Des chercheurs d'Amazon, deux professeurs du Computer Science de l'Université de Californie se sont associés au chef scientifique de Meta pour mener une étude sur l'apprentissage automatique et ont présenté, dans ce cadre, un framework d'apprentissage intégré tolérant au bruit de bout en bout : PGE. Ce dernier leur a permis de tirer parti à la fois des informations textuelles et de la structure graphique des graphes de connaissance de produits (PG) et importer des intégrations pour la détection d'erreurs. Les tests effectués ont démontré l'efficacité de PGE. L'étude intitulée : « Robust Product Graph Embedding Learning for Error Detection » a été publiée sur Amazon Science.
Xian Li, Yifan Ethan Xu, chercheurs chez Amazon, Xin Luna Dong, chef scientifique de Meta, Yizhou Sun et Kewei Cheng, professeurs à l'UCLA sont les auteurs de cette étude.
De plus en plus de clients potentiels se tournent vers les sites de commerce électronique tels qu'Amazon, eBay, Cdiscount pour leurs achats, la pandémie a d'ailleurs amplifié cette démarche. Ces sites de vente ont, de leur côté, d'avantage recours à des graphiques de connaissance des produits (PG) pour améliorer la recherche de produits et fournir des recommandations.
Les graphes de connaissance de produits
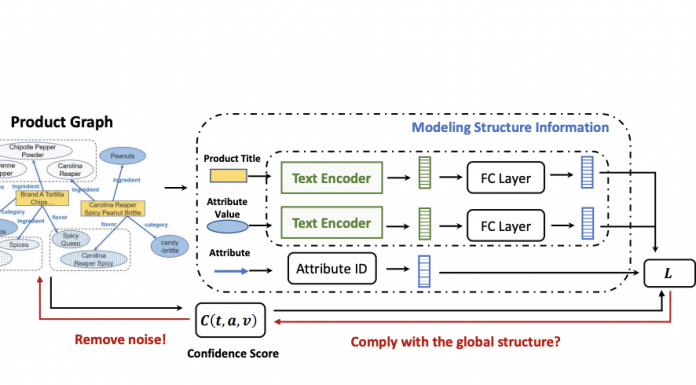
Un PG est un graphe de connaissances (KG) qui décrit les valeurs d'attributs du produit et est construit à partir des données du catalogue de produits. Dans un PG, chaque produit est associé à plusieurs attributs tels que la marque du produit, la catégorie du produit et d'autres informations liées aux propriétés du produit telles que la saveur et l'ingrédient. Différent des KG traditionnels, où la plupart des triplets sont présentés sous la forme de (entité de tête, relation, entité de queue), la majorité des triplets dans un PG ont la forme de (produit, attribut, valeur d'attribut), où la valeur de l'attribut est un texte court par exemple : « Brand A Tortilla Chips Spicy Queso, 6 – 2 oz bags », saveur, « Spicy Queso ». Les triplets d'attributs sont un type de triplets.Les détaillants fournissent les données du produit et celles-ci contiennent inévitablement de nombreux types d'erreurs, y compris contradictoires, erronées ou ambiguës. Lorsque de telles erreurs sont ingérées par un PG, elles conduisent à de mauvaises performances. La validation manuelle étant impossible dans un PG en raison d'un grand nombre de produits, une méthode de validation automatique s'est avérée nécessaire.
Les méthodes d'intégration de graphes de connaissances (KGE) sont pertinentes dans l'apprentissage de représentations efficaces pour les données de graphes multi-relationnels et ont montré des performances prometteuses dans la détection d'erreurs (c'est-à-dire déterminer si un triplet est correct ou non) en KG. Malheureusement, pour les KG existants, les méthodes d'intégration ne peuvent pas être directement utilisées pour détecter des erreurs dans un PG en raison de la richesse des informations textuelles et du bruit.
Le Product Graph Embedding (PGE) mis au point par l'équipe
L'équipe devait donc répondre à cette question de recherche difficile : « comment générer des incorporations pour un graphe de connaissances riche en texte et sujet aux erreurs afin de faciliter la détection d'erreur? ». Elle présente le nouveau cadre d'apprentissage intégré, « Product Graph Embedding » robuste, pour apprendre des incorporations efficaces pour de tels graphes de connaissances. Pour ce framework, les chercheurs ont procédé en deux étapes :- Les intégrations ont combiné de manière transparente les signaux provenant des informations textuelles des triplets d'attributs et les informations structurelles dans le graphe de connaissances. Les chercheurs ont appliqué un encodeur CNN pour apprendre les représentations textuelles pour les titres de produits et les valeurs d'attributs, puis les ont intégrées dans la structure du triplet pour capturer les modèles sous-jacents dans le graphe de connaissances.
- dans un second temps, les chercheurs ont intégré une fonction de perte sensible au bruit pour empêcher les triplets bruyants dans le PG de fausser les intégrations pendant la formation.
Sources de l'article : https://assets.amazon.science/51/23/25540bf446749098496f5d28e189/pge-robust-product-graph-embedding-learning-for-error-detection.pdf.