
Amazon a récemment introduit BASE TTS (Big Adaptive Streamable TTS with Emergent capabilities), le plus grand modèle de synthèse vocale à ce jour, tant en termes de paramètres que de données d'entraînement. Entraîné sur 100 000 heures de données vocales du domaine public, il produit une parole naturelle et expressive à partir de textes bruts, en s’adaptant à la voix et au style du locuteur cible.
La synthèse vocale (TTS), qui consiste à produire de la parole à partir de textes, est une technologie clé pour de nombreuses applications, telles que les assistants virtuels, les livres audio, les systèmes de navigation... La qualité de la parole synthétique dépend de plusieurs facteurs, tels que la naturalité, l’expressivité, la fidélité au texte et à la voix cible, et la capacité à gérer plusieurs langues et domaines.
L'objectif des chercheurs d'Amazon était non seulement d’améliorer la qualité générale de la synthèse vocale mais également d’étudier comment la mise à l’échelle affecte la capacité du modèle à produire une prosodie (variations de ton, de rythme, d'accentuation et d'intonation) et une expression appropriées pour les entrées de texte difficiles, de la même manière que les LLM acquièrent de nouvelles capacités grâce à la mise à l’échelle des données et des paramètres, un phénomène connu sous le nom d'"émergence" ou de "capacités émergentes".
BASE TTS repose sur un gigantesque transformateur autorégressif d'un milliard de paramètres, entraîné sur un ensemble de données vocales publiques totalisant 100 000 heures. Cette ampleur de données et de paramètres permet à BASE TTS d'atteindre un nouvel état de l'art en termes de naturalité de la parole, dépassant de loin les performances des modèles précédents.
Le transformateur permet de convertir les textes bruts en codes discrets appelés "speechcodes", puis à les décoder de manière incrémentielle et diffusable en formes d'onde vocales. Ces speechcodes sont construits à l'aide d'une technique de tokenisation novatrice, qui comprend le désenchevêtrement et la compression de l'identifiant du locuteur avec un codage par paires d'octets. Cette approche permet à BASE TTS de capturer la richesse et la complexité de la parole humaine de manière efficace et précise.
Vue d’ensemble de BASE TTS. Le générateur de jetons vocaux (1) apprend une représentation discrète, qui est modélisée par un modèle autorégressif (2) conditionné par le texte et la parole de référence. Le décodeur speechcode (3) convertit les représentations vocales prédites en forme d’onde.
Jeu de données
Pour tester leur hypothèse selon laquelle les capacités émergent avec l'ampleur des données, ils ont constitué un ensemble de données de 100 000 heures de données vocales non étiquetées, principalement en anglais (plus de 90%), avec également des données en allemand, néerlandais et espagnol. Ces données, téléchargées depuis le Web, ont été reformatées en fichiers LPCM mono 24 kHz, sans traitement de signal supplémentaire pour tester la capacité du modèle à générer une parole claire à partir de données bruitées.Ils ont construit plusieurs variantes de BASE TTS : La plus petite, avec 1 000 heures de données et 150 millions de paramètres, une seconde avec 10 000 hrs de données et 150 millions de paramètres et enfin la plus grande avec 100 000 heures de données et 980 millions de paramètres.
Evaluations et performances
Les chercheurs ont évalué BASE TTS sur plusieurs critères, tels que la qualité subjective de la parole, la fidélité au texte et à la voix cible, la robustesse aux textes longs et complexes, et la capacité à gérer plusieurs langues et domaines.Ils ont construit un "test de capacités émergentes" en anglais avec 7 catégories de textes : Questions, Émotions, Noms composés, Complexités syntaxiques, Mots étrangers, Paralinguistique et Ponctuations. BASE-Medium a démontré des capacités émergentes que BASE-Large a confirmée.
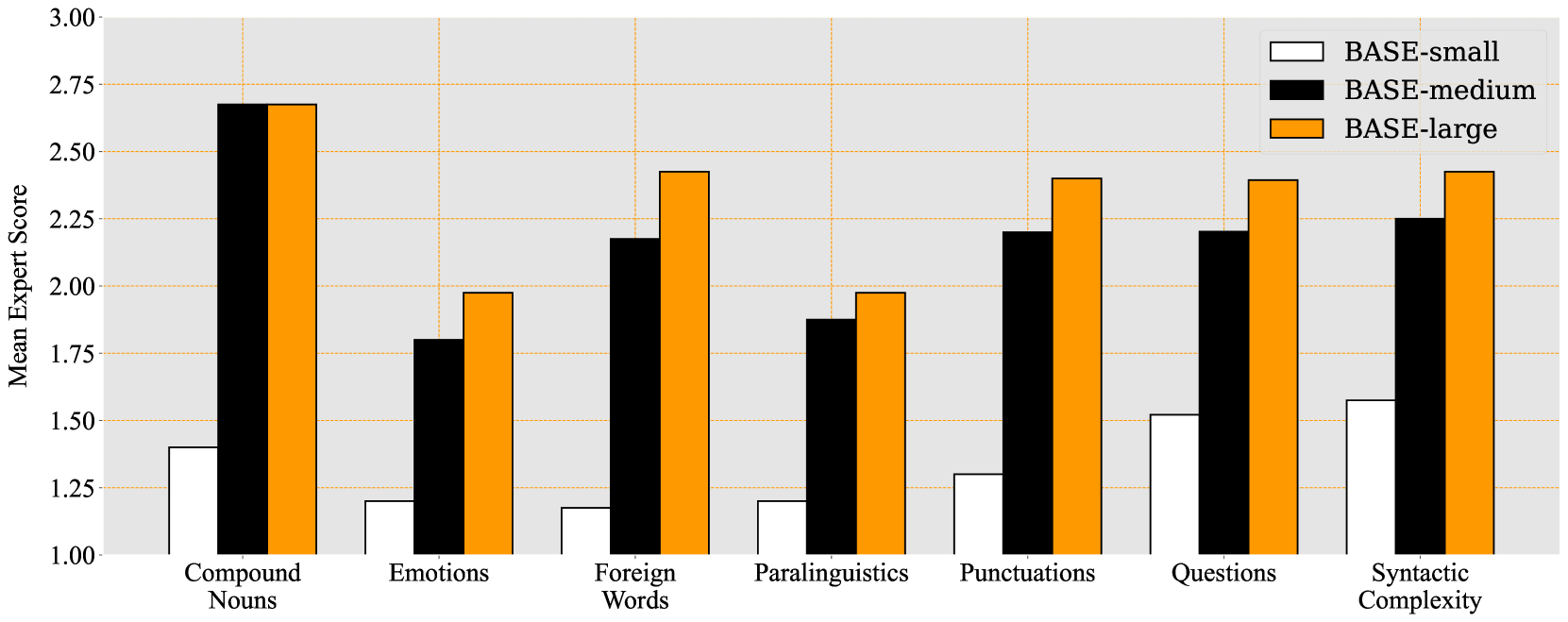
Évaluations d’experts linguistes par système : BASE TTS - petit/moyen/grand. Les résultats sont présentés pour les sept tâches proposées, en calculant la moyenne des notes d’experts sur 20 phrases dans chaque catégorie.
Ils ont également comparé BASE TTS à des systèmes de synthèse vocale de grande échelle déjà accessibles au public, notamment YourTTS Casanova, Bark et TortoiseTTS. Les résultats ont démontré la supériorité de BASE TTS en termes de naturalité et d'expressivité de la parole. Cependant, en raison de l’utilisation abusive potentielle de leur modèle, ils ont décidé de ne pas l'ouvrir par mesure de précaution.
Les audios générées par le modèle peuvent être retrouvées sur https://amazon-ltts-paper.com/.
Références de l'article :
"BASE TTS: Lessons from building a billion-parameter Text-to-Speech model on 100K hours of data" arXiv :2402.08093v1 [cs. LG] 12 févr. 2024
Auteurs :
Mateusz Łajszczak, Guillermo Cámbara, Yang Li, Fatih Beyhan, Arent van Korlaar, Fan Yang, Arnaud Joly, Álvaro Martín-Cortinas, Ammar Abbas, Adam Michalski, Alexis Moinet, Sri Karlapati, Ewa Muszyńska, Haohan Guo, Bartosz Putrycz, Soledad López Gambino, Kayeon Yoo, Elena Sokolova et Thomas Drugman.