C'est sous la licence MIT, l'une des licences open source les plus permissives, que DeepSeek, acteur chinois de la GenAI, a publié ce jeudi 26 décembre la dernière version de son modèle éponyme. L'annonce de DeepSeek-V3 a d'autant plus suscité l'attention que les performances du modèle seraient comparables, voire supérieures à celles de principaux modèles à source fermée, comme GPT-4o ou Claude 3.5 Sonnet, et ce, malgré un coût d'entraînement drastiquement réduit.
Alors que la guerre technologique autour de l'IA entre les Etats-Unis et la Chine continue de s'intensifier avec l'annonce il y a moins d'un mois de nouvelles restrictions, DeepSeek démontre qu'il est néanmoins possible de développer des LLMs capables de rivaliser avec les meilleurs modèles américains.
Créée en mai 2023 à Hangzhou, la start-up, dirigée par Liang Wenfeng, est une filiale du fonds spéculatif High-Flyer. Son ambition est la même que celle affichée par OpenAI : développer une IA au service de l'humanité et atteindre l'IAG, des systèmes d'IA qui dépassent les capacités cognitives des êtres humains dans de nombreux domaines.
Tout juste un an plus tard, l'entreprise lançait DeepSeek-V2, un modèle de langage performant proposé à un coût compétitif, déclenchant une guerre des prix sur le marché chinois de l'IA et amenant ses principaux concurrents notamment Zhipu AI, ByteDance, Alibaba, Baidu, Tencent à revoir leurs prix à la baisse.
La semaine dernière, elle a présenté son successeur, DeepSeek-V3, comptant 671 milliards de paramètres, entraîné durant un peu moins de deux mois grâce aux GPU H 800 que les USA autorisaient NVIDIA à lui vendre jusqu'à l'an passé. Un total de 2 788 000 heures estimé à un coût de 5 576 000$, bien loin de celui des LLMs massifs de pointe comme LLama 3 405B qui a nécessité 30,8 millions d'heures GPU plus performants.
DeepSeek-V3
DeepSeek-V3 a été pré-entraîné sur un ensemble de données massif de 14 800 milliards de tokens, suivi d'étapes de réglage fin supervisé et d'apprentissage par renforcement pour exploiter pleinement ses capacités.Il s'appuie sur l'architecture Mixture-of-Experts développée pour son prédécesseur, DeepSeekMoE, composée comme son nom l'indique, de divers experts spécialisés. Ces derniers sont activés selon les besoins spécifiques des requêtes grâce à un mécanisme de routage intelligent, ce qui permet au modèle de gérer efficacement une variété de tâches tout en réduisant la charge computationnelle.
Il adopte également son architecture innovante Multi-head Latent Attention (Attention Latente Multi-têtes ou MLA), une approche qui permet de compresser de manière conjointe les clés et les valeurs d'attention, diminuant ainsi la taille du cache Key-Value (KV) pendant l'inférence. Elle réduit l’utilisation de la mémoire à 5-13 % de celle requise par l’architecture MHA couramment utilisée, améliorant l'efficacité du traitement tout en maintenant une performance élevée.
Pour assurer une répartition équilibrée de la charge entre les experts, DeepSeek-V3 intègre une stratégie de load balancing sans perte auxiliaire. Cette méthode garantit une utilisation optimale des ressources sans compromettre la performance du modèle.
Ce dernier hérite également des capacités avancées de raisonnement de la série DeepSeek R1, qui reposent comme OpenAI o1 et le modèle o3, sur la chaîne de pensée (chain of thought), ce qui lui permet d'exceller dans les tâches complexes nécessitant un raisonnement structuré.
