
L'apprentissage par renforcement profond (deep RL), combinaison de RL et de deep learning, est une approche courante pour l'apprentissage des robots dans des environnements simulés. Des chercheurs de l'Université de Californie à Berkeley ont tiré parti des développements récents du modèle du monde « Dreamer » et utilisé le renforcement en ligne dans le monde réel pour former des robots sans simulateur ni démonstration. Leur étude intitulée « DayDreamer : World Models for Physical Robot Learning » a été publiée dans ArXiv.
Entraîner une IA dans un environnement virtuel est une approche beaucoup plus simple que dans le monde réel, elle permet des économies d'argent, de temps, d'éviter la casse des prototypes... Mais le passage de la simulation au monde réel est perçu comme très difficile car la modélisation d'un environnement virtuel ne peut être parfaitement fidèle à la réalité de notre monde physique.
Le modèle du monde Dreamer
Danijar Hafner, Timothy Lillicrap, Jimmy Ba et Mohammad Norouzi avaient présenté l'algorithme « Dreamer » à ICLR 2020. Cet agent RL est capable de planifier les actions futures à partir de celles effectuées via l'imagination latente. Récemment, l'algorithme a surpassé l'apprentissage par renforcement pur dans les jeux vidéo à partir de brèves interactions dans un modèle mondial. Des chercheurs de l'UC Berkeley ont voulu savoir si Dreamer pouvait faciliter un apprentissage plus rapide sur des robots physiques.Un apprentissage sans simulateur
Danijar Hafner, qui avait présenté Dreamer en 2020, fait également partie de l'équipe de l'UC Berkeley. Doctorant en IA à Toronto, il est pour l'instant au laboratoire de Pieter Abbeel, autre membre de l'équipe ainsi que Philipp Wu, Alejandro Escontrela et Ken Goldberg. L'étude utilise les développements récents du modèle du monde Dreamer pour former une gamme de robots grâce à l'apprentissage par renforcement en ligne dans le monde réel, sans simulateur ou démonstration.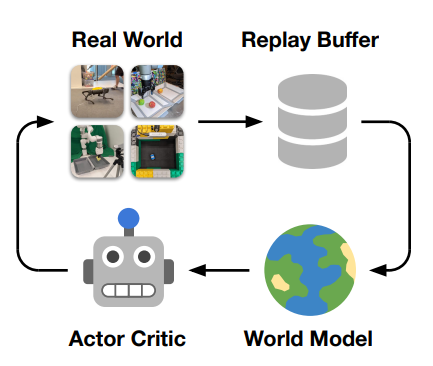 La figure ci-dessus illustre la façon dont Dreamer construit un modèle du monde à partir d'un tampon de relecture d'expériences antérieures, apprend des comportements à partir de déploiements imaginés dans l'espace latent du modèle du monde et interagit en permanence avec l'environnement pour explorer et affiner ses comportements.
La figure ci-dessus illustre la façon dont Dreamer construit un modèle du monde à partir d'un tampon de relecture d'expériences antérieures, apprend des comportements à partir de déploiements imaginés dans l'espace latent du modèle du monde et interagit en permanence avec l'environnement pour explorer et affiner ses comportements.
L'objectif de l'équipe est de repousser les limites de l'apprentissage des robots dans le monde réel et de fournir une plateforme robuste pour de futures recherches qui démontreront les avantages des modèles mondiaux pour cet apprentissage.
Les chercheurs ont appliqué Dreamer à 4 robots, démontrant qu'un apprentissage dans le monde réel était possible sans introduire de nouveaux algorithmes. Les tâches étaient variées, se déroulaient dans différents espaces d'action, modalités sensorielles et structures de récompense :
- Ils ont ainsi entraîné un quadrupède à rouler sur le dos, se lever et marcher en seulement une heure.. Ils ont ensuite poussé le robot et ont pu constater que Dreamer s’adapte dans les 10 minutes pour résister ou se retourner rapidement et se relever.

- Visual Pick and Place (ci-dessus) : Sur deux bras robotiques différents, Dreamer apprend à choisir et à placer plusieurs objets directement à partir d’images de caméra et de récompenses éparses, approchant ainsi la performance humaine.
- Sur un robot à roues, Dreamer apprend à naviguer vers un objectif uniquement à partir d’images de caméra, résolvant automatiquement l’ambiguïté sur l’orientation du robot.
Les chercheurs publient en open source l'infrastructure logicielle pour toutes leurs expériences, ce qui prend en charge différents espaces d'action et modalités sensorielles, offrant une plate-forme flexible pour l'avenir de la recherche de modèles du monde pour l'apprentissage des robots dans le monde réel.
Sources de l'article :
DayDreamer: World Models for Physical Robot Learning
Philipp Wu, Alejandro Escontrela, Danijar Hafner, Ken Goldberg, Pieter Abbeel.