
Microsoft a récemment publié BitNet.cpp, un cadre open-source conçu pour optimiser l’inférence des grands modèles de langage (LLM) quantifiés à 1 bit. Il permet notamment d'exécuter un modèle BitNet b1.58 de 100 milliards de paramètres sur un seul processeur, atteignant des vitesses de traitement comparables à la lecture humaine, à une cadence de 5-7 jetons par seconde, démocratisant ainsi l'accès aux LLM les plus avancés.
La taille croissante des LLM pose des défis pour leur déploiement et soulève des inquiétudes quant à leur impact environnemental et économique, principalement en raison de leur forte consommation d'énergie.
Les avantages de la quantification
Une des approches pour répondre à ces défis consiste à utiliser la quantification post-entraînement, qui vise à créer des modèles à faible précision pour l'inférence. Cette technique réduit la précision des poids et des activations, diminuant ainsi considérablement les besoins en mémoire et en ressources de calcul des LLMs.BitNet.cpp s'appuie sur les travaux de Microsoft sur les architectures de modèles quantifiés 1 bit, notamment BitNet, et la variante LLM à 1 bit, BitNet b1.58, introduite en février dernier, dans laquelle chaque paramètre (ou poids) du LLM est ternaire {-1, 0, 1}
Contrairement aux LLMs traditionnels qui utilisent des valeurs en virgule flottante 16 bits (FP16 ou BF16) pour les opérations de multiplication de matrices, BitNet n'utilise que des additions entières, ce qui permet une économie d'énergie significative tout en maintenant les caractéristiques essentielles du modèle.
Outre le calcul, le transfert des paramètres du modèle entre la mémoire DRAM et celle d’un accélérateur sur puce (comme la SRAM) peut être coûteux. Les tentatives d'agrandissement de la SRAM pour améliorer le débit entraînent en effet des coûts élevés. En revanche, les modèles 1 bit comme ceux de BitNet ont une empreinte mémoire beaucoup plus faible, ce qui réduit à la fois le coût et le temps de chargement des poids depuis la DRAM, accélérant ainsi l’inférence.
La précision de 1,58 bits dans le système binaire conserve tous les avantages de BitNet 1 bit tout en ajoutant des capacités de filtrage de caractéristiques, grâce à l'inclusion de la valeur 0 dans les poids du modèle.
Le cadre d'inférence BitNet.cpp
Le cadre, qui gère l'exécution de ce modèle optimisé et des LLM 1 bit, offre une suite de noyaux optimisés qui prennent actuellement en charge l’inférence sans perte sur le CPU, avec des plans pour la prise en charge de NPU et GPU à l’avenir.Actuellement, bitnet.cpp prend en charge les processeurs ARM et x86. Les vitesses d'inférence sont de 1,37 et 5,07 fois plus rapides sur les processeurs ARM, et de 2,37 à 6,17 fois sur les processeurs x86, selon la taille du modèle.
Les gains énergétiques vont quant à eux de 55,4 % à 82,2 %, selon la configuration : 55,4 % à 70,0 % sur les processeurs ARM, et 71,9 % à 82,2 % sur les processeurs x86.
Les modèles testés ci-dessous sont des configurations factices utilisées pour illustrer les capacités du framework.
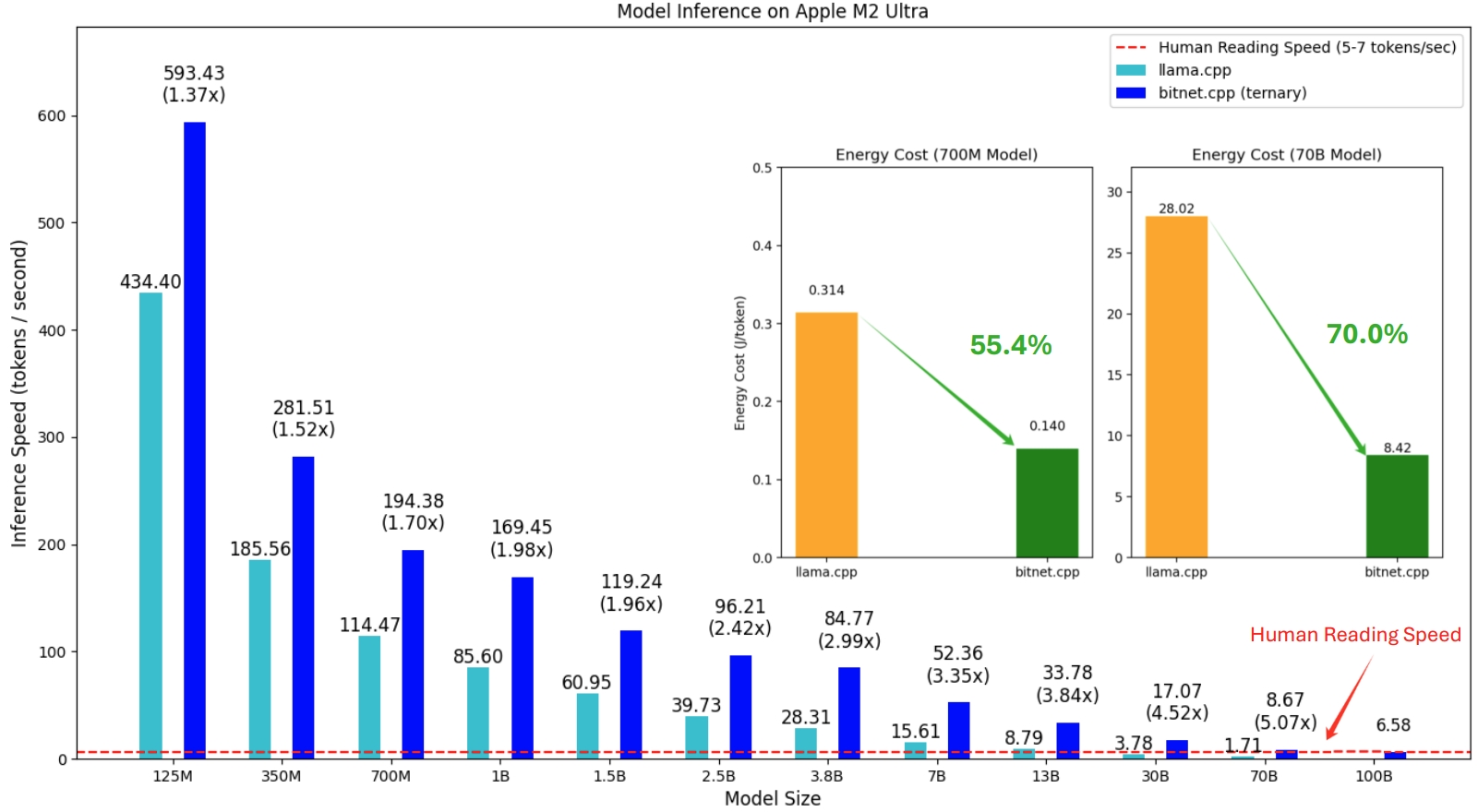
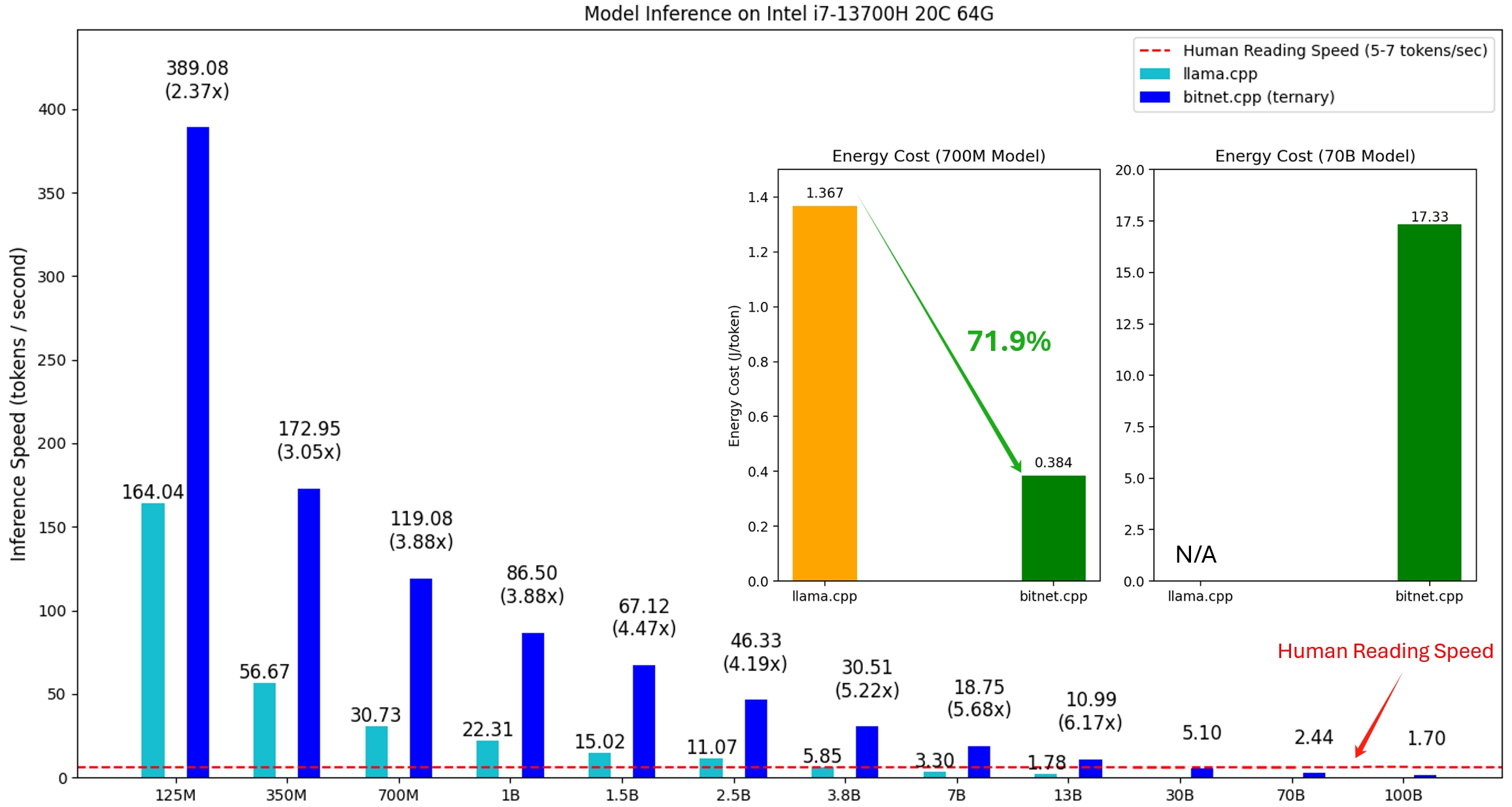
BitNet.cpp prend en charge une liste de modèles 1 bit disponibles sur Hugging Face, qui sont entraînés avec des paramètres de recherche.
En réduisant la dépendance à des infrastructures énergivores, BitNet.cpp peut contribuer à diminuer l'empreinte carbone des LLM et à améliorer leur adoption dans des environnements de calcul à faible coût, où la consommation énergétique est un facteur critique. Les développeurs, les petites et moyennes entreprises, qui n'ont pas toujours les moyens d'investir dans des solutions basées sur des GPU ou des serveurs cloud puissants, pourraient ainsi en bénéficier.
Au-delà de l’impact sur la consommation d’énergie, l’exécution locale des modèles via BitNet.cpp présente aussi des avantages sur le plan de la confidentialité des données, en évitant le recours à des infrastructures cloud pour le traitement de l’information.
Des instructions détaillées pour installer et configurer bitnet.cpp sur différents systèmes d’exploitation, y compris Windows et Debian/Ubuntu, sont disponibles sur GitHub.