Les performances du modèle
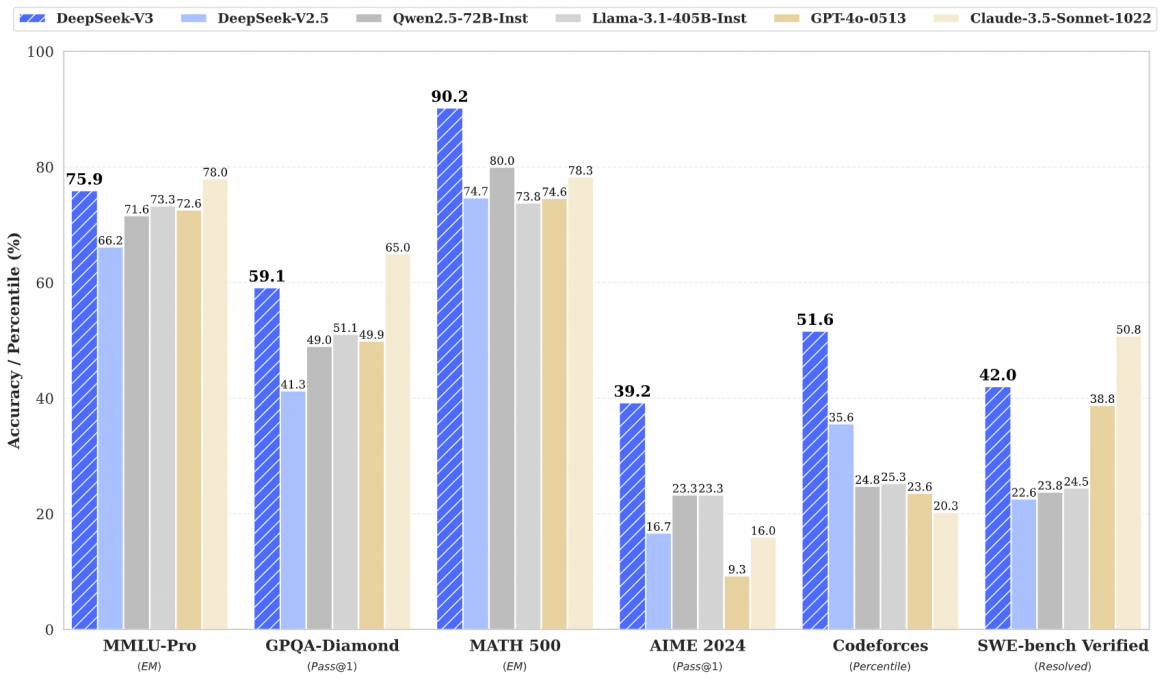
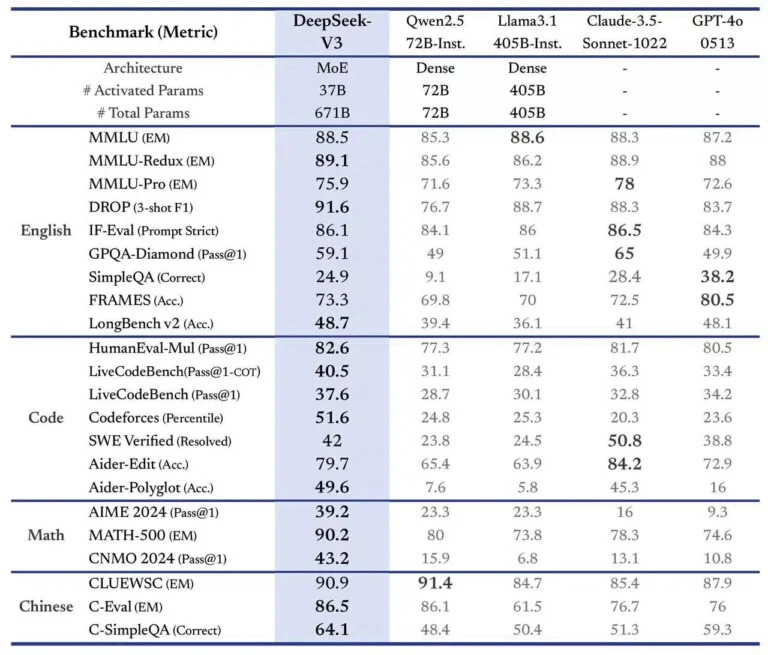
DeepSeek-V3 est trois fois plus rapide que son prédécesseur, avec une capacité de traitement de 60 tokens par seconde. Selon les benchmarks partagés par la start-up, il se classe en tête des modèles open source et rivalise avec les modèles propriétaires les plus avancés dans divers domaines, notamment la compréhension linguistique, le raisonnement mathématique et la génération de code. Il obtient non seulement le meilleur score (51,6) sur Codeforces, mais est également avec 90,2 % clairement en tête du benchmark de MATH-500 surpassant Llama 3.1 (73,8 %), Claude-3.5 (78,3 %) et GPT-4o (74,6 %).
Comme tous les LLMs chinois, le modèle a reçu une approbation officielle avant son lancement, garantissant son adéquation aux valeurs socialistes et à l'idéologie chinoises. Il évite donc certains sujets sensibles.
Une interface intuitive, similaire à celle de ChatGPT, incluant un moteur de recherche en temps réel, permet d'interagir avec le modèle sur le site de DeepSeek. Pour les entreprises, la start-up propose une API à des tarifs très compétitifs : 0,27 $ par million de tokens en entrée, 1,10 $ par million de tokens en sortie.
Le modèle est téléchargeable sur Hugging Face. Le code complet ainsi qu'une documentation technique détaillée sont quant à eux disponibles sur GitHub.