
Après avoir publié en décembre dernier sa famille de modèles OLMO 2, l’Allen Institute for Artificial Intelligence (AI2) poursuit son engagement envers l'open source avec le lancement de Tülu 3 405B. Basé sur Llama 3.1, exploitant le cadre d’apprentissage par renforcement à partir de récompenses vérifiables (RLVR) d'AI2, ce nouveau modèle atteint des performances compétitives ou supérieures à celles de DeepSeek V3 (sur lequel est basé DeepSeek R1) et GPT-4o, surpassant également les modèles post-entraînés précédents de même taille, comme Llama 3.1 405B Instruct et Hermes 3 405B de Nous Research.
Un post entraînement optimisé
La recette de post-entraînement de Tülu 3 405B est similaire à celle de ses prédécesseurs, Tülu 3 8B et 70B, publés par AI2 en novembre dernier. Elle inclut la curation minutieuse des données, la mise au point supervisée (SFT), l'optimisation directe des préférences (DPO) ainsi que le Reinforcement Learning with Verifiable Rewards (RLVR).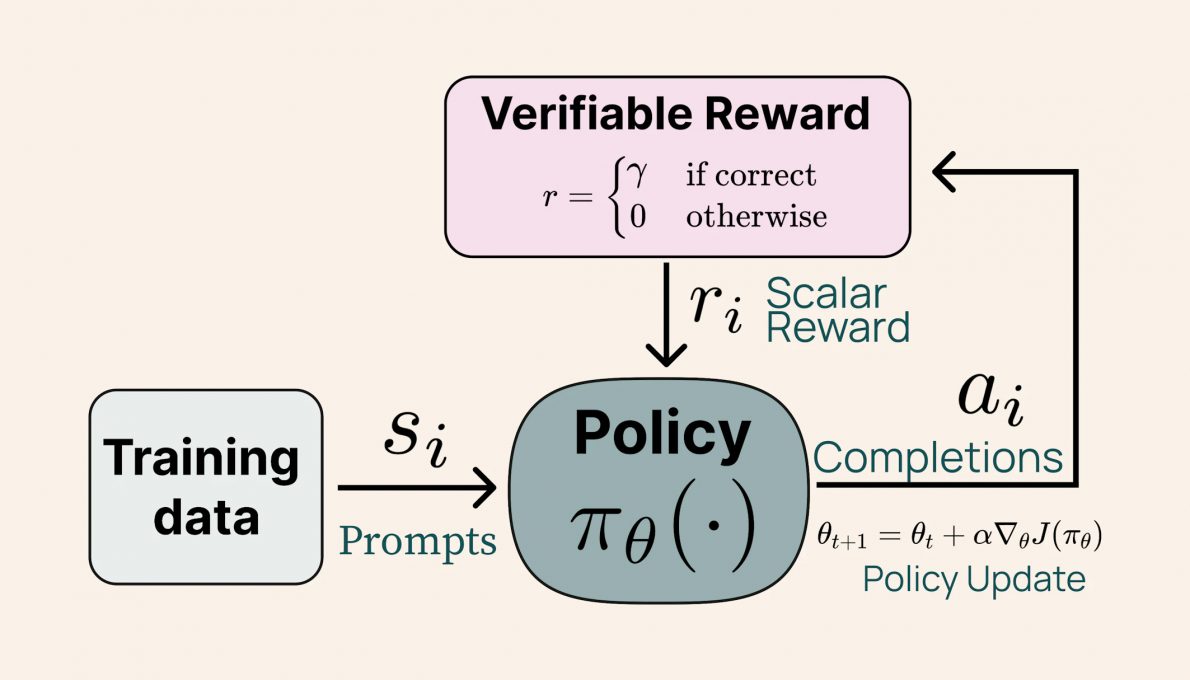
Crédit image AI. Schéma décrivant le processus d’apprentissage par renforcement avec récompenses vérifiables (RLVR).
Cette nouvelle méthode permet d’améliorer significativement les performances des modèles Tülu sur des tâches complexes comme la résolution de problèmes mathématiques et le suivi d'instructions. Fait intéressant, les résultats montrent que l’échelle du modèle influence positivement l’efficacité du RLVR : alors que les modèles plus petits bénéficient d’un entraînement sur des ensembles de données diversifiés, Tülu 3 405B obtient de meilleures performances en se concentrant sur des données plus spécialisées.
Performances du modèle
Selon les évaluations internes d'AI2, Tülu 3 405B surpasse DeepSeek V3, GPT-4o, et Llama 3.1 405B sur le benchmark PopQA, un ensemble de 14 000 paires de questions-réponses qui permet de vérifier l'efficacité des modèles dans la récupération et la génération d'informations précises. Le modèle a également obtenu les performances les plus élevées de tous les modèles de sa catégorie sur GSM8K, un ensemble de données composé d'environ 8 500 problèmes mathématiques de niveau scolaire créé par OpenAI, utilisé pour tester les capacités des modèles de langage à effectuer un raisonnement mathématique multi-étapes.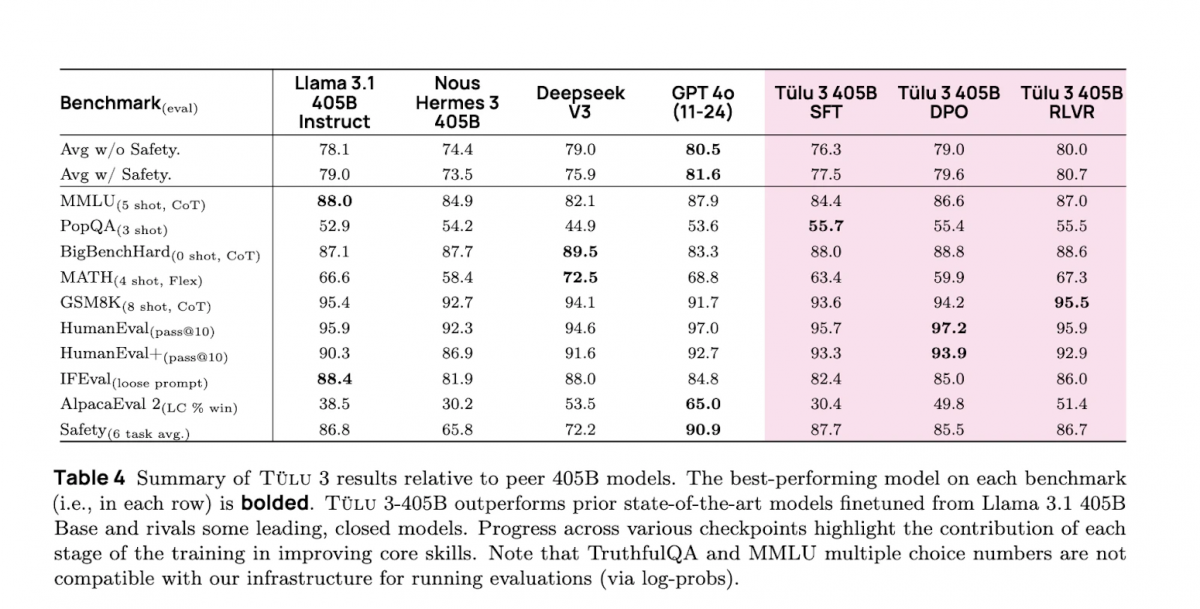
Enjeux techniques et défis d’implémentation
La mise à l'échelle du modèle n’a pas été sans défis. L'entraînement de Tülu 3 405B a nécessité une infrastructure considérable, avec 256 GPU déployés en parallèle. La gestion du parallélisme tensoriel et l’optimisation des hyperparamètres ont été des points clés, nécessitant un suivi rigoureux. L'’intégration de corrections pour la diffusion NCCL (NVIDIA Collective Communications Library, une bibliothèque open source qui permet de réduire les goulots d'étranglement liés aux échanges de données et améliore les performances globales du système) a cependant permis une synchronisation efficace des poids du modèle, réduisant ainsi les délais d’inférence et de mise à jour.Tülu 3 405B est un modèle véritablement ouvert, répondant aux critères stricts de l’OSAID, la définition de l’IA open source de l’OSI. Il peut être testé sur le site d’Ai2, est accessible sur Hugging Face et son code d'entraînement sur GitHub.
Hébergé sur Google Cloud, le modèle sera prochainement disponible sur Vertex AI.