Mistral AI ne chôme pas : après avoir dévoilé lundi dernier deux nouveaux LLM open source Codestral Mamba 7B et Mathstral 7B, il a annoncé, le vendredi suivant, Mistral NeMo 12 B, développé avec NVIDIA. Combinant l’expertise de Mistral AI en matière de données d’entraînement avec l’écosystème matériel et logiciel optimisé de NVIDIA, le modèle, également sous licence Apache 2.0, offre des performances élevées pour diverses applications, grâce à sa flexibilité.
Publié le lendemain de GPT-4o mini d'Open AI, Mistral NeMo 12B dispose lui aussi d'une fenêtre contextuelle allant jusqu’à 128 000 jetons et est également adapté pour les entreprises qui cherchent à implémenter des solutions d’IA sans avoir besoin de ressources cloud étendues.
Une collaboration Mistral AI - NVIDIA
NVIDIA a participé à la dernière levée de fonds de 600 millions d'euros de Mistral AI, ouvrant la voie à cette collaboration pour le développement de ce nouveau modèle.S'appuyant sur une architecture transformateur standard, Mistral NeMo a été entraîné sur la plateforme d’IA NVIDIA DGX Cloud, qui offre un accès dédié et évolutif à la dernière architecture NVIDIA. NVIDIA NeMo, un framework cloud-native permettant aux développeurs de construire, personnaliser et déployer des modèles d’IA générative a été utilisé pour faire progresser et optimiser le processus ainsi que NVIDIA TensorRT-LLM, un conteneur NVIDIA NIM prédéfini qui permet aux développeurs de réduire les temps de déploiement de plusieurs semaines à quelques minutes.
Le modèle utilise le format de données FP8 pour l’inférence du modèle, ce qui réduit la taille de la mémoire et accélère le déploiement sans aucune dégradation de la précision.
S'il est publié sous licence Apache 2.0, facilitant l'adoption par la communauté de recherche et permettant aux entreprises d’intégrer Mistral NeMo dans des applications commerciales de manière transparente, il est fourni par NVIDIA sous la forme d'un microservice d'inférence NIM de la plateforme NVIDIA AI Enterprise 5.0 introduite en mars dernier lors de la GTC 2024.
Guillaume Lample, cofondateur et scientifique en chef de Mistral AI, commente :
"Nous avons la chance de collaborer avec l’équipe NVIDIA, en tirant parti de leur matériel et de leurs logiciels de premier plan. Ensemble, nous avons développé un modèle offrant une précision, une flexibilité, une efficacité élevées ainsi qu'un support et une sécurité de niveau entreprise sans précédent grâce au déploiement de NVIDIA AI Enterprise".
Performances de pointe dans sa catégorie
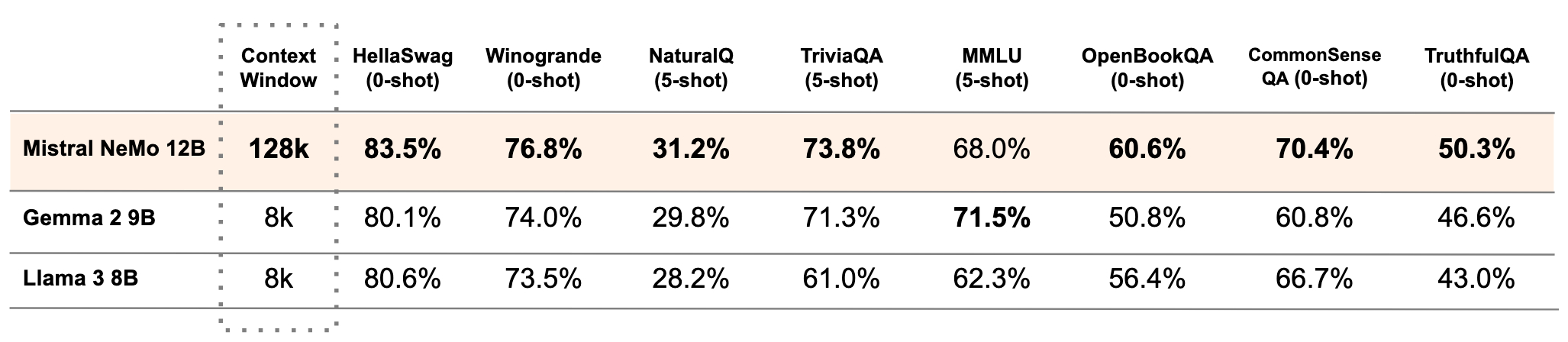
Mistral NeMo se distingue par son raisonnement avancé, sa connaissance approfondie du monde et sa précision en codage. Grâce à son architecture standard, il est facile à intégrer et peut remplacer directement les systèmes utilisant le modèle Mistral 7B, assurant ainsi une transition en douceur pour les utilisateurs existants.Il est conçu pour des applications telles que les chatbots, les tâches multilingues, le codage et la synthèse de document.
Selon les tests comparatifs de Mistral AI, il surpasse les performances de deux modèles open-source récents, Gemma 2 9B et Llama 3 8B.