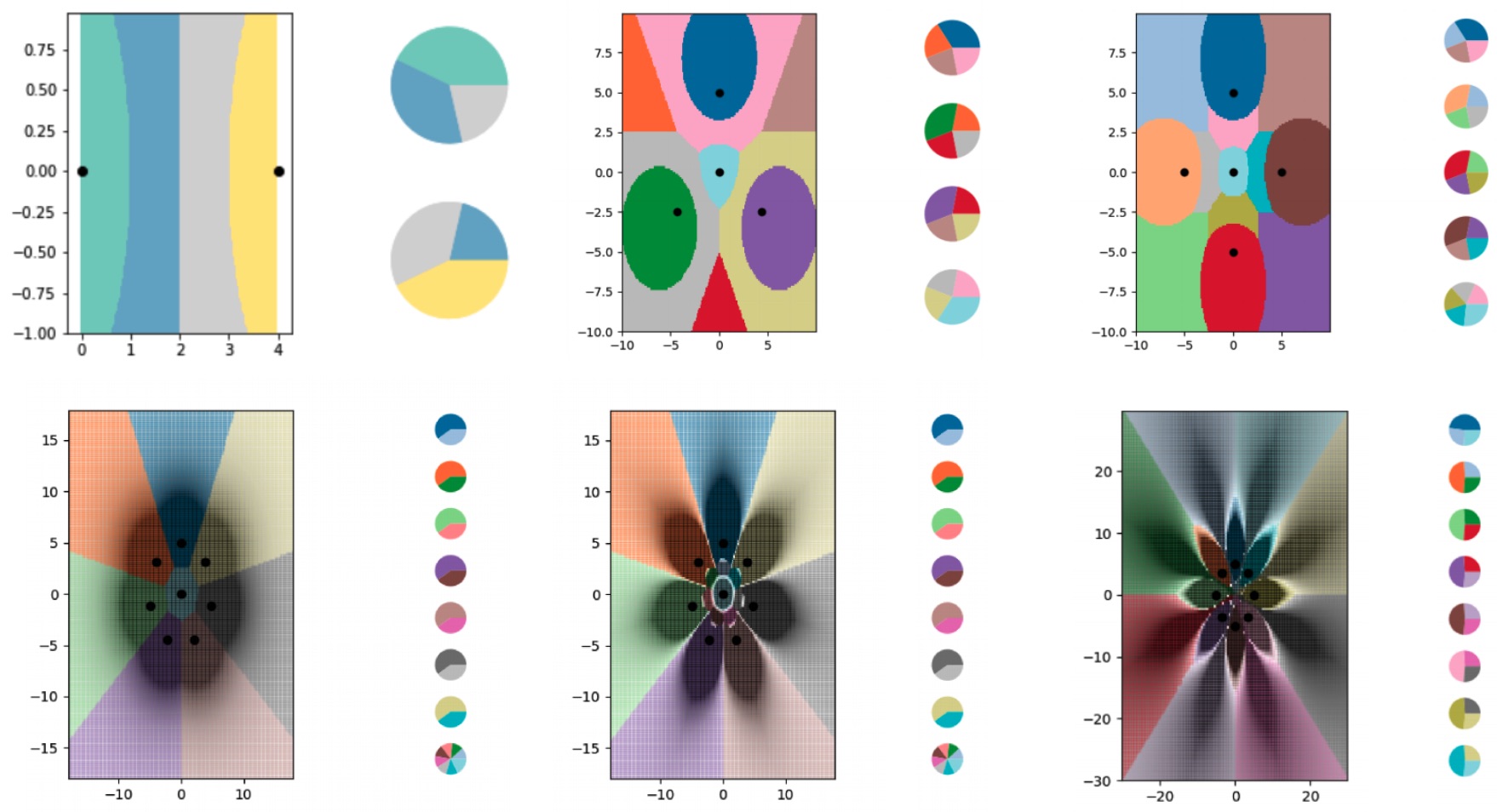
Pour développer cette nouvelle technique, les chercheurs ont utilisé l'algorithme de machine learning des « k-nearest neighbours » (k-NN), qui classe les données en fonction de l'élément auquel elles sont le plus similaires. Ils ont utilisé k-NN parce que cela rend l'analyse plus facile à gérer, mais « le less-than-one-shot learning » peut être utilisé avec n'importe quel algorithme de classification.
En utilisant des « k-nearest neighbours », les chercheurs montrent qu'il est possible pour les modèles de machine learning d'apprendre à discerner des objets même lorsqu'il n'y a pas assez de données pour certaines classes. En théorie, cela peut fonctionner pour n'importe quelle tâche de classification.
« Quelque chose qui paraissait absolument impossible au départ s'est avéré possible », a déclaré Matthias Schonlau, de l'Université de Waterloo. « C'est absolument stupéfiant car un modèle peut apprendre plus de classes que vous n'en avez d'exemples, et c'est grâce au soft label. Donc, maintenant que nous avons montré que c'était possible, le travail peut commencer pour déterminer toutes les applications. »Un article détaillant la nouvelle technique, ‘Less Than One’-Shot Learning: Learning N Classes From M<N Samples rédigé par les chercheurs de la Faculté de mathématiques de Waterloo, Ilia Sucholutsky et Matthias Schonlau, est en cours d'examen lors de l'une des principales conférences sur l'IA